 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisembodied Machine Learning: On the Illusion of Objectivity in NLP
Jan 28, 2021Machine Learning seeks to identify and encode bodies of knowledge within provided datasets. However, data encodes subjective content, which determines the possible outcomes of the models trained on it. Because such subjectivity enables marginalisation of parts of society, it is termed (social) `bias' and sought to be removed. In this paper, we contextualise this discourse of bias in the ML community against the subjective choices in the development process. Through a consideration of how choices in data and model development construct subjectivity, or biases that are represented in a model, we argue that addressing and mitigating biases is near-impossible. This is because both data and ML models are objects for which meaning is made in each step of the development pipeline, from data selection over annotation to model training and analysis. Accordingly, we find the prevalent discourse of bias limiting in its ability to address social marginalisation. We recommend to be conscientious of this, and to accept that de-biasing methods only correct for a fraction of biases.
Domain Transfer in Dialogue Systems without Turn-Level Supervision
Sep 16, 2019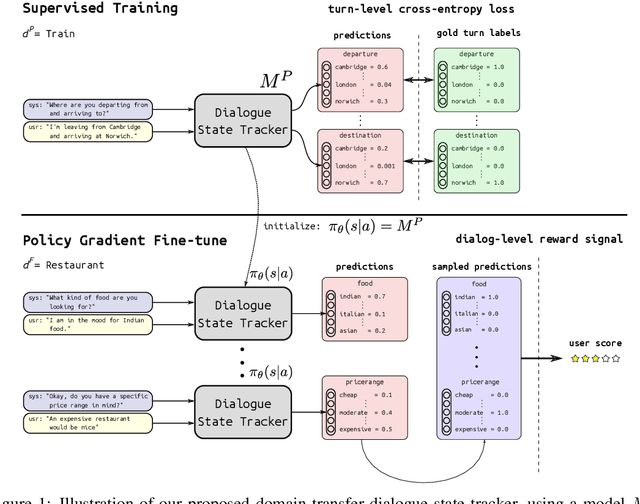
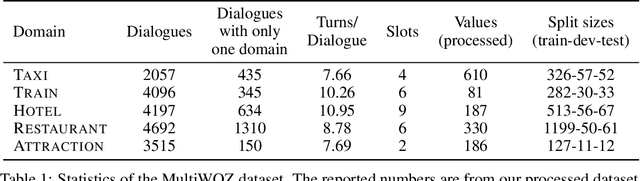
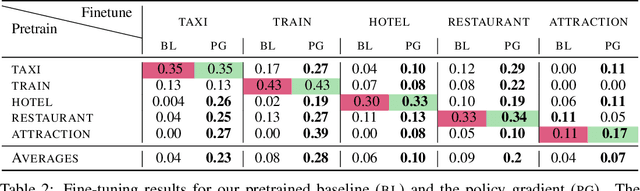
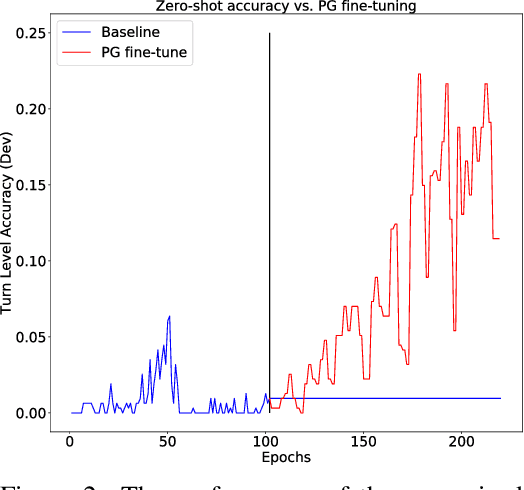
Task oriented dialogue systems rely heavily on specialized dialogue state tracking (DST) modules for dynamically predicting user intent throughout the conversation. State-of-the-art DST models are typically trained in a supervised manner from manual annotations at the turn level. However, these annotations are costly to obtain, which makes it difficult to create accurate dialogue systems for new domains. To address these limitations, we propose a method, based on reinforcement learning, for transferring DST models to new domains without turn-level supervision. Across several domains, our experiments show that this method quickly adapts off-the-shelf models to new domains and performs on par with models trained with turn-level supervision. We also show our method can improve models trained using turn-level supervision by subsequent fine-tuning optimization toward dialog-level rewards.
Learning what to share between loosely related tasks
Jan 16, 2018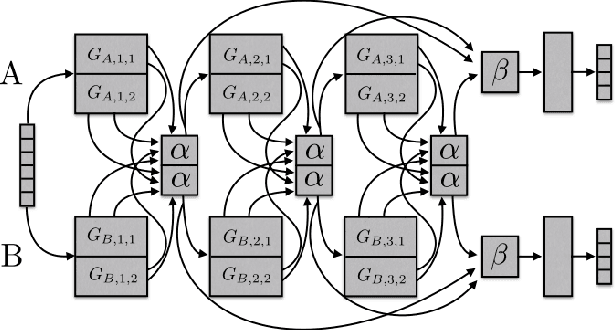

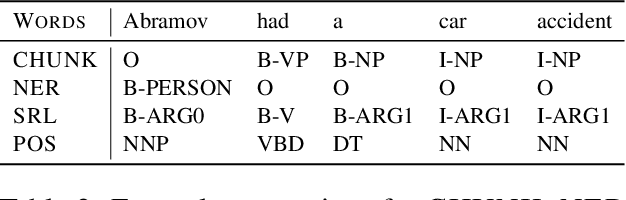
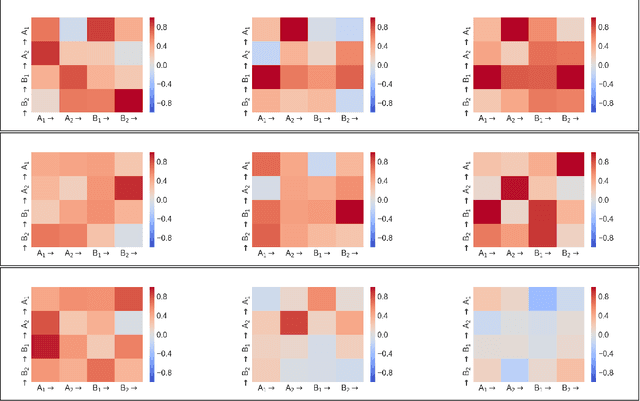
Multi-task learning is motivated by the observation that humans bring to bear what they know about related problems when solving new ones. Similarly, deep neural networks can profit from related tasks by sharing parameters with other networks. However, humans do not consciously decide to transfer knowledge between tasks. In Natural Language Processing (NLP), it is hard to predict if sharing will lead to improvements, particularly if tasks are only loosely related. To overcome this, we introduce Sluice Networks, a general framework for multi-task learning where trainable parameters control the amount of sharing. Our framework generalizes previous proposals in enabling sharing of all combinations of subspaces, layers, and skip connections. We perform experiments on three task pairs, and across seven different domains, using data from OntoNotes 5.0, and achieve up to 15% average error reductions over common approaches to multi-task learning. We show that a) label entropy is predictive of gains in sluice networks, confirming findings for hard parameter sharing and b) while sluice networks easily fit noise, they are robust across domains in practice.
Identifying beneficial task relations for multi-task learning in deep neural networks
Feb 27, 2017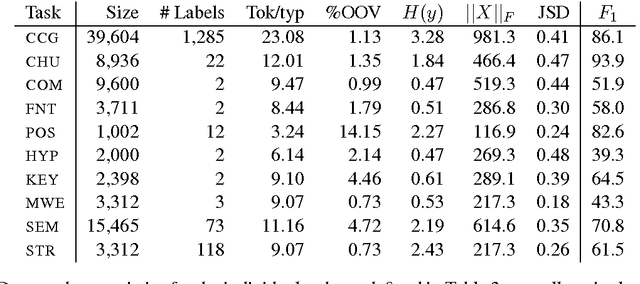
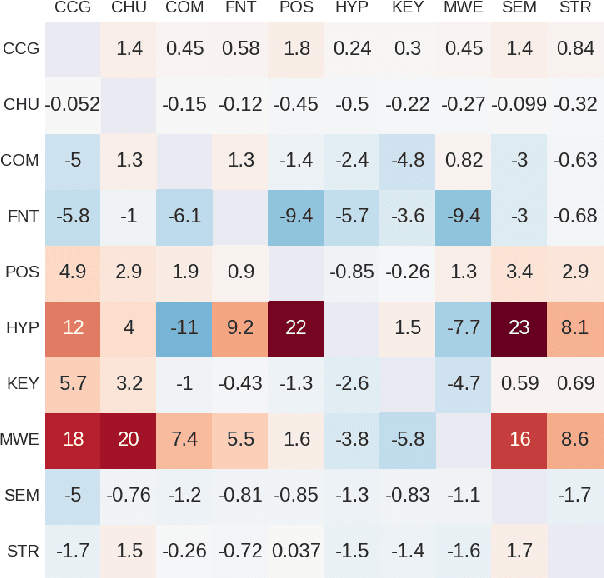
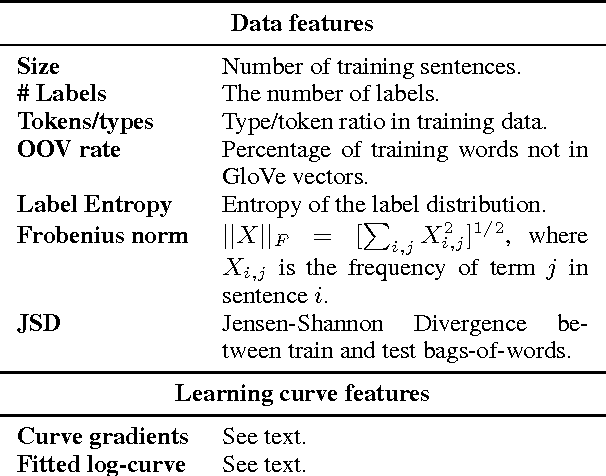
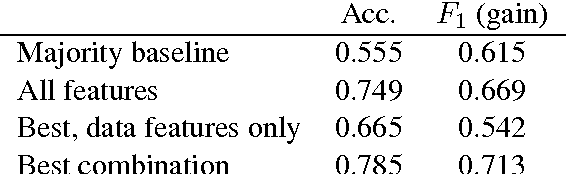
Multi-task learning (MTL) in deep neural networks for NLP has recently received increasing interest due to some compelling benefits, including its potential to efficiently regularize models and to reduce the need for labeled data. While it has brought significant improvements in a number of NLP tasks, mixed results have been reported, and little is known about the conditions under which MTL leads to gains in NLP. This paper sheds light on the specific task relations that can lead to gains from MTL models over single-task setups.