 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Cross-domain Natural Language Generation for Spoken Dialogue Systems
Dec 20, 2018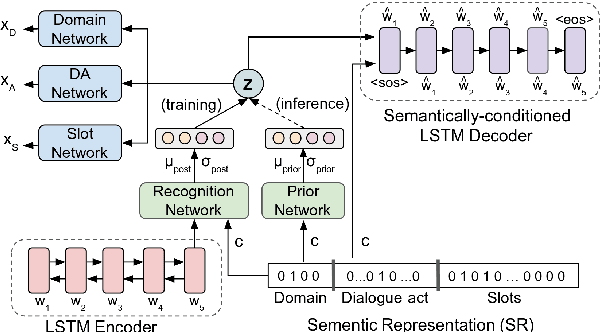

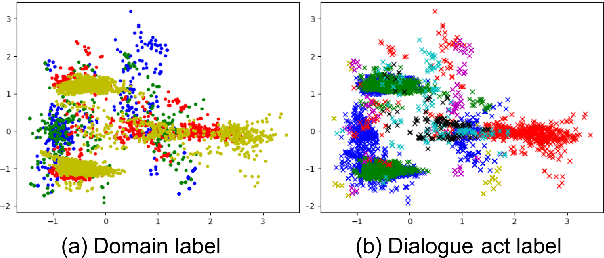
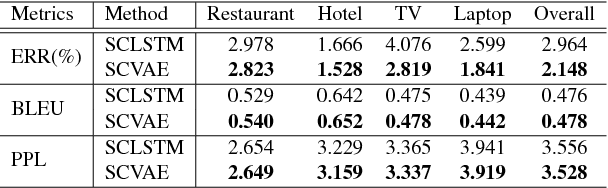
Cross-domain natural language generation (NLG) is still a difficult task within spoken dialogue modelling. Given a semantic representation provided by the dialogue manager, the language generator should generate sentences that convey desired information. Traditional template-based generators can produce sentences with all necessary information, but these sentences are not sufficiently diverse. With RNN-based models, the diversity of the generated sentences can be high, however, in the process some information is lost. In this work, we improve an RNN-based generator by considering latent information at the sentence level during generation using the conditional variational autoencoder architecture. We demonstrate that our model outperforms the original RNN-based generator, while yielding highly diverse sentences. In addition, our model performs better when the training data is limited.
Nearly Zero-Shot Learning for Semantic Decoding in Spoken Dialogue Systems
Jun 21, 2018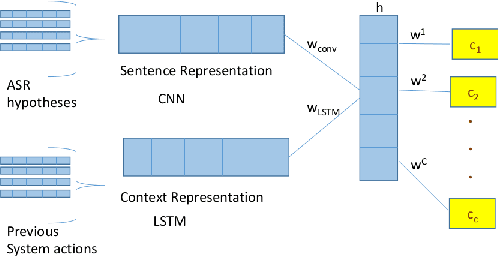
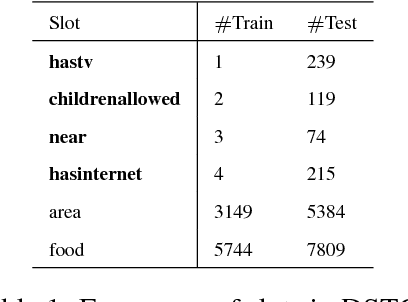
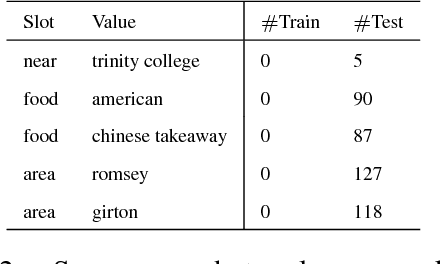

This paper presents two ways of dealing with scarce data in semantic decoding using N-Best speech recognition hypotheses. First, we learn features by using a deep learning architecture in which the weights for the unknown and known categories are jointly optimised. Second, an unsupervised method is used for further tuning the weights. Sharing weights injects prior knowledge to unknown categories. The unsupervised tuning (i.e. the risk minimisation) improves the F-Measure when recognising nearly zero-shot data on the DSTC3 corpus. This unsupervised method can be applied subject to two assumptions: the rank of the class marginal is assumed to be known and the class-conditional scores of the classifier are assumed to follow a Gaussian distribution.
Neural User Simulation for Corpus-based Policy Optimisation for Spoken Dialogue Systems
May 17, 2018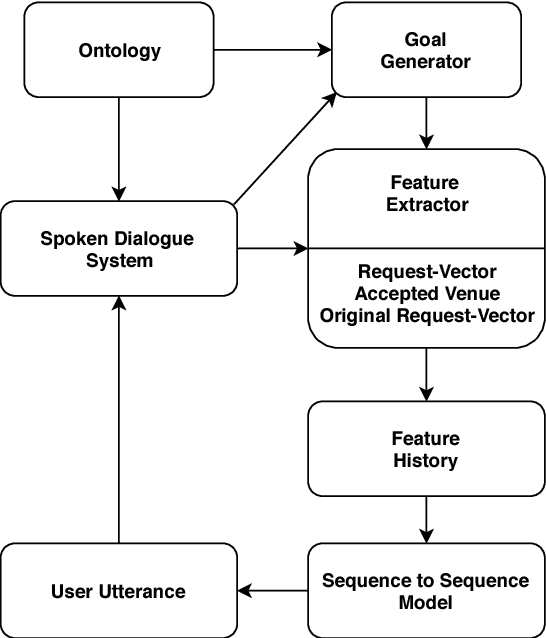

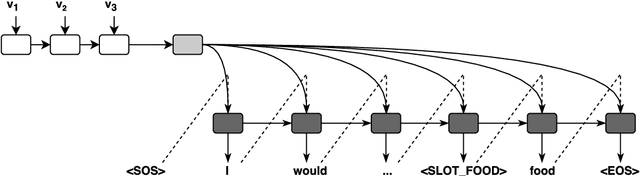
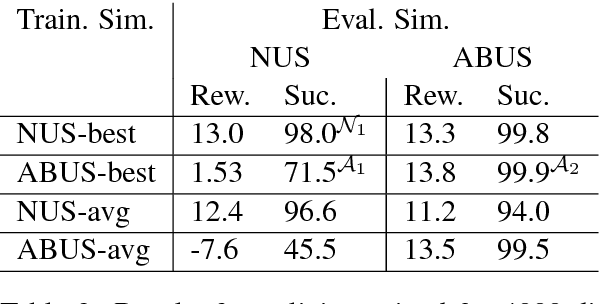
User Simulators are one of the major tools that enable offline training of task-oriented dialogue systems. For this task the Agenda-Based User Simulator (ABUS) is often used. The ABUS is based on hand-crafted rules and its output is in semantic form. Issues arise from both properties such as limited diversity and the inability to interface a text-level belief tracker. This paper introduces the Neural User Simulator (NUS) whose behaviour is learned from a corpus and which generates natural language, hence needing a less labelled dataset than simulators generating a semantic output. In comparison to much of the past work on this topic, which evaluates user simulators on corpus-based metrics, we use the NUS to train the policy of a reinforcement learning based Spoken Dialogue System. The NUS is compared to the ABUS by evaluating the policies that were trained using the simulators. Cross-model evaluation is performed i.e. training on one simulator and testing on the other. Furthermore, the trained policies are tested on real users. In both evaluation tasks the NUS outperformed the ABUS.
Sample-efficient Actor-Critic Reinforcement Learning with Supervised Data for Dialogue Management
Jul 05, 2017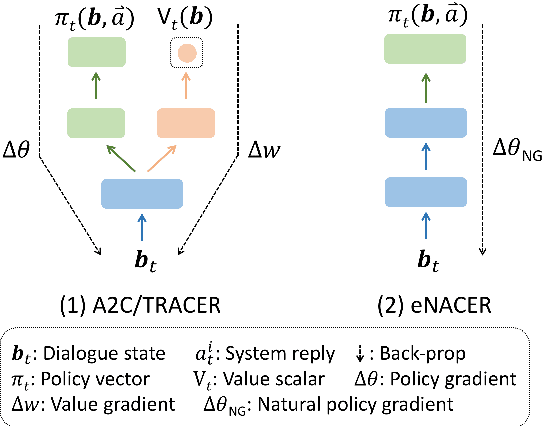
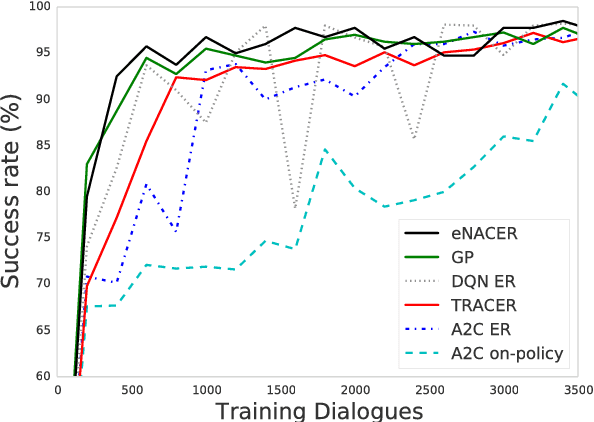
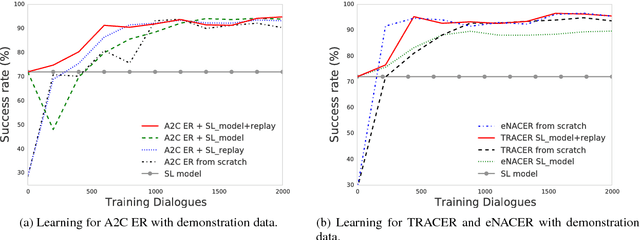
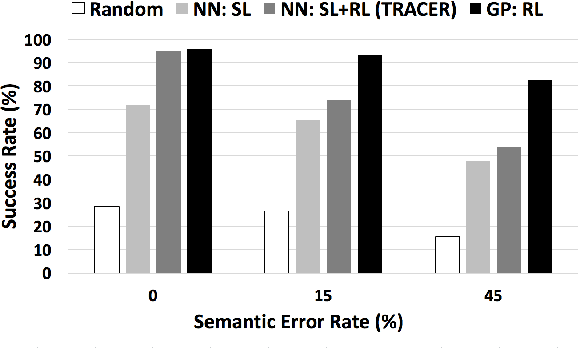
Deep reinforcement learning (RL) methods have significant potential for dialogue policy optimisation. However, they suffer from a poor performance in the early stages of learning. This is especially problematic for on-line learning with real users. Two approaches are introduced to tackle this problem. Firstly, to speed up the learning process, two sample-efficient neural networks algorithms: trust region actor-critic with experience replay (TRACER) and episodic natural actor-critic with experience replay (eNACER) are presented. For TRACER, the trust region helps to control the learning step size and avoid catastrophic model changes. For eNACER, the natural gradient identifies the steepest ascent direction in policy space to speed up the convergence. Both models employ off-policy learning with experience replay to improve sample-efficiency. Secondly, to mitigate the cold start issue, a corpus of demonstration data is utilised to pre-train the models prior to on-line reinforcement learning. Combining these two approaches, we demonstrate a practical approach to learn deep RL-based dialogue policies and demonstrate their effectiveness in a task-oriented information seeking domain.