 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSO-VSA: a Variable Stiffness Actuator with Decoupled Stiffness and Output Characteristics for Rehabilitation Robotics
Dec 21, 2025Stroke-induced motor impairment often results in substantial loss of upper-limb function, creating a strong demand for rehabilitation robots that enable safe and transparent physical human-robot interaction (pHRI). Variable stiffness actuators are well suited for such applications. However, in most existing designs, stiffness is coupled with the deflection angle, complicating both modeling and control. To address this limitation, this paper presents a variable stiffness actuator featuring decoupled stiffness and output behavior for rehabilitation robotics. The system integrates a variable stiffness mechanism that combines a variable-length lever with a hypocycloidal straight-line mechanism to achieve a linear torque-deflection relationship and continuous stiffness modulation from near zero to theoretically infinite. It also incorporates a differential transmission mechanism based on a planetary gear system that enables dual-motor load sharing. A cascade PI controller is further developed on the basis of the differential configuration, in which the position-loop term jointly regulates stiffness and deflection angle, effectively suppressing stiffness fluctuations and output disturbances. The performance of prototype was experimentally validated through stiffness calibration, stiffness regulation, torque control, decoupled characteristics, and dual-motor load sharing, indicating the potential for rehabilitation exoskeletons and other pHRI systems.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
TS-Align: A Teacher-Student Collaborative Framework for Scalable Iterative Finetuning of Large Language Models
May 30, 2024



Mainstream approaches to aligning large language models (LLMs) heavily rely on human preference data, particularly when models require periodic updates. The standard process for iterative alignment of LLMs involves collecting new human feedback for each update. However, the data collection process is costly and challenging to scale. To address this issue, we introduce the "TS-Align" framework, which fine-tunes a policy model using pairwise feedback data automatically mined from its outputs. This automatic mining process is efficiently accomplished through the collaboration between a large-scale teacher model and a small-scale student model. The policy fine-tuning process can be iteratively repeated using on-policy generations within our proposed teacher-student collaborative framework. Through extensive experiments, we demonstrate that our final aligned policy outperforms the base policy model with an average win rate of 69.7% across seven conversational or instruction-following datasets. Furthermore, we show that the ranking capability of the teacher is effectively distilled into the student through our pipeline, resulting in a small-scale yet effective reward model for policy model alignment.
xDial-Eval: A Multilingual Open-Domain Dialogue Evaluation Benchmark
Oct 13, 2023



Recent advancements in reference-free learned metrics for open-domain dialogue evaluation have been driven by the progress in pre-trained language models and the availability of dialogue data with high-quality human annotations. However, current studies predominantly concentrate on English dialogues, and the generalization of these metrics to other languages has not been fully examined. This is largely due to the absence of a multilingual dialogue evaluation benchmark. To address the issue, we introduce xDial-Eval, built on top of open-source English dialogue evaluation datasets. xDial-Eval includes 12 turn-level and 6 dialogue-level English datasets, comprising 14930 annotated turns and 8691 annotated dialogues respectively. The English dialogue data are extended to nine other languages with commercial machine translation systems. On xDial-Eval, we conduct comprehensive analyses of previous BERT-based metrics and the recently-emerged large language models. Lastly, we establish strong self-supervised and multilingual baselines. In terms of average Pearson correlations over all datasets and languages, the best baseline outperforms OpenAI's ChatGPT by absolute improvements of 6.5% and 4.6% at the turn and dialogue levels respectively, albeit with much fewer parameters. The data and code are publicly available at https://github.com/e0397123/xDial-Eval.
Overview of Robust and Multilingual Automatic Evaluation Metrics for Open-Domain Dialogue Systems at DSTC 11 Track 4
Jun 22, 2023



The advent and fast development of neural networks have revolutionized the research on dialogue systems and subsequently have triggered various challenges regarding their automatic evaluation. Automatic evaluation of open-domain dialogue systems as an open challenge has been the center of the attention of many researchers. Despite the consistent efforts to improve automatic metrics' correlations with human evaluation, there have been very few attempts to assess their robustness over multiple domains and dimensions. Also, their focus is mainly on the English language. All of these challenges prompt the development of automatic evaluation metrics that are reliable in various domains, dimensions, and languages. This track in the 11th Dialogue System Technology Challenge (DSTC11) is part of the ongoing effort to promote robust and multilingual automatic evaluation metrics. This article describes the datasets and baselines provided to participants and discusses the submission and result details of the two proposed subtasks.
DMRST: A Joint Framework for Document-Level Multilingual RST Discourse Segmentation and Parsing
Oct 09, 2021

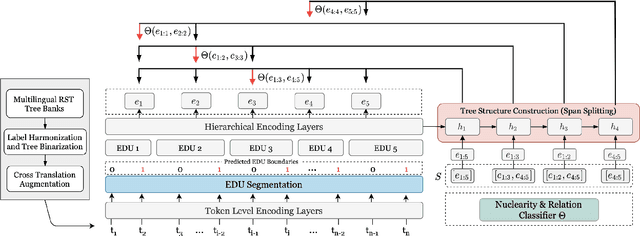

Text discourse parsing weighs importantly in understanding information flow and argumentative structure in natural language, making it beneficial for downstream tasks. While previous work significantly improves the performance of RST discourse parsing, they are not readily applicable to practical use cases: (1) EDU segmentation is not integrated into most existing tree parsing frameworks, thus it is not straightforward to apply such models on newly-coming data. (2) Most parsers cannot be used in multilingual scenarios, because they are developed only in English. (3) Parsers trained from single-domain treebanks do not generalize well on out-of-domain inputs. In this work, we propose a document-level multilingual RST discourse parsing framework, which conducts EDU segmentation and discourse tree parsing jointly. Moreover, we propose a cross-translation augmentation strategy to enable the framework to support multilingual parsing and improve its domain generality. Experimental results show that our model achieves state-of-the-art performance on document-level multilingual RST parsing in all sub-tasks.
Multilingual Speech Evaluation: Case Studies on English, Malay and Tamil
Jul 08, 2021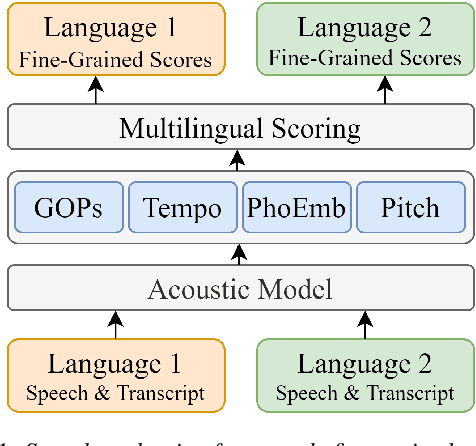
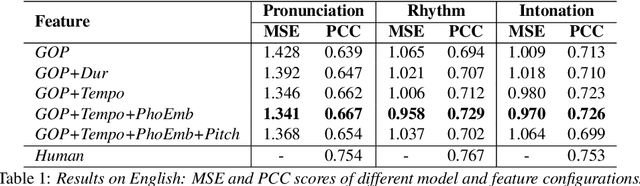
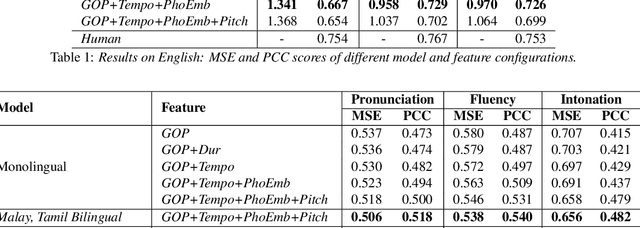
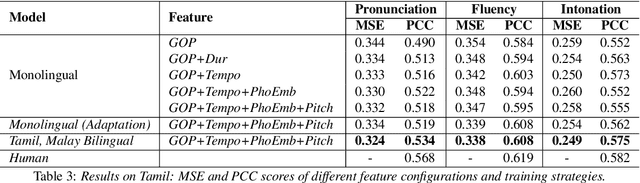
Speech evaluation is an essential component in computer-assisted language learning (CALL). While speech evaluation on English has been popular, automatic speech scoring on low resource languages remains challenging. Work in this area has focused on monolingual specific designs and handcrafted features stemming from resource-rich languages like English. Such approaches are often difficult to generalize to other languages, especially if we also want to consider suprasegmental qualities such as rhythm. In this work, we examine three different languages that possess distinct rhythm patterns: English (stress-timed), Malay (syllable-timed), and Tamil (mora-timed). We exploit robust feature representations inspired by music processing and vector representation learning. Empirical validations show consistent gains for all three languages when predicting pronunciation, rhythm and intonation performance.
Coreference-Aware Dialogue Summarization
Jun 16, 2021


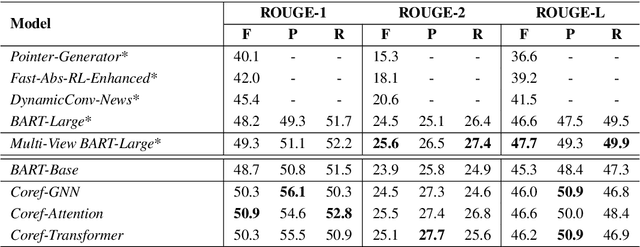
Summarizing conversations via neural approaches has been gaining research traction lately, yet it is still challenging to obtain practical solutions. Examples of such challenges include unstructured information exchange in dialogues, informal interactions between speakers, and dynamic role changes of speakers as the dialogue evolves. Many of such challenges result in complex coreference links. Therefore, in this work, we investigate different approaches to explicitly incorporate coreference information in neural abstractive dialogue summarization models to tackle the aforementioned challenges. Experimental results show that the proposed approaches achieve state-of-the-art performance, implying it is useful to utilize coreference information in dialogue summarization. Evaluation results on factual correctness suggest such coreference-aware models are better at tracing the information flow among interlocutors and associating accurate status/actions with the corresponding interlocutors and person mentions.
An End-to-End Document-Level Neural Discourse Parser Exploiting Multi-Granularity Representations
Dec 21, 2020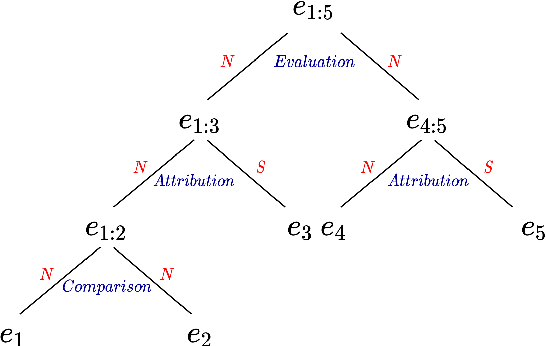



Document-level discourse parsing, in accordance with the Rhetorical Structure Theory (RST), remains notoriously challenging. Challenges include the deep structure of document-level discourse trees, the requirement of subtle semantic judgments, and the lack of large-scale training corpora. To address such challenges, we propose to exploit robust representations derived from multiple levels of granularity across syntax and semantics, and in turn incorporate such representations in an end-to-end encoder-decoder neural architecture for more resourceful discourse processing. In particular, we first use a pre-trained contextual language model that embodies high-order and long-range dependency to enable finer-grain semantic, syntactic, and organizational representations. We further encode such representations with boundary and hierarchical information to obtain more refined modeling for document-level discourse processing. Experimental results show that our parser achieves the state-of-the-art performance, approaching human-level performance on the benchmarked RST dataset.
Multilingual Neural RST Discourse Parsing
Dec 03, 2020

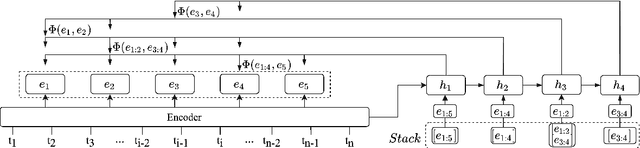
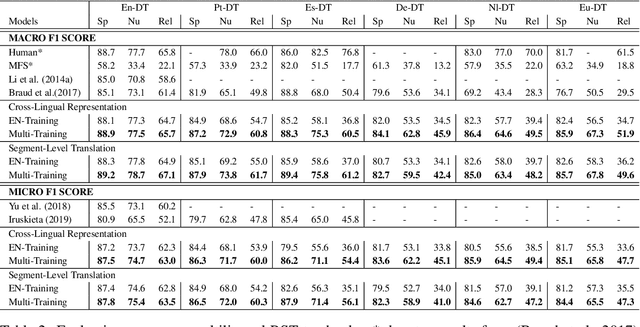
Text discourse parsing plays an important role in understanding information flow and argumentative structure in natural language. Previous research under the Rhetorical Structure Theory (RST) has mostly focused on inducing and evaluating models from the English treebank. However, the parsing tasks for other languages such as German, Dutch, and Portuguese are still challenging due to the shortage of annotated data. In this work, we investigate two approaches to establish a neural, cross-lingual discourse parser via: (1) utilizing multilingual vector representations; and (2) adopting segment-level translation of the source content. Experiment results show that both methods are effective even with limited training data, and achieve state-of-the-art performance on cross-lingual, document-level discourse parsing on all sub-tasks.