 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-layered Acoustic Tokenizing Deep Neural Network (MAT-DNN) for Unsupervised Discovery of Linguistic Units and Generation of High Quality Features
Jun 07, 2015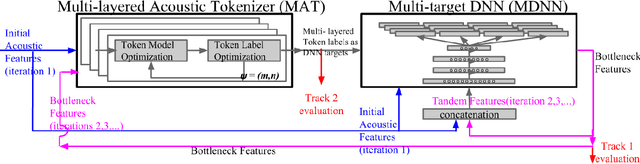
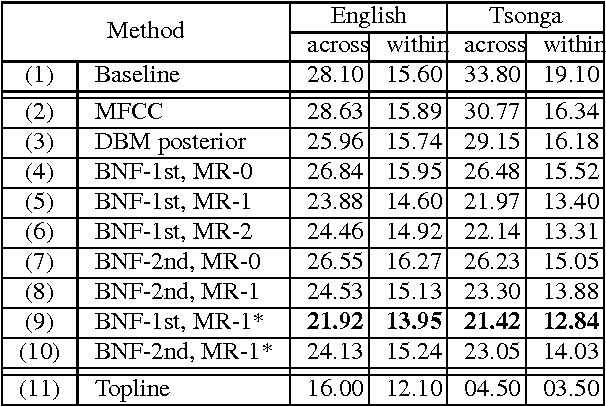
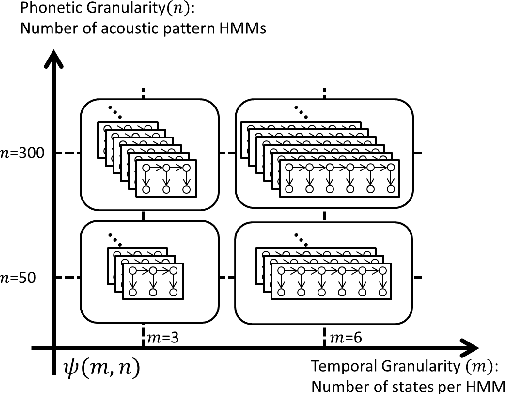
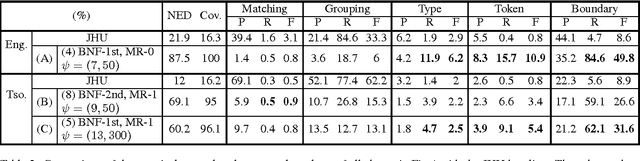
This paper summarizes the work done by the authors for the Zero Resource Speech Challenge organized in the technical program of Interspeech 2015. The goal of the challenge is to discover linguistic units directly from unlabeled speech data. The Multi-layered Acoustic Tokenizer (MAT) proposed in this work automatically discovers multiple sets of acoustic tokens from the given corpus. Each acoustic token set is specified by a set of hyperparameters that describe the model configuration. These sets of acoustic tokens carry different characteristics of the given corpus and the language behind thus can be mutually reinforced. The multiple sets of token labels are then used as the targets of a Multi-target DNN (MDNN) trained on low-level acoustic features. Bottleneck features extracted from the MDNN are used as feedback for the MAT and the MDNN itself. We call this iterative system the Multi-layered Acoustic Tokenizing Deep Neural Network (MAT-DNN) which generates high quality features for track 1 of the challenge and acoustic tokens for track 2 of the challenge.