 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Wav2vec 2.0 fine-tuning for improved speech emotion recognition
Paper and Code
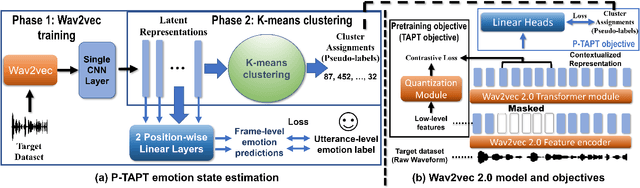
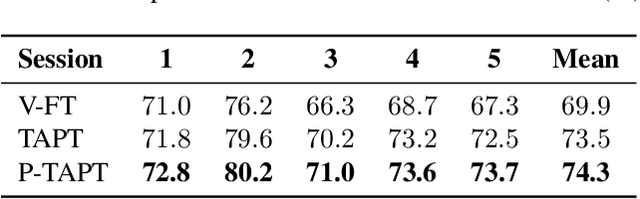
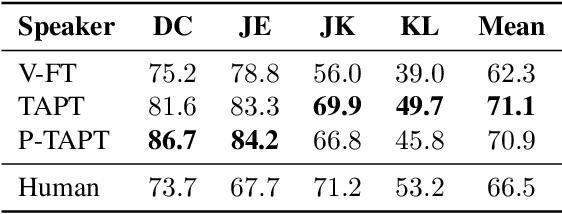

While wav2vec 2.0 has been proposed for speech recognition (ASR), it can also be used for speech emotion recognition (SER); its performance can be significantly improved using different fine-tuning strategies. Two baseline methods, vanilla fine-tuning (V-FT) and task adaptive pretraining (TAPT) are first presented. We show that V-FT is able to outperform state-of-the-art models on the IEMOCAP dataset. TAPT, an existing NLP fine-tuning strategy, further improves the performance on SER. We also introduce a novel fine-tuning method termed P-TAPT, which modifies the TAPT objective to learn contextualized emotion representations. Experiments show that P-TAPT performs better than TAPT especially under low-resource settings. Compared to prior works in this literature, our top-line system achieved a 7.4% absolute improvement on unweighted accuracy (UA) over the state-of-the-art performance on IEMOCAP. Our code is publicly available.