 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexTime: A Benchmark for Temporal Ordering of Legal Events
Jun 04, 2025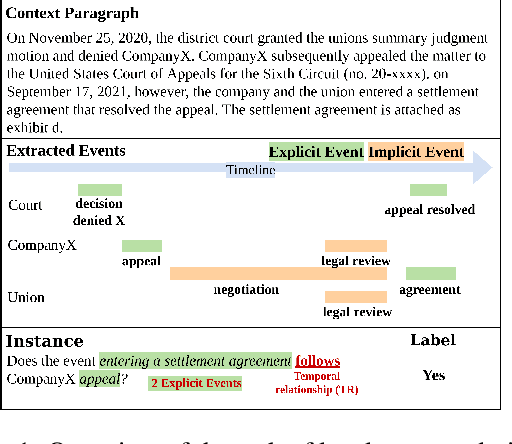
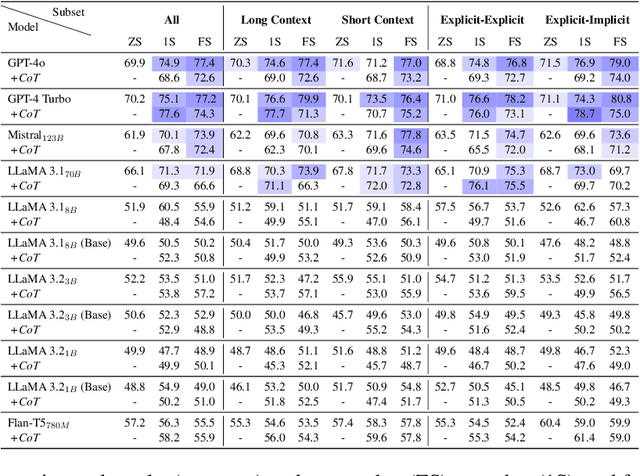
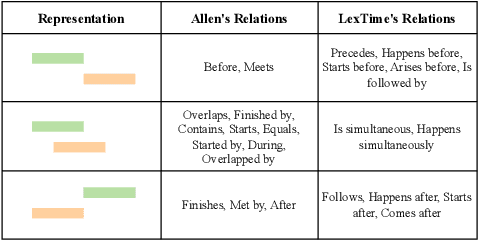
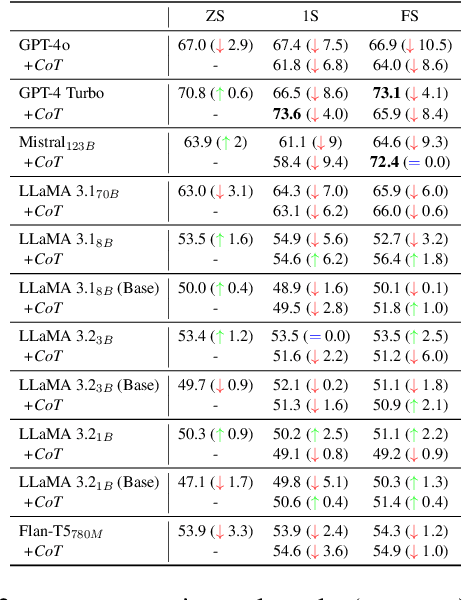
Temporal reasoning in legal texts is important for applications like case law analysis and compliance monitoring. However, existing datasets lack expert language evaluation, leaving a gap in understanding how LLMs manage event ordering in legal contexts. We introduce LexTime, the first dataset designed to evaluate LLMs' event ordering capabilities in legal language, consisting of 512 instances from U.S. Federal Complaints with annotated event pairs and their temporal relations. Our findings show that (1) LLMs are more accurate on legal event ordering than on narrative (up to +10.5%); (2) longer input contexts and implicit events boost accuracy, reaching 80.8% for implicit-explicit event pairs; (3) legal linguistic complexities and nested clauses remain a challenge. We investigate how context length, explicit vs implicit event pairs, and legal language features affect model performance, demonstrating the need for specific modeling strategies to enhance temporal event reasoning.
When Fairness Isn't Statistical: The Limits of Machine Learning in Evaluating Legal Reasoning
Jun 04, 2025Legal decisions are increasingly evaluated for fairness, consistency, and bias using machine learning (ML) techniques. In high-stakes domains like refugee adjudication, such methods are often applied to detect disparities in outcomes. Yet it remains unclear whether statistical methods can meaningfully assess fairness in legal contexts shaped by discretion, normative complexity, and limited ground truth. In this paper, we empirically evaluate three common ML approaches (feature-based analysis, semantic clustering, and predictive modeling) on a large, real-world dataset of 59,000+ Canadian refugee decisions (AsyLex). Our experiments show that these methods produce divergent and sometimes contradictory signals, that predictive modeling often depends on contextual and procedural features rather than legal features, and that semantic clustering fails to capture substantive legal reasoning. We show limitations of statistical fairness evaluation, challenge the assumption that statistical regularity equates to fairness, and argue that current computational approaches fall short of evaluating fairness in legally discretionary domains. We argue that evaluating fairness in law requires methods grounded not only in data, but in legal reasoning and institutional context.
Engineering Conversational Search Systems: A Review of Applications, Architectures, and Functional Components
Jul 01, 2024Conversational search systems enable information retrieval via natural language interactions, with the goal of maximizing users' information gain over multiple dialogue turns. The increasing prevalence of conversational interfaces adopting this search paradigm challenges traditional information retrieval approaches, stressing the importance of better understanding the engineering process of developing these systems. We undertook a systematic literature review to investigate the links between theoretical studies and technical implementations of conversational search systems. Our review identifies real-world application scenarios, system architectures, and functional components. We consolidate our results by presenting a layered architecture framework and explaining the core functions of conversational search systems. Furthermore, we reflect on our findings in light of the rapid progress in large language models, discussing their capabilities, limitations, and directions for future research.
Do Language Models Learn about Legal Entity Types during Pretraining?
Oct 19, 2023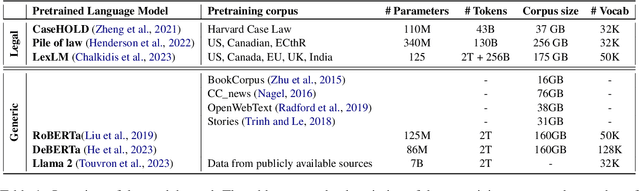
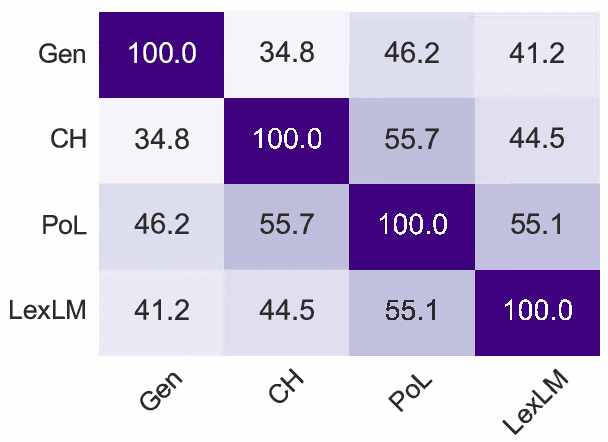
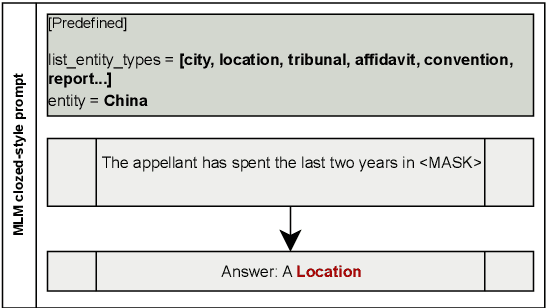
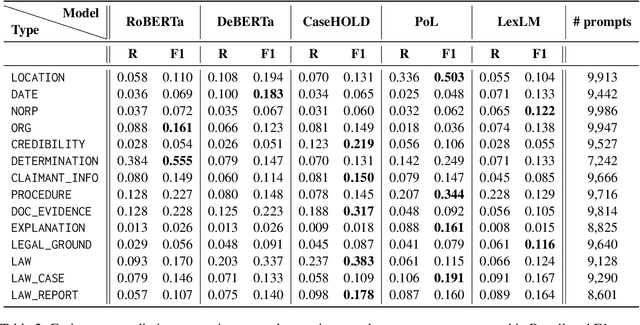
Language Models (LMs) have proven their ability to acquire diverse linguistic knowledge during the pretraining phase, potentially serving as a valuable source of incidental supervision for downstream tasks. However, there has been limited research conducted on the retrieval of domain-specific knowledge, and specifically legal knowledge. We propose to explore the task of Entity Typing, serving as a proxy for evaluating legal knowledge as an essential aspect of text comprehension, and a foundational task to numerous downstream legal NLP applications. Through systematic evaluation and analysis and two types of prompting (cloze sentences and QA-based templates) and to clarify the nature of these acquired cues, we compare diverse types and lengths of entities both general and domain-specific entities, semantics or syntax signals, and different LM pretraining corpus (generic and legal-oriented) and architectures (encoder BERT-based and decoder-only with Llama2). We show that (1) Llama2 performs well on certain entities and exhibits potential for substantial improvement with optimized prompt templates, (2) law-oriented LMs show inconsistent performance, possibly due to variations in their training corpus, (3) LMs demonstrate the ability to type entities even in the case of multi-token entities, (4) all models struggle with entities belonging to sub-domains of the law (5) Llama2 appears to frequently overlook syntactic cues, a shortcoming less present in BERT-based architectures.
Fair Models in Credit: Intersectional Discrimination and the Amplification of Inequity
Aug 01, 2023
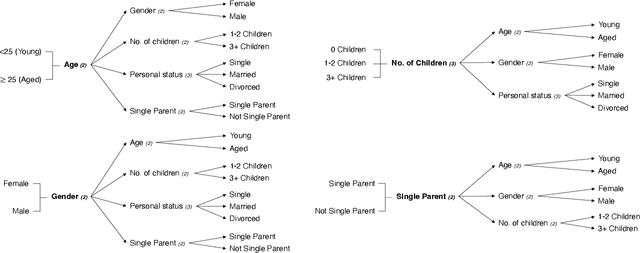


The increasing usage of new data sources and machine learning (ML) technology in credit modeling raises concerns with regards to potentially unfair decision-making that rely on protected characteristics (e.g., race, sex, age) or other socio-economic and demographic data. The authors demonstrate the impact of such algorithmic bias in the microfinance context. Difficulties in assessing credit are disproportionately experienced among vulnerable groups, however, very little is known about inequities in credit allocation between groups defined, not only by single, but by multiple and intersecting social categories. Drawing from the intersectionality paradigm, the study examines intersectional horizontal inequities in credit access by gender, age, marital status, single parent status and number of children. This paper utilizes data from the Spanish microfinance market as its context to demonstrate how pluralistic realities and intersectional identities can shape patterns of credit allocation when using automated decision-making systems. With ML technology being oblivious to societal good or bad, we find that a more thorough examination of intersectionality can enhance the algorithmic fairness lens to more authentically empower action for equitable outcomes and present a fairer path forward. We demonstrate that while on a high-level, fairness may exist superficially, unfairness can exacerbate at lower levels given combinatorial effects; in other words, the core fairness problem may be more complicated than current literature demonstrates. We find that in addition to legally protected characteristics, sensitive attributes such as single parent status and number of children can result in imbalanced harm. We discuss the implications of these findings for the financial services industry.
The Double-Edged Sword of Big Data and Information Technology for the Disadvantaged: A Cautionary Tale from Open Banking
Aug 01, 2023
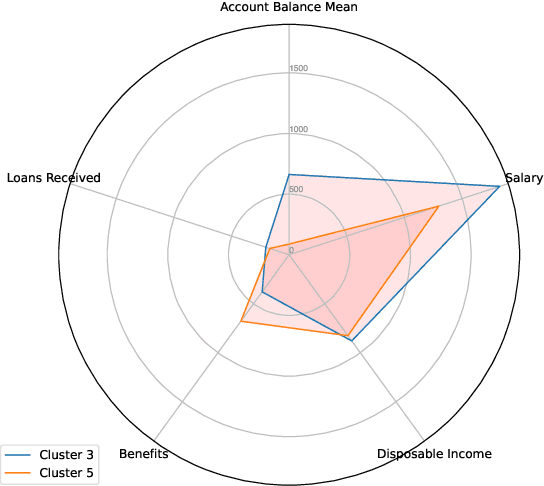
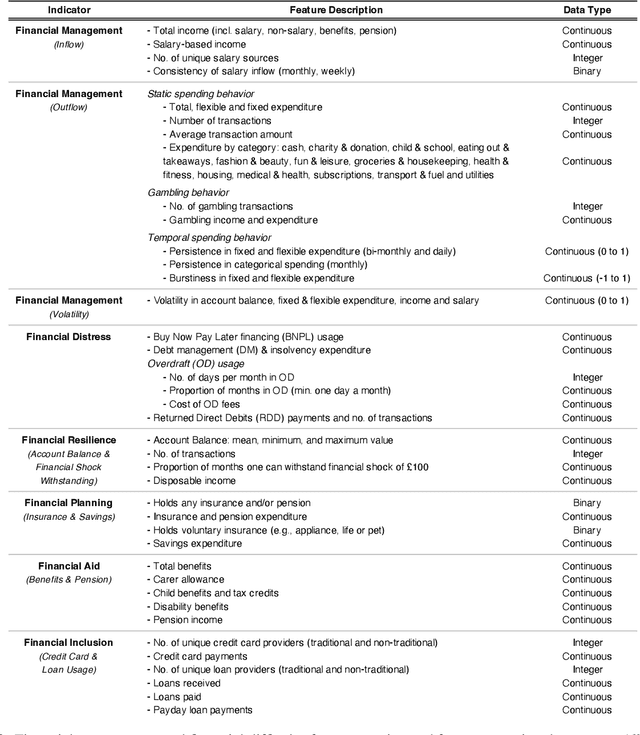
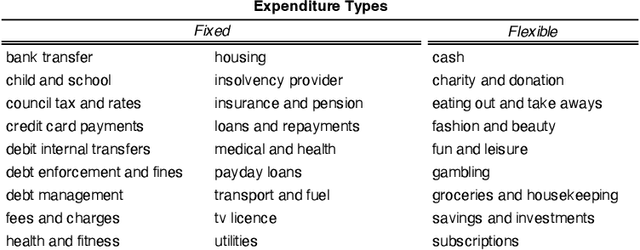
This research article analyses and demonstrates the hidden implications for fairness of seemingly neutral data coupled with powerful technology, such as machine learning (ML), using Open Banking as an example. Open Banking has ignited a revolution in financial services, opening new opportunities for customer acquisition, management, retention, and risk assessment. However, the granularity of transaction data holds potential for harm where unnoticed proxies for sensitive and prohibited characteristics may lead to indirect discrimination. Against this backdrop, we investigate the dimensions of financial vulnerability (FV), a global concern resulting from COVID-19 and rising inflation. Specifically, we look to understand the behavioral elements leading up to FV and its impact on at-risk, disadvantaged groups through the lens of fair interpretation. Using a unique dataset from a UK FinTech lender, we demonstrate the power of fine-grained transaction data while simultaneously cautioning its safe usage. Three ML classifiers are compared in predicting the likelihood of FV, and groups exhibiting different magnitudes and forms of FV are identified via clustering to highlight the effects of feature combination. Our results indicate that engineered features of financial behavior can be predictive of omitted personal information, particularly sensitive or protected characteristics, shedding light on the hidden dangers of Open Banking data. We discuss the implications and conclude fairness via unawareness is ineffective in this new technological environment.
Automated Refugee Case Analysis: An NLP Pipeline for Supporting Legal Practitioners
May 24, 2023In this paper, we introduce an end-to-end pipeline for retrieving, processing, and extracting targeted information from legal cases. We investigate an under-studied legal domain with a case study on refugee law in Canada. Searching case law for past similar cases is a key part of legal work for both lawyers and judges, the potential end-users of our prototype. While traditional named-entity recognition labels such as dates provide meaningful information in legal work, we propose to extend existing models and retrieve a total of 19 useful categories of items from refugee cases. After creating a novel data set of cases, we perform information extraction based on state-of-the-art neural named-entity recognition (NER). We test different architectures including two transformer models, using contextual and non-contextual embeddings, and compare general purpose versus domain-specific pre-training. The results demonstrate that models pre-trained on legal data perform best despite their smaller size, suggesting that domain matching had a larger effect than network architecture. We achieve a F1 score above 90% on five of the targeted categories and over 80% on four further categories.
Experiential AI
Aug 06, 2019
Experiential AI is proposed as a new research agenda in which artists and scientists come together to dispel the mystery of algorithms and make their mechanisms vividly apparent. It addresses the challenge of finding novel ways of opening up the field of artificial intelligence to greater transparency and collaboration between human and machine. The hypothesis is that art can mediate between computer code and human comprehension to overcome the limitations of explanations in and for AI systems. Artists can make the boundaries of systems visible and offer novel ways to make the reasoning of AI transparent and decipherable. Beyond this, artistic practice can explore new configurations of humans and algorithms, mapping the terrain of inter-agencies between people and machines. This helps to viscerally understand the complex causal chains in environments with AI components, including questions about what data to collect or who to collect it about, how the algorithms are chosen, commissioned and configured or how humans are conditioned by their participation in algorithmic processes.
Applying Strategic Multiagent Planning to Real-World Travel Sharing Problems
Jan 02, 2013


Travel sharing, i.e., the problem of finding parts of routes which can be shared by several travellers with different points of departure and destinations, is a complex multiagent problem that requires taking into account individual agents' preferences to come up with mutually acceptable joint plans. In this paper, we apply state-of-the-art planning techniques to real-world public transportation data to evaluate the feasibility of multiagent planning techniques in this domain. The potential application value of improving travel sharing technology has great application value due to its ability to reduce the environmental impact of travelling while providing benefits to travellers at the same time. We propose a three-phase algorithm that utilises performant single-agent planners to find individual plans in a simplified domain first, then merges them using a best-response planner which ensures resulting solutions are individually rational, and then maps the resulting plan onto the full temporal planning domain to schedule actual journeys. The evaluation of our algorithm on real-world, multi-modal public transportation data for the United Kingdom shows linear scalability both in the scenario size and in the number of agents, where trade-offs have to be made between total cost improvement, the percentage of feasible timetables identified for journeys, and the prolongation of these journeys. Our system constitutes the first implementation of strategic multiagent planning algorithms in large-scale domains and provides insights into the engineering process of translating general domain-independent multiagent planning algorithms to real-world applications.