 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Variational Framework for Improving Naturalness in Generative Spoken Language Models
Jun 17, 2025



The success of large language models in text processing has inspired their adaptation to speech modeling. However, since speech is continuous and complex, it is often discretized for autoregressive modeling. Speech tokens derived from self-supervised models (known as semantic tokens) typically focus on the linguistic aspects of speech but neglect prosodic information. As a result, models trained on these tokens can generate speech with reduced naturalness. Existing approaches try to fix this by adding pitch features to the semantic tokens. However, pitch alone cannot fully represent the range of paralinguistic attributes, and selecting the right features requires careful hand-engineering. To overcome this, we propose an end-to-end variational approach that automatically learns to encode these continuous speech attributes to enhance the semantic tokens. Our approach eliminates the need for manual extraction and selection of paralinguistic features. Moreover, it produces preferred speech continuations according to human raters. Code, samples and models are available at https://github.com/b04901014/vae-gslm.
Exploring Prediction Targets in Masked Pre-Training for Speech Foundation Models
Sep 16, 2024



Speech foundation models, such as HuBERT and its variants, are pre-trained on large amounts of unlabeled speech for various downstream tasks. These models use a masked prediction objective, where the model learns to predict information about masked input segments from the unmasked context. The choice of prediction targets in this framework can influence performance on downstream tasks. For example, targets that encode prosody are beneficial for speaker-related tasks, while targets that encode phonetics are more suited for content-related tasks. Additionally, prediction targets can vary in the level of detail they encode; targets that encode fine-grained acoustic details are beneficial for denoising tasks, while targets that encode higher-level abstractions are more suited for content-related tasks. Despite the importance of prediction targets, the design choices that affect them have not been thoroughly studied. This work explores the design choices and their impact on downstream task performance. Our results indicate that the commonly used design choices for HuBERT can be suboptimal. We propose novel approaches to create more informative prediction targets and demonstrate their effectiveness through improvements across various downstream tasks.
Overview of Robust and Multilingual Automatic Evaluation Metrics for Open-Domain Dialogue Systems at DSTC 11 Track 4
Jun 22, 2023



The advent and fast development of neural networks have revolutionized the research on dialogue systems and subsequently have triggered various challenges regarding their automatic evaluation. Automatic evaluation of open-domain dialogue systems as an open challenge has been the center of the attention of many researchers. Despite the consistent efforts to improve automatic metrics' correlations with human evaluation, there have been very few attempts to assess their robustness over multiple domains and dimensions. Also, their focus is mainly on the English language. All of these challenges prompt the development of automatic evaluation metrics that are reliable in various domains, dimensions, and languages. This track in the 11th Dialogue System Technology Challenge (DSTC11) is part of the ongoing effort to promote robust and multilingual automatic evaluation metrics. This article describes the datasets and baselines provided to participants and discusses the submission and result details of the two proposed subtasks.
A Vector Quantized Approach for Text to Speech Synthesis on Real-World Spontaneous Speech
Feb 08, 2023Recent Text-to-Speech (TTS) systems trained on reading or acted corpora have achieved near human-level naturalness. The diversity of human speech, however, often goes beyond the coverage of these corpora. We believe the ability to handle such diversity is crucial for AI systems to achieve human-level communication. Our work explores the use of more abundant real-world data for building speech synthesizers. We train TTS systems using real-world speech from YouTube and podcasts. We observe the mismatch between training and inference alignments in mel-spectrogram based autoregressive models, leading to unintelligible synthesis, and demonstrate that learned discrete codes within multiple code groups effectively resolves this issue. We introduce our MQTTS system whose architecture is designed for multiple code generation and monotonic alignment, along with the use of a clean silence prompt to improve synthesis quality. We conduct ablation analyses to identify the efficacy of our methods. We show that MQTTS outperforms existing TTS systems in several objective and subjective measures.
A unified one-shot prosody and speaker conversion system with self-supervised discrete speech units
Nov 12, 2022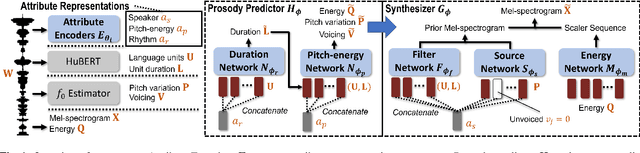
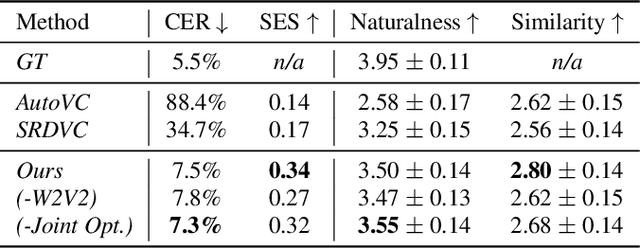

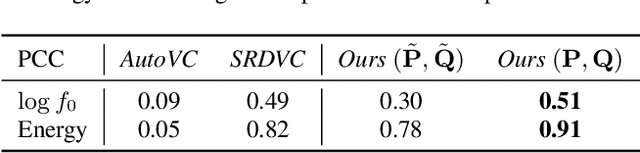
We present a unified system to realize one-shot voice conversion (VC) on the pitch, rhythm, and speaker attributes. Existing works generally ignore the correlation between prosody and language content, leading to the degradation of naturalness in converted speech. Additionally, the lack of proper language features prevents these systems from accurately preserving language content after conversion. To address these issues, we devise a cascaded modular system leveraging self-supervised discrete speech units as language representation. These discrete units provide duration information essential for rhythm modeling. Our system first extracts utterance-level prosody and speaker representations from the raw waveform. Given the prosody representation, a prosody predictor estimates pitch, energy, and duration for each discrete unit in the utterance. A synthesizer further reconstructs speech based on the predicted prosody, speaker representation, and discrete units. Experiments show that our system outperforms previous approaches in naturalness, intelligibility, speaker transferability, and prosody transferability. Code and samples are publicly available.
Automatic Evaluation and Moderation of Open-domain Dialogue Systems
Nov 20, 2021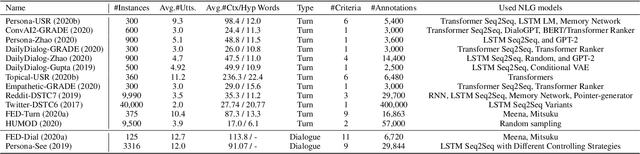


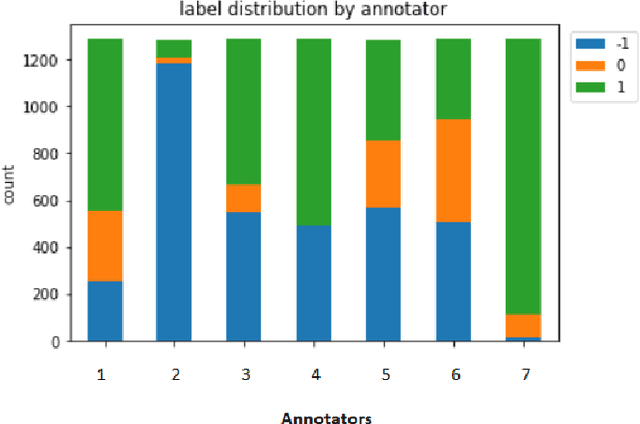
The development of Open-Domain Dialogue Systems (ODS)is a trending topic due to the large number of research challenges, large societal and business impact, and advances in the underlying technology. However, the development of these kinds of systems requires two important characteristics:1) automatic evaluation mechanisms that show high correlations with human judgements across multiple dialogue evaluation aspects (with explainable features for providing constructive and explicit feedback on the quality of generative models' responses for quick development and deployment)and 2) mechanisms that can help to control chatbot responses,while avoiding toxicity and employing intelligent ways to handle toxic user comments and keeping interaction flow and engagement. This track at the 10th Dialogue System Technology Challenge (DSTC10) is part of the ongoing effort to promote scalable and toxic-free ODS. This paper describes the datasets and baselines provided to participants, as well as submission evaluation results for each of the two proposed subtasks
Exploring Wav2vec 2.0 fine-tuning for improved speech emotion recognition
Oct 28, 2021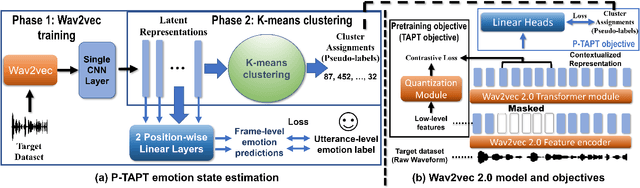
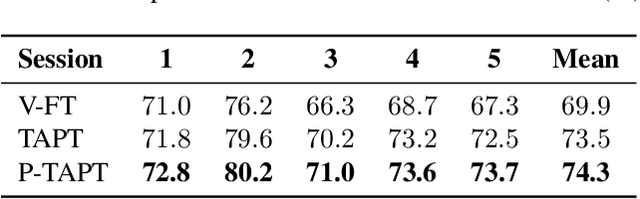
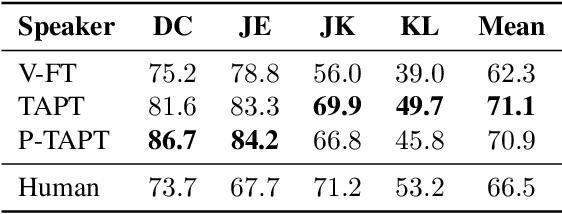

While wav2vec 2.0 has been proposed for speech recognition (ASR), it can also be used for speech emotion recognition (SER); its performance can be significantly improved using different fine-tuning strategies. Two baseline methods, vanilla fine-tuning (V-FT) and task adaptive pretraining (TAPT) are first presented. We show that V-FT is able to outperform state-of-the-art models on the IEMOCAP dataset. TAPT, an existing NLP fine-tuning strategy, further improves the performance on SER. We also introduce a novel fine-tuning method termed P-TAPT, which modifies the TAPT objective to learn contextualized emotion representations. Experiments show that P-TAPT performs better than TAPT especially under low-resource settings. Compared to prior works in this literature, our top-line system achieved a 7.4% absolute improvement on unweighted accuracy (UA) over the state-of-the-art performance on IEMOCAP. Our code is publicly available.
Fine-grained style control in Transformer-based Text-to-speech Synthesis
Oct 12, 2021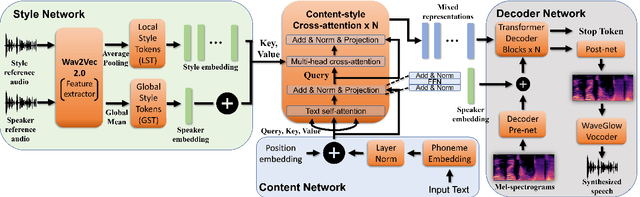

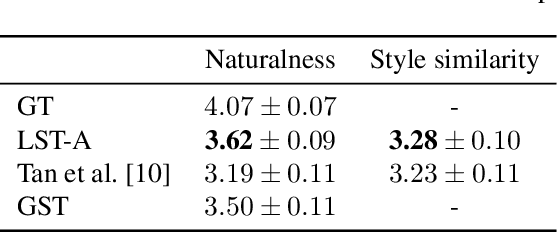
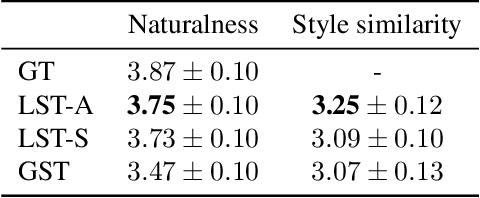
In this paper, we present a novel architecture to realize fine-grained style control on the transformer-based text-to-speech synthesis (TransformerTTS). Specifically, we model the speaking style by extracting a time sequence of local style tokens (LST) from the reference speech. The existing content encoder in TransformerTTS is then replaced by our designed cross-attention blocks for fusion and alignment between content and style. As the fusion is performed along with the skip connection, our cross-attention block provides a good inductive bias to gradually infuse the phoneme representation with a given style. Additionally, we prevent the style embedding from encoding linguistic content by randomly truncating LST during training and using wav2vec 2.0 features. Experiments show that with fine-grained style control, our system performs better in terms of naturalness, intelligibility, and style transferability. Our code and samples are publicly available.
Speech Representation Learning Combining Conformer CPC with Deep Cluster for the ZeroSpeech Challenge 2021
Jul 13, 2021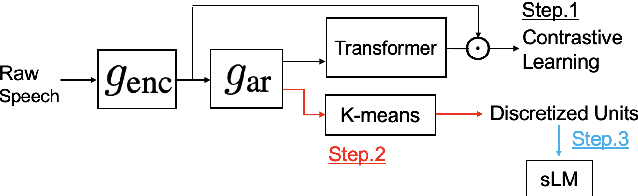

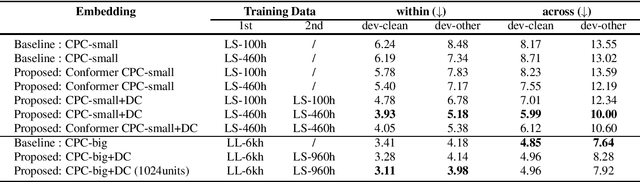
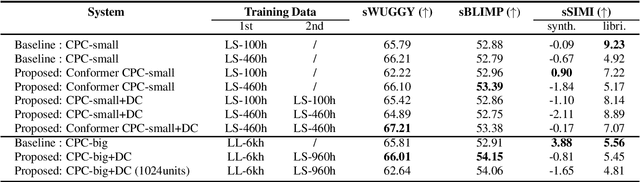
We present a system for the Zero Resource Speech Challenge 2021, which combines a Contrastive Predictive Coding (CPC) with deep cluster. In deep cluster, we first prepare pseudo-labels obtained by clustering the outputs of a CPC network with k-means. Then, we train an additional autoregressive model to classify the previously obtained pseudo-labels in a supervised manner. Phoneme discriminative representation is achieved by executing the second-round clustering with the outputs of the final layer of the autoregressive model. We show that replacing a Transformer layer with a Conformer layer leads to a further gain in a lexical metric. Experimental results show that a relative improvement of 35% in a phonetic metric, 1.5% in the lexical metric, and 2.3% in a syntactic metric are achieved compared to a baseline method of CPC-small which is trained on LibriSpeech 460h data. We achieve top results in this challenge with the syntactic metric.
Adjusting Image Attributes of Localized Regions with Low-level Dialogue
Feb 11, 2020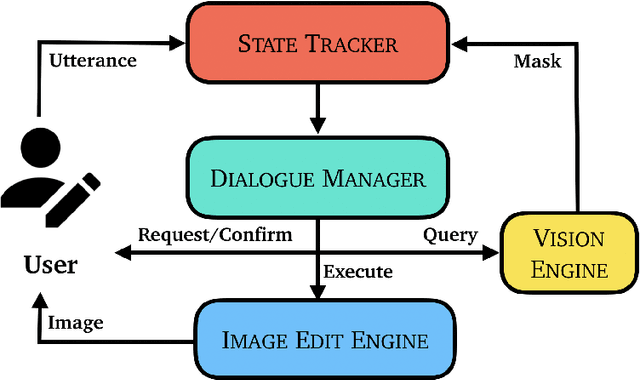

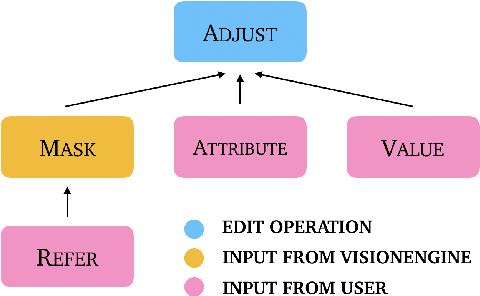

Natural Language Image Editing (NLIE) aims to use natural language instructions to edit images. Since novices are inexperienced with image editing techniques, their instructions are often ambiguous and contain high-level abstractions that tend to correspond to complex editing steps to accomplish. Motivated by this inexperience aspect, we aim to smooth the learning curve by teaching the novices to edit images using low-level commanding terminologies. Towards this end, we develop a task-oriented dialogue system to investigate low-level instructions for NLIE. Our system grounds language on the level of edit operations, and suggests options for a user to choose from. Though compelled to express in low-level terms, a user evaluation shows that 25% of users found our system easy-to-use, resonating with our motivation. An analysis shows that users generally adapt to utilizing the proposed low-level language interface. In this study, we identify that object segmentation as the key factor to the user satisfaction. Our work demonstrates the advantages of the low-level, direct language-action mapping approach that can be applied to other problem domains beyond image editing such as audio editing or industrial design.