 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning what to share between loosely related tasks
Paper and Code
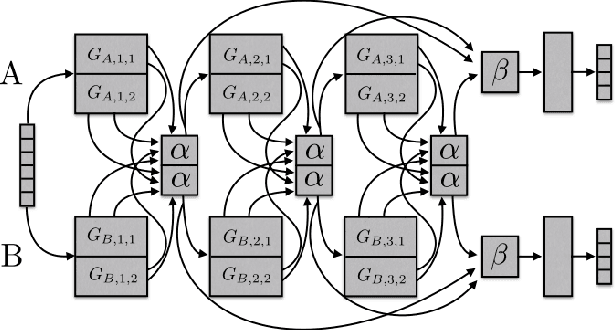

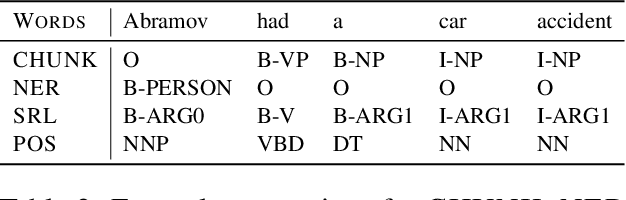
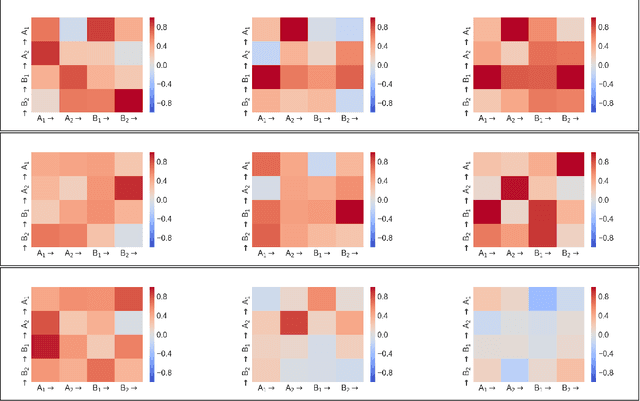
Multi-task learning is motivated by the observation that humans bring to bear what they know about related problems when solving new ones. Similarly, deep neural networks can profit from related tasks by sharing parameters with other networks. However, humans do not consciously decide to transfer knowledge between tasks. In Natural Language Processing (NLP), it is hard to predict if sharing will lead to improvements, particularly if tasks are only loosely related. To overcome this, we introduce Sluice Networks, a general framework for multi-task learning where trainable parameters control the amount of sharing. Our framework generalizes previous proposals in enabling sharing of all combinations of subspaces, layers, and skip connections. We perform experiments on three task pairs, and across seven different domains, using data from OntoNotes 5.0, and achieve up to 15% average error reductions over common approaches to multi-task learning. We show that a) label entropy is predictive of gains in sluice networks, confirming findings for hard parameter sharing and b) while sluice networks easily fit noise, they are robust across domains in practice.