 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALE : Concept-Aligned Embeddings for Both Within-Lemma and Inter-Lemma Sense Differentiation
Aug 06, 2025Lexical semantics is concerned with both the multiple senses a word can adopt in different contexts, and the semantic relations that exist between meanings of different words. To investigate them, Contextualized Language Models are a valuable tool that provides context-sensitive representations that can be used to investigate lexical meaning. Recent works like XL-LEXEME have leveraged the task of Word-in-Context to fine-tune them to get more semantically accurate representations, but Word-in-Context only compares occurrences of the same lemma, limiting the range of captured information. In this paper, we propose an extension, Concept Differentiation, to include inter-words scenarios. We provide a dataset for this task, derived from SemCor data. Then we fine-tune several representation models on this dataset. We call these models Concept-Aligned Embeddings (CALE). By challenging our models and other models on various lexical semantic tasks, we demonstrate that the proposed models provide efficient multi-purpose representations of lexical meaning that reach best performances in our experiments. We also show that CALE's fine-tuning brings valuable changes to the spatial organization of embeddings.
To Word Senses and Beyond: Inducing Concepts with Contextualized Language Models
Jun 28, 2024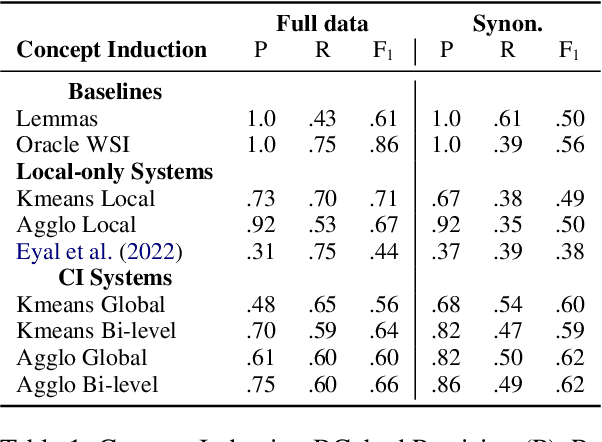
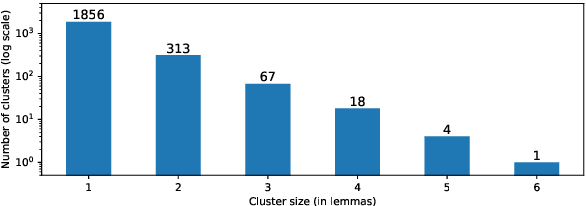
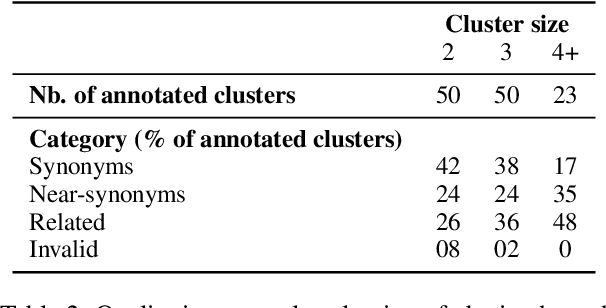
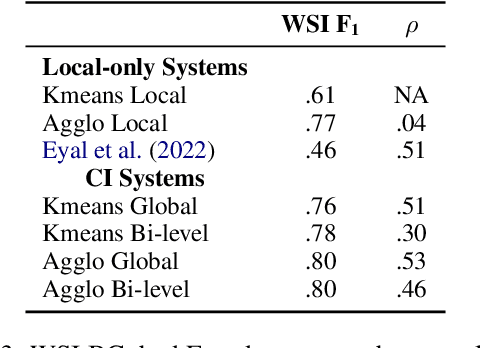
Polysemy and synonymy are two crucial interrelated facets of lexical ambiguity. While both phenomena have been studied extensively in NLP, leading to dedicated systems, they are often been considered independently. While many tasks dealing with polysemy (e.g. Word Sense Disambiguiation or Induction) highlight the role of a word's senses, the study of synonymy is rooted in the study of concepts, i.e. meaning shared across the lexicon. In this paper, we introduce Concept Induction, the unsupervised task of learning a soft clustering among words that defines a set of concepts directly from data. This task generalizes that of Word Sense Induction. We propose a bi-level approach to Concept Induction that leverages both a local lemma-centric view and a global cross-lexicon perspective to induce concepts. We evaluate the obtained clustering on SemCor's annotated data and obtain good performances (BCubed F1 above 0.60). We find that the local and the global levels are mutually beneficial to induce concepts and also senses in our setting. Finally, we create static embeddings representing our induced concepts and use them on the Word-in-Context task, obtaining competitive performances with the State-of-the-Art.
A Tale of Two Laws of Semantic Change: Predicting Synonym Changes with Distributional Semantic Models
May 30, 2023



Lexical Semantic Change is the study of how the meaning of words evolves through time. Another related question is whether and how lexical relations over pairs of words, such as synonymy, change over time. There are currently two competing, apparently opposite hypotheses in the historical linguistic literature regarding how synonymous words evolve: the Law of Differentiation (LD) argues that synonyms tend to take on different meanings over time, whereas the Law of Parallel Change (LPC) claims that synonyms tend to undergo the same semantic change and therefore remain synonyms. So far, there has been little research using distributional models to assess to what extent these laws apply on historical corpora. In this work, we take a first step toward detecting whether LD or LPC operates for given word pairs. After recasting the problem into a more tractable task, we combine two linguistic resources to propose the first complete evaluation framework on this problem and provide empirical evidence in favor of a dominance of LD. We then propose various computational approaches to the problem using Distributional Semantic Models and grounded in recent literature on Lexical Semantic Change detection. Our best approaches achieve a balanced accuracy above 0.6 on our dataset. We discuss challenges still faced by these approaches, such as polysemy or the potential confusion between synonymy and hypernymy.
Do Language Models Know the Way to Rome?
Sep 16, 2021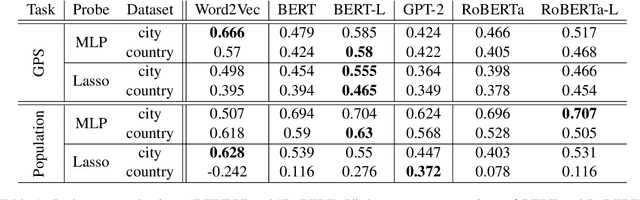
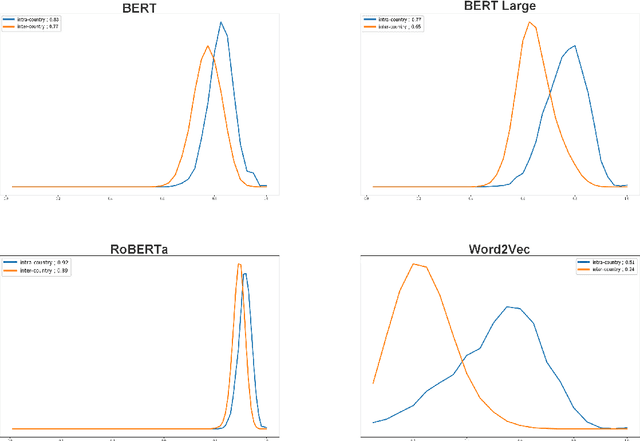

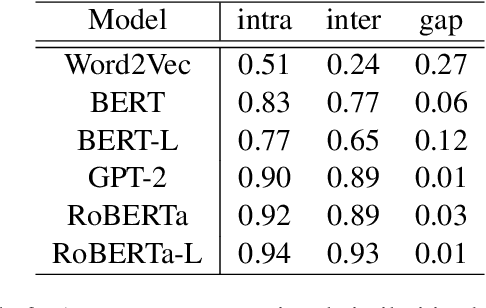
The global geometry of language models is important for a range of applications, but language model probes tend to evaluate rather local relations, for which ground truths are easily obtained. In this paper we exploit the fact that in geography, ground truths are available beyond local relations. In a series of experiments, we evaluate the extent to which language model representations of city and country names are isomorphic to real-world geography, e.g., if you tell a language model where Paris and Berlin are, does it know the way to Rome? We find that language models generally encode limited geographic information, but with larger models performing the best, suggesting that geographic knowledge can be induced from higher-order co-occurrence statistics.