 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLU++: A Multi-Label, Slot-Rich, Generalisable Dataset for Natural Language Understanding in Task-Oriented Dialogue
May 05, 2022



We present NLU++, a novel dataset for natural language understanding (NLU) in task-oriented dialogue (ToD) systems, with the aim to provide a much more challenging evaluation environment for dialogue NLU models, up to date with the current application and industry requirements. NLU++ is divided into two domains (BANKING and HOTELS) and brings several crucial improvements over current commonly used NLU datasets. 1) NLU++ provides fine-grained domain ontologies with a large set of challenging multi-intent sentences, introducing and validating the idea of intent modules that can be combined into complex intents that convey complex user goals, combined with finer-grained and thus more challenging slot sets. 2) The ontology is divided into domain-specific and generic (i.e., domain-universal) intent modules that overlap across domains, promoting cross-domain reusability of annotated examples. 3) The dataset design has been inspired by the problems observed in industrial ToD systems, and 4) it has been collected, filtered and carefully annotated by dialogue NLU experts, yielding high-quality annotated data. Finally, we benchmark a series of current state-of-the-art NLU models on NLU++; the results demonstrate the challenging nature of the dataset, especially in low-data regimes, the validity of `intent modularisation', and call for further research on ToD NLU.
EVI: Multilingual Spoken Dialogue Tasks and Dataset for Knowledge-Based Enrolment, Verification, and Identification
Apr 28, 2022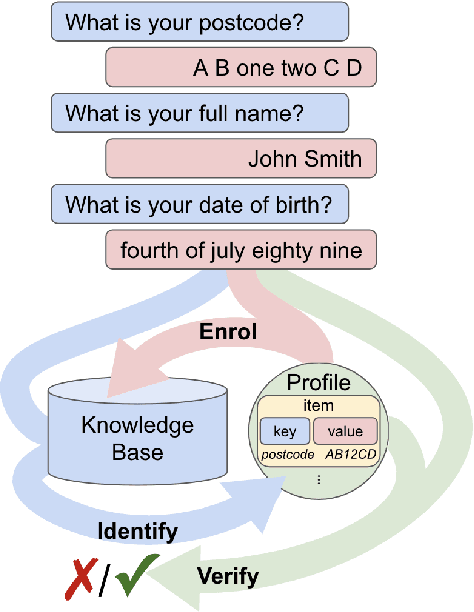
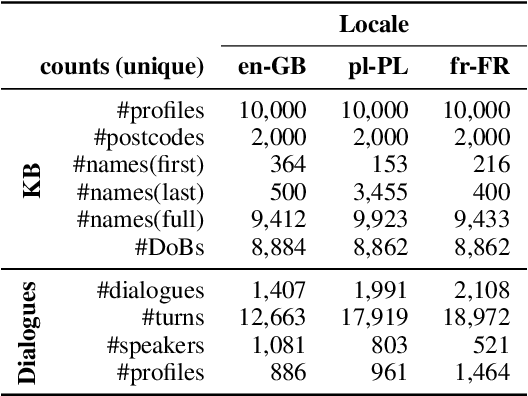
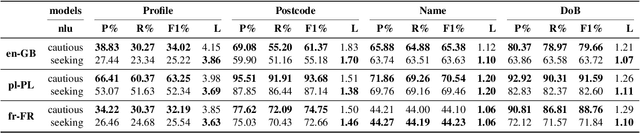
Knowledge-based authentication is crucial for task-oriented spoken dialogue systems that offer personalised and privacy-focused services. Such systems should be able to enrol (E), verify (V), and identify (I) new and recurring users based on their personal information, e.g. postcode, name, and date of birth. In this work, we formalise the three authentication tasks and their evaluation protocols, and we present EVI, a challenging spoken multilingual dataset with 5,506 dialogues in English, Polish, and French. Our proposed models set the first competitive benchmarks, explore the challenges of multilingual natural language processing of spoken dialogue, and set directions for future research.
Numeracy for Language Models: Evaluating and Improving their Ability to Predict Numbers
May 21, 2018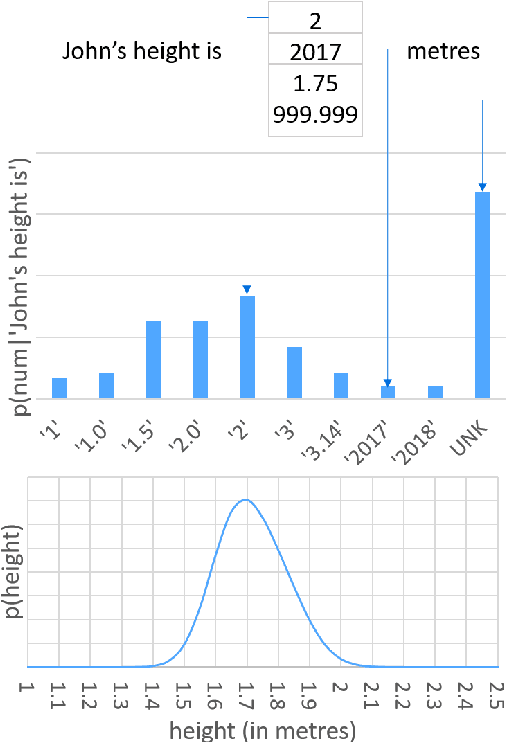
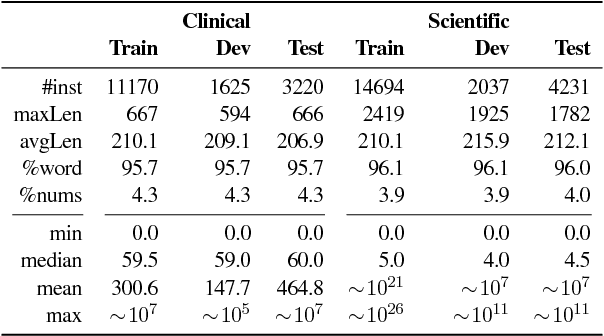

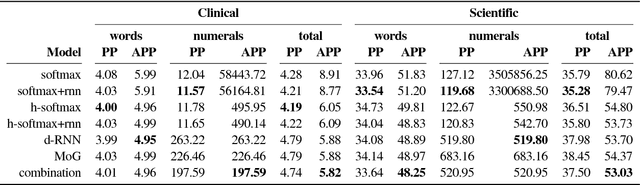
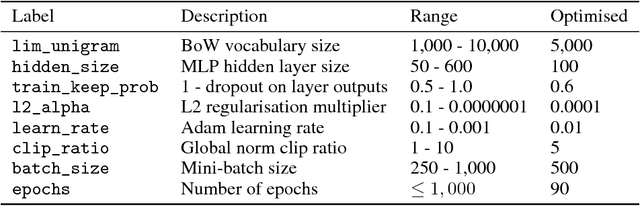
Numeracy is the ability to understand and work with numbers. It is a necessary skill for composing and understanding documents in clinical, scientific, and other technical domains. In this paper, we explore different strategies for modelling numerals with language models, such as memorisation and digit-by-digit composition, and propose a novel neural architecture that uses a continuous probability density function to model numerals from an open vocabulary. Our evaluation on clinical and scientific datasets shows that using hierarchical models to distinguish numerals from words improves a perplexity metric on the subset of numerals by 2 and 4 orders of magnitude, respectively, over non-hierarchical models. A combination of strategies can further improve perplexity. Our continuous probability density function model reduces mean absolute percentage errors by 18% and 54% in comparison to the second best strategy for each dataset, respectively.
A simple but tough-to-beat baseline for the Fake News Challenge stance detection task
May 21, 2018
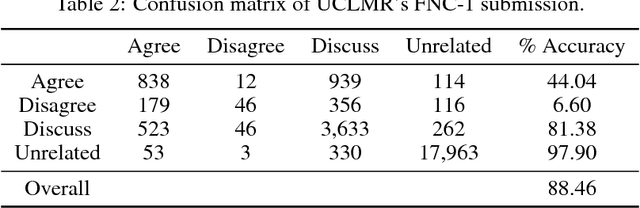

Identifying public misinformation is a complicated and challenging task. An important part of checking the veracity of a specific claim is to evaluate the stance different news sources take towards the assertion. Automatic stance evaluation, i.e. stance detection, would arguably facilitate the process of fact checking. In this paper, we present our stance detection system which claimed third place in Stage 1 of the Fake News Challenge. Despite our straightforward approach, our system performs at a competitive level with the complex ensembles of the top two winning teams. We therefore propose our system as the 'simple but tough-to-beat baseline' for the Fake News Challenge stance detection task.
Image-Grounded Conversations: Multimodal Context for Natural Question and Response Generation
Apr 20, 2017



The popularity of image sharing on social media and the engagement it creates between users reflects the important role that visual context plays in everyday conversations. We present a novel task, Image-Grounded Conversations (IGC), in which natural-sounding conversations are generated about a shared image. To benchmark progress, we introduce a new multiple-reference dataset of crowd-sourced, event-centric conversations on images. IGC falls on the continuum between chit-chat and goal-directed conversation models, where visual grounding constrains the topic of conversation to event-driven utterances. Experiments with models trained on social media data show that the combination of visual and textual context enhances the quality of generated conversational turns. In human evaluation, the gap between human performance and that of both neural and retrieval architectures suggests that multi-modal IGC presents an interesting challenge for dialogue research.
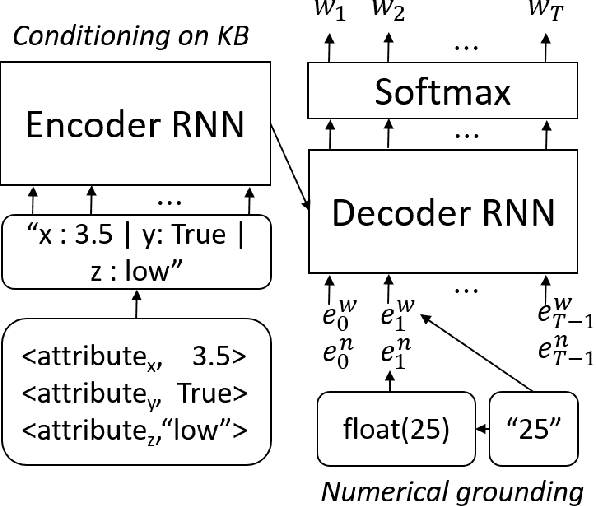
Clinical Text Prediction with Numerically Grounded Conditional Language Models
Oct 20, 2016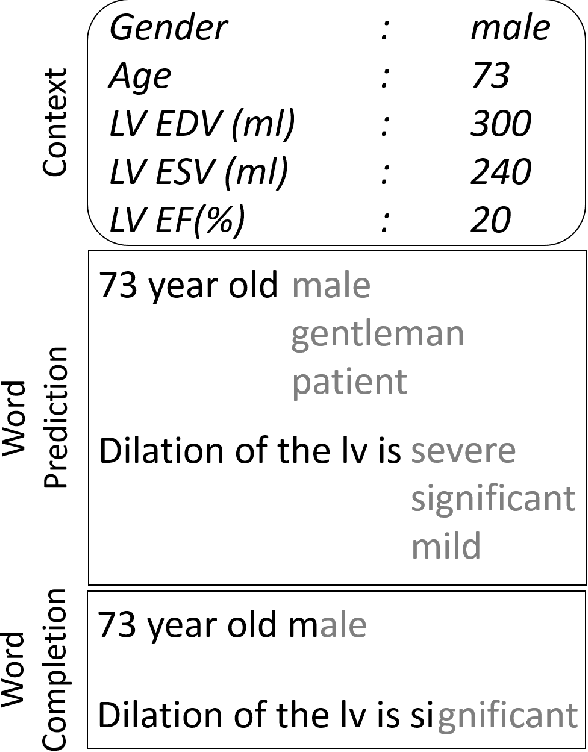
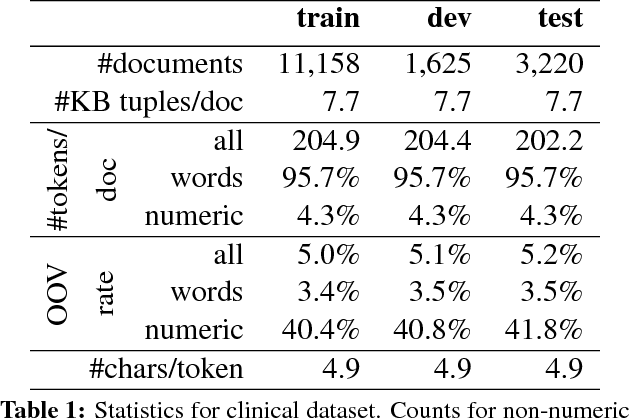
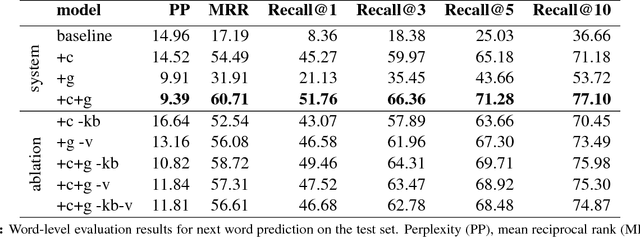
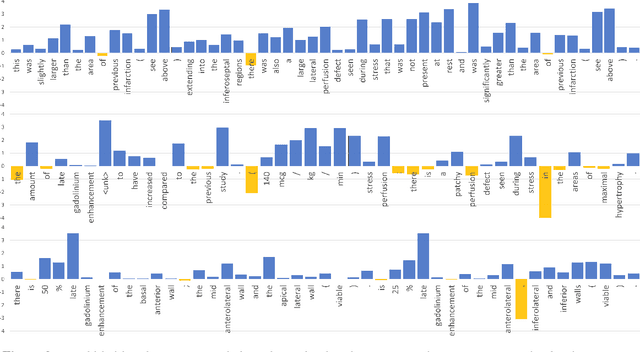
Assisted text input techniques can save time and effort and improve text quality. In this paper, we investigate how grounded and conditional extensions to standard neural language models can bring improvements in the tasks of word prediction and completion. These extensions incorporate a structured knowledge base and numerical values from the text into the context used to predict the next word. Our automated evaluation on a clinical dataset shows extended models significantly outperform standard models. Our best system uses both conditioning and grounding, because of their orthogonal benefits. For word prediction with a list of 5 suggestions, it improves recall from 25.03% to 71.28% and for word completion it improves keystroke savings from 34.35% to 44.81%, where theoretical bound for this dataset is 58.78%. We also perform a qualitative investigation of how models with lower perplexity occasionally fare better at the tasks. We found that at test time numbers have more influence on the document level than on individual word probabilities.
Numerically Grounded Language Models for Semantic Error Correction
Aug 14, 2016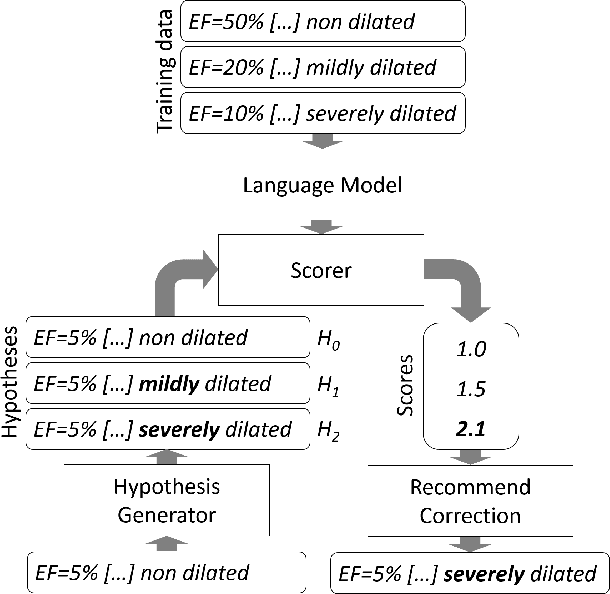

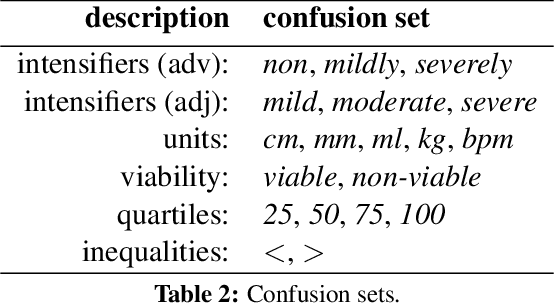
Semantic error detection and correction is an important task for applications such as fact checking, speech-to-text or grammatical error correction. Current approaches generally focus on relatively shallow semantics and do not account for numeric quantities. Our approach uses language models grounded in numbers within the text. Such groundings are easily achieved for recurrent neural language model architectures, which can be further conditioned on incomplete background knowledge bases. Our evaluation on clinical reports shows that numerical grounding improves perplexity by 33% and F1 for semantic error correction by 5 points when compared to ungrounded approaches. Conditioning on a knowledge base yields further improvements.
A Persona-Based Neural Conversation Model
Jun 08, 2016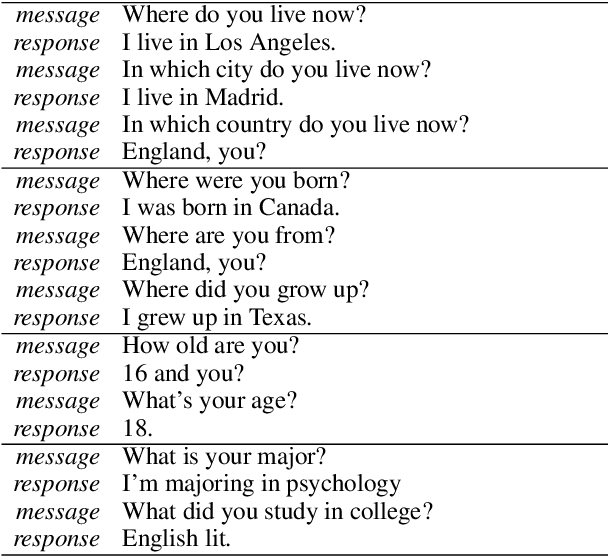
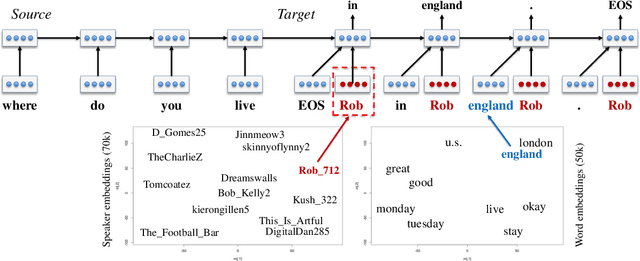

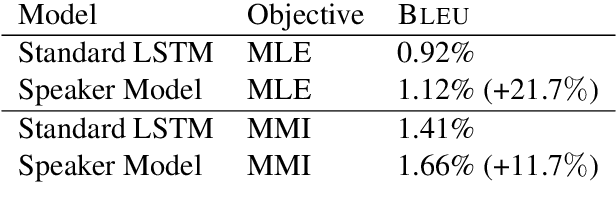
We present persona-based models for handling the issue of speaker consistency in neural response generation. A speaker model encodes personas in distributed embeddings that capture individual characteristics such as background information and speaking style. A dyadic speaker-addressee model captures properties of interactions between two interlocutors. Our models yield qualitative performance improvements in both perplexity and BLEU scores over baseline sequence-to-sequence models, with similar gains in speaker consistency as measured by human judges.