 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReport from the NSF Future Directions Workshop on Automatic Evaluation of Dialog: Research Directions and Challenges
Mar 18, 2022

This is a report on the NSF Future Directions Workshop on Automatic Evaluation of Dialog. The workshop explored the current state of the art along with its limitations and suggested promising directions for future work in this important and very rapidly changing area of research.
AgentGraph: Towards Universal Dialogue Management with Structured Deep Reinforcement Learning
May 27, 2019
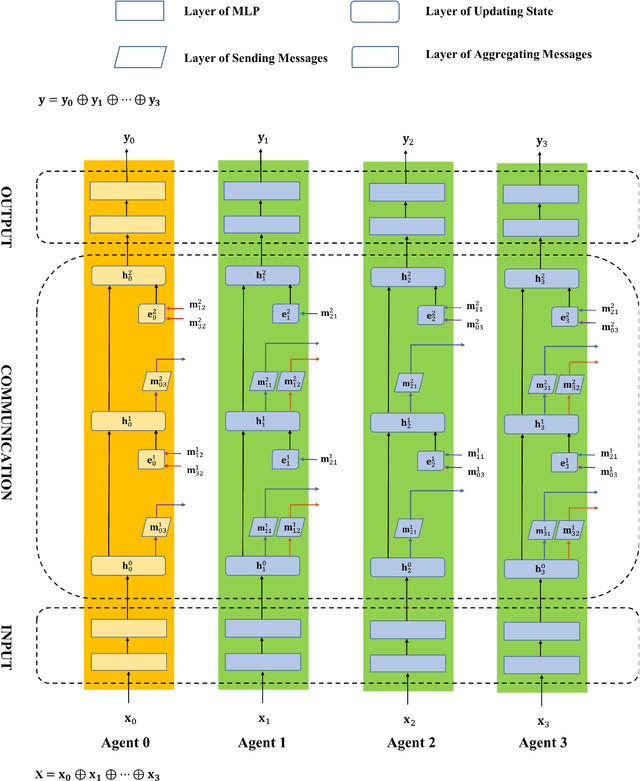


Dialogue policy plays an important role in task-oriented spoken dialogue systems. It determines how to respond to users. The recently proposed deep reinforcement learning (DRL) approaches have been used for policy optimization. However, these deep models are still challenging for two reasons: 1) Many DRL-based policies are not sample-efficient. 2) Most models don't have the capability of policy transfer between different domains. In this paper, we propose a universal framework, AgentGraph, to tackle these two problems. The proposed AgentGraph is the combination of GNN-based architecture and DRL-based algorithm. It can be regarded as one of the multi-agent reinforcement learning approaches. Each agent corresponds to a node in a graph, which is defined according to the dialogue domain ontology. When making a decision, each agent can communicate with its neighbors on the graph. Under AgentGraph framework, we further propose Dual GNN-based dialogue policy, which implicitly decomposes the decision in each turn into a high-level global decision and a low-level local decision. Experiments show that AgentGraph models significantly outperform traditional reinforcement learning approaches on most of the 18 tasks of the PyDial benchmark. Moreover, when transferred from the source task to a target task, these models not only have acceptable initial performance but also converge much faster on the target task.
Variational Cross-domain Natural Language Generation for Spoken Dialogue Systems
Dec 20, 2018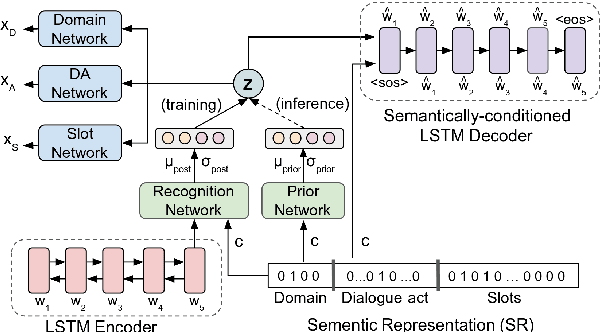

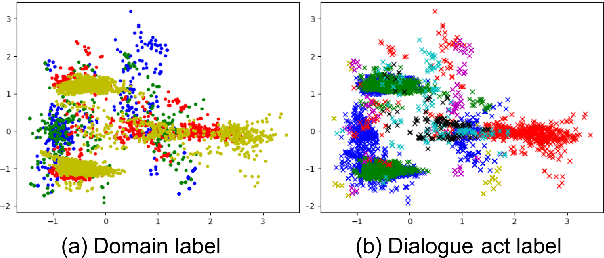
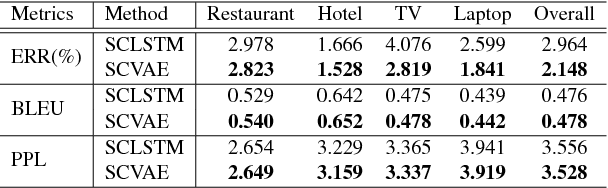
Cross-domain natural language generation (NLG) is still a difficult task within spoken dialogue modelling. Given a semantic representation provided by the dialogue manager, the language generator should generate sentences that convey desired information. Traditional template-based generators can produce sentences with all necessary information, but these sentences are not sufficiently diverse. With RNN-based models, the diversity of the generated sentences can be high, however, in the process some information is lost. In this work, we improve an RNN-based generator by considering latent information at the sentence level during generation using the conditional variational autoencoder architecture. We demonstrate that our model outperforms the original RNN-based generator, while yielding highly diverse sentences. In addition, our model performs better when the training data is limited.
Deep learning for language understanding of mental health concepts derived from Cognitive Behavioural Therapy
Sep 03, 2018

In recent years, we have seen deep learning and distributed representations of words and sentences make impact on a number of natural language processing tasks, such as similarity, entailment and sentiment analysis. Here we introduce a new task: understanding of mental health concepts derived from Cognitive Behavioural Therapy (CBT). We define a mental health ontology based on the CBT principles, annotate a large corpus where this phenomena is exhibited and perform understanding using deep learning and distributed representations. Our results show that the performance of deep learning models combined with word embeddings or sentence embeddings significantly outperform non-deep-learning models in this difficult task. This understanding module will be an essential component of a statistical dialogue system delivering therapy.
Nearly Zero-Shot Learning for Semantic Decoding in Spoken Dialogue Systems
Jun 21, 2018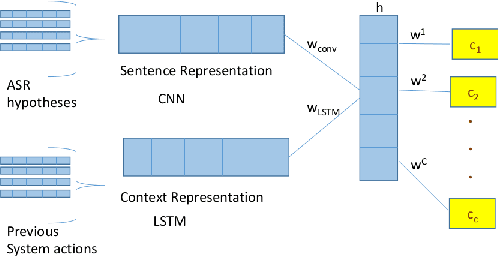
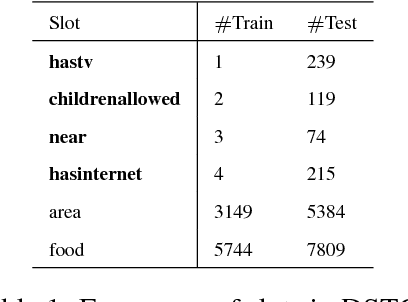
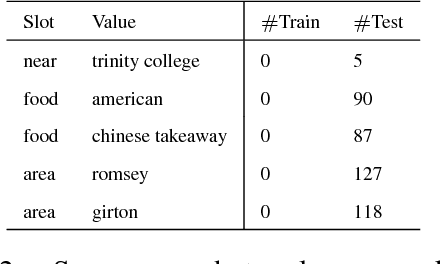

This paper presents two ways of dealing with scarce data in semantic decoding using N-Best speech recognition hypotheses. First, we learn features by using a deep learning architecture in which the weights for the unknown and known categories are jointly optimised. Second, an unsupervised method is used for further tuning the weights. Sharing weights injects prior knowledge to unknown categories. The unsupervised tuning (i.e. the risk minimisation) improves the F-Measure when recognising nearly zero-shot data on the DSTC3 corpus. This unsupervised method can be applied subject to two assumptions: the rank of the class marginal is assumed to be known and the class-conditional scores of the classifier are assumed to follow a Gaussian distribution.
Neural User Simulation for Corpus-based Policy Optimisation for Spoken Dialogue Systems
May 17, 2018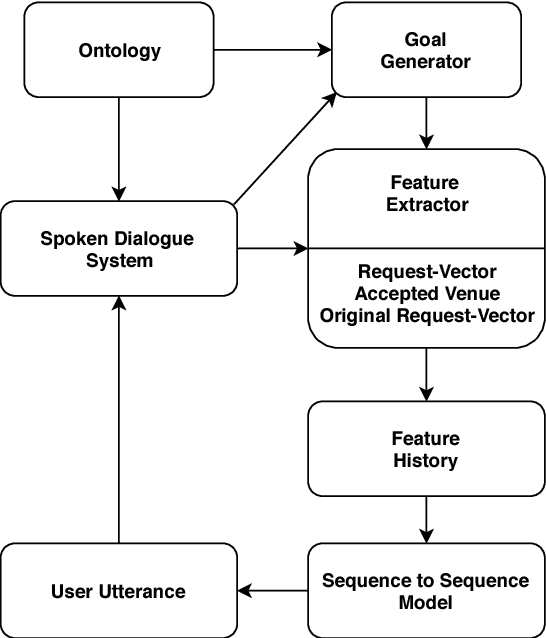

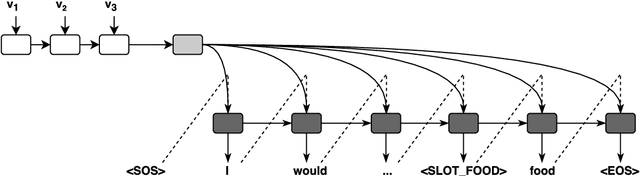
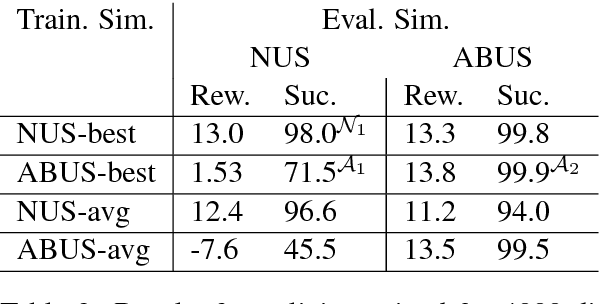
User Simulators are one of the major tools that enable offline training of task-oriented dialogue systems. For this task the Agenda-Based User Simulator (ABUS) is often used. The ABUS is based on hand-crafted rules and its output is in semantic form. Issues arise from both properties such as limited diversity and the inability to interface a text-level belief tracker. This paper introduces the Neural User Simulator (NUS) whose behaviour is learned from a corpus and which generates natural language, hence needing a less labelled dataset than simulators generating a semantic output. In comparison to much of the past work on this topic, which evaluates user simulators on corpus-based metrics, we use the NUS to train the policy of a reinforcement learning based Spoken Dialogue System. The NUS is compared to the ABUS by evaluating the policies that were trained using the simulators. Cross-model evaluation is performed i.e. training on one simulator and testing on the other. Furthermore, the trained policies are tested on real users. In both evaluation tasks the NUS outperformed the ABUS.
Sample-efficient Actor-Critic Reinforcement Learning with Supervised Data for Dialogue Management
Jul 05, 2017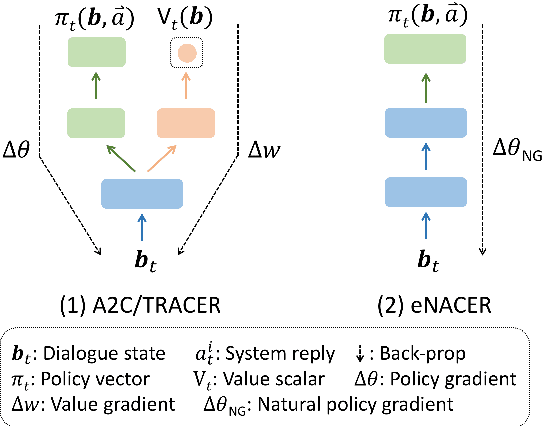
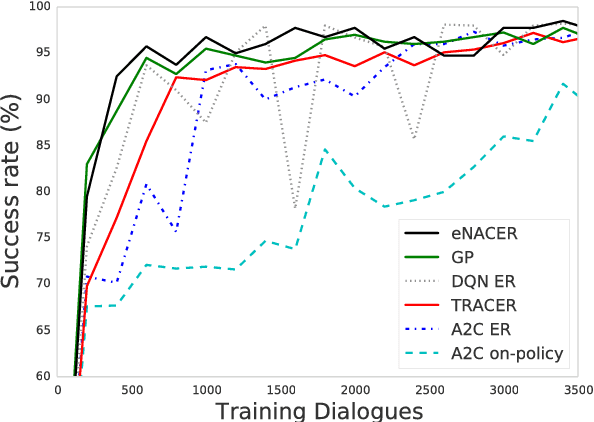
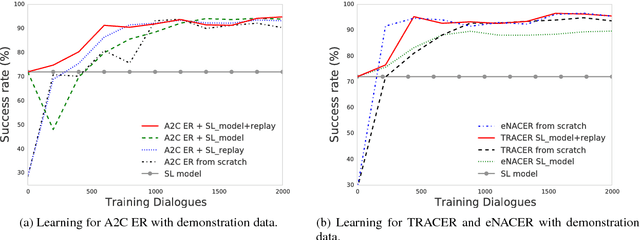
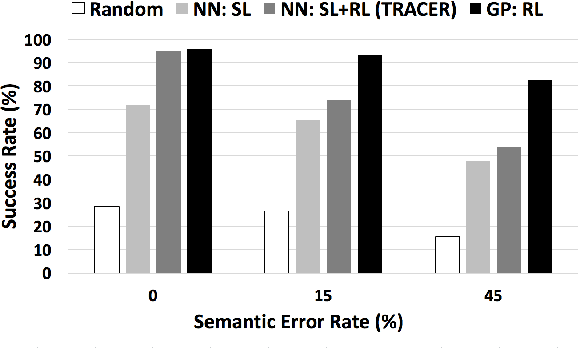
Deep reinforcement learning (RL) methods have significant potential for dialogue policy optimisation. However, they suffer from a poor performance in the early stages of learning. This is especially problematic for on-line learning with real users. Two approaches are introduced to tackle this problem. Firstly, to speed up the learning process, two sample-efficient neural networks algorithms: trust region actor-critic with experience replay (TRACER) and episodic natural actor-critic with experience replay (eNACER) are presented. For TRACER, the trust region helps to control the learning step size and avoid catastrophic model changes. For eNACER, the natural gradient identifies the steepest ascent direction in policy space to speed up the convergence. Both models employ off-policy learning with experience replay to improve sample-efficiency. Secondly, to mitigate the cold start issue, a corpus of demonstration data is utilised to pre-train the models prior to on-line reinforcement learning. Combining these two approaches, we demonstrate a practical approach to learn deep RL-based dialogue policies and demonstrate their effectiveness in a task-oriented information seeking domain.
A Network-based End-to-End Trainable Task-oriented Dialogue System
Apr 24, 2017Teaching machines to accomplish tasks by conversing naturally with humans is challenging. Currently, developing task-oriented dialogue systems requires creating multiple components and typically this involves either a large amount of handcrafting, or acquiring costly labelled datasets to solve a statistical learning problem for each component. In this work we introduce a neural network-based text-in, text-out end-to-end trainable goal-oriented dialogue system along with a new way of collecting dialogue data based on a novel pipe-lined Wizard-of-Oz framework. This approach allows us to develop dialogue systems easily and without making too many assumptions about the task at hand. The results show that the model can converse with human subjects naturally whilst helping them to accomplish tasks in a restaurant search domain.
Exploiting Sentence and Context Representations in Deep Neural Models for Spoken Language Understanding
Oct 13, 2016
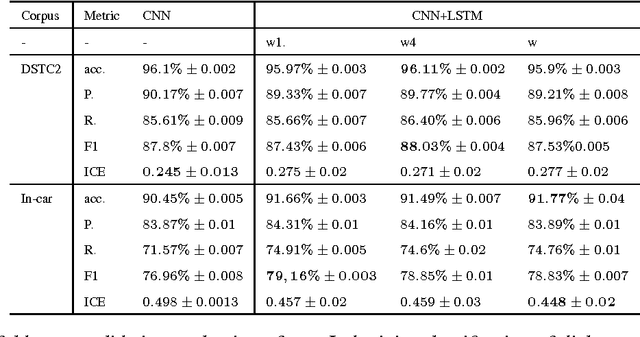
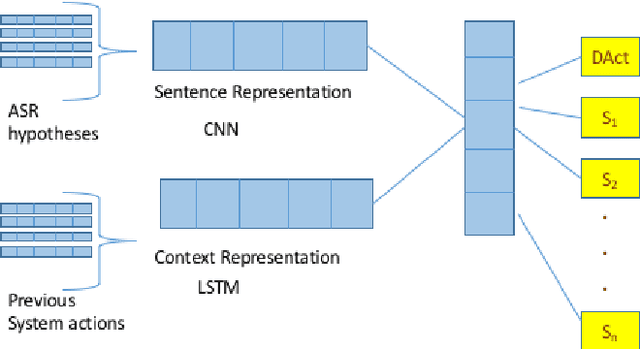
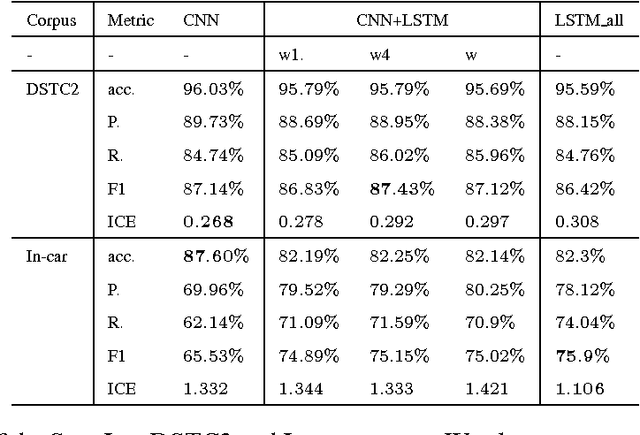
This paper presents a deep learning architecture for the semantic decoder component of a Statistical Spoken Dialogue System. In a slot-filling dialogue, the semantic decoder predicts the dialogue act and a set of slot-value pairs from a set of n-best hypotheses returned by the Automatic Speech Recognition. Most current models for spoken language understanding assume (i) word-aligned semantic annotations as in sequence taggers and (ii) delexicalisation, or a mapping of input words to domain-specific concepts using heuristics that try to capture morphological variation but that do not scale to other domains nor to language variation (e.g., morphology, synonyms, paraphrasing ). In this work the semantic decoder is trained using unaligned semantic annotations and it uses distributed semantic representation learning to overcome the limitations of explicit delexicalisation. The proposed architecture uses a convolutional neural network for the sentence representation and a long-short term memory network for the context representation. Results are presented for the publicly available DSTC2 corpus and an In-car corpus which is similar to DSTC2 but has a significantly higher word error rate (WER).
Dialogue manager domain adaptation using Gaussian process reinforcement learning
Sep 09, 2016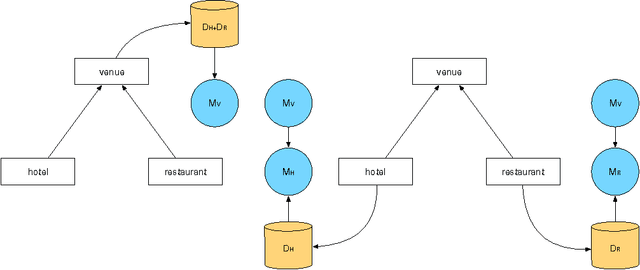
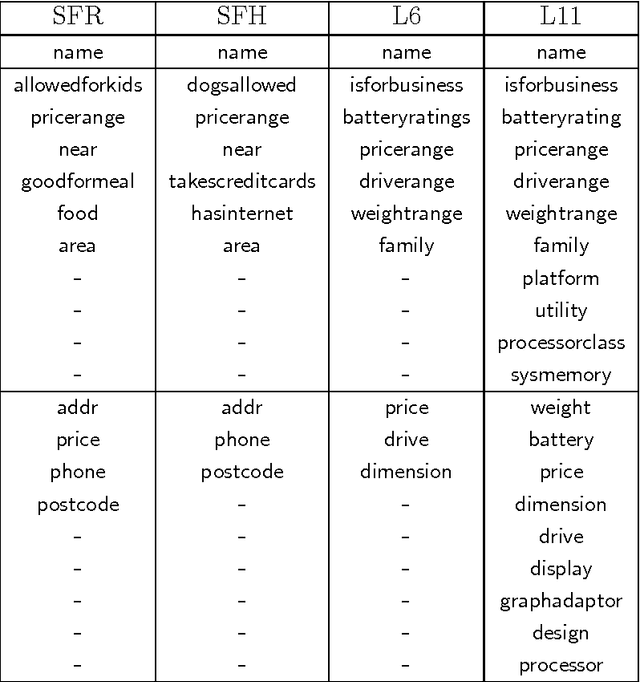
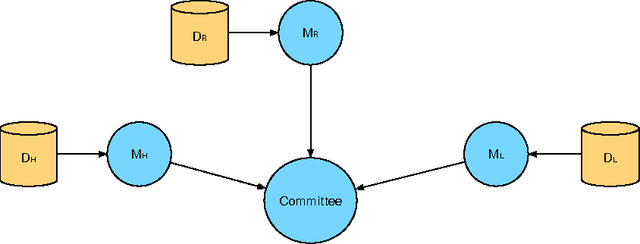
Spoken dialogue systems allow humans to interact with machines using natural speech. As such, they have many benefits. By using speech as the primary communication medium, a computer interface can facilitate swift, human-like acquisition of information. In recent years, speech interfaces have become ever more popular, as is evident from the rise of personal assistants such as Siri, Google Now, Cortana and Amazon Alexa. Recently, data-driven machine learning methods have been applied to dialogue modelling and the results achieved for limited-domain applications are comparable to or outperform traditional approaches. Methods based on Gaussian processes are particularly effective as they enable good models to be estimated from limited training data. Furthermore, they provide an explicit estimate of the uncertainty which is particularly useful for reinforcement learning. This article explores the additional steps that are necessary to extend these methods to model multiple dialogue domains. We show that Gaussian process reinforcement learning is an elegant framework that naturally supports a range of methods, including prior knowledge, Bayesian committee machines and multi-agent learning, for facilitating extensible and adaptable dialogue systems.