 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Task-Adaptive Pretraining for Dialogue Response Selection
Paper and Code
Oct 08, 2022
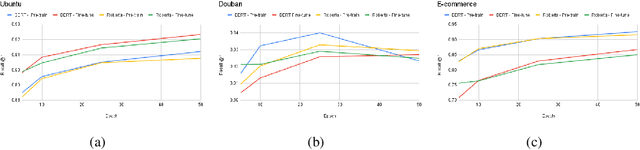
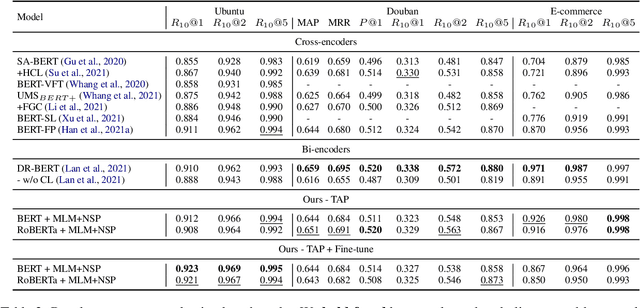
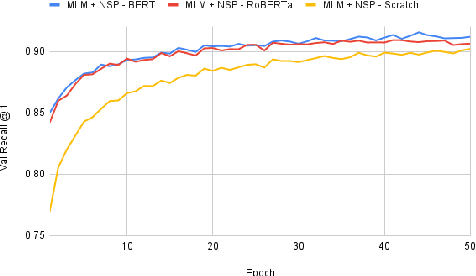
Recent advancements in dialogue response selection (DRS) are based on the \textit{task-adaptive pre-training (TAP)} approach, by first initializing their model with BERT~\cite{devlin-etal-2019-bert}, and adapt to dialogue data with dialogue-specific or fine-grained pre-training tasks. However, it is uncertain whether BERT is the best initialization choice, or whether the proposed dialogue-specific fine-grained learning tasks are actually better than MLM+NSP. This paper aims to verify assumptions made in previous works and understand the source of improvements for DRS. We show that initializing with RoBERTa achieve similar performance as BERT, and MLM+NSP can outperform all previously proposed TAP tasks, during which we also contribute a new state-of-the-art on the Ubuntu corpus. Additional analyses shows that the main source of improvements comes from the TAP step, and that the NSP task is crucial to DRS, different from common NLU tasks.