 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Intent Detection with Dual Sentence Encoders
Mar 10, 2020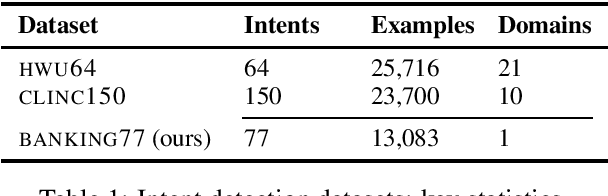

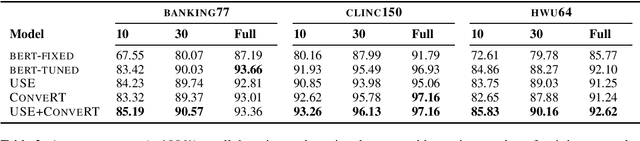

Building conversational systems in new domains and with added functionality requires resource-efficient models that work under low-data regimes (i.e., in few-shot setups). Motivated by these requirements, we introduce intent detection methods backed by pretrained dual sentence encoders such as USE and ConveRT. We demonstrate the usefulness and wide applicability of the proposed intent detectors, showing that: 1) they outperform intent detectors based on fine-tuning the full BERT-Large model or using BERT as a fixed black-box encoder on three diverse intent detection data sets; 2) the gains are especially pronounced in few-shot setups (i.e., with only 10 or 30 annotated examples per intent); 3) our intent detectors can be trained in a matter of minutes on a single CPU; and 4) they are stable across different hyperparameter settings. In hope of facilitating and democratizing research focused on intention detection, we release our code, as well as a new challenging single-domain intent detection dataset comprising 13,083 annotated examples over 77 intents.
Local Homology of Word Embeddings
Oct 24, 2018



Topological data analysis (TDA) has been widely used to make progress on a number of problems. However, it seems that TDA application in natural language processing (NLP) is at its infancy. In this paper we try to bridge the gap by arguing why TDA tools are a natural choice when it comes to analysing word embedding data. We describe a parallelisable unsupervised learning algorithm based on local homology of datapoints and show some experimental results on word embedding data. We see that local homology of datapoints in word embedding data contains some information that can potentially be used to solve the word sense disambiguation problem.