 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Double-Edged Sword of Big Data and Information Technology for the Disadvantaged: A Cautionary Tale from Open Banking
Aug 01, 2023
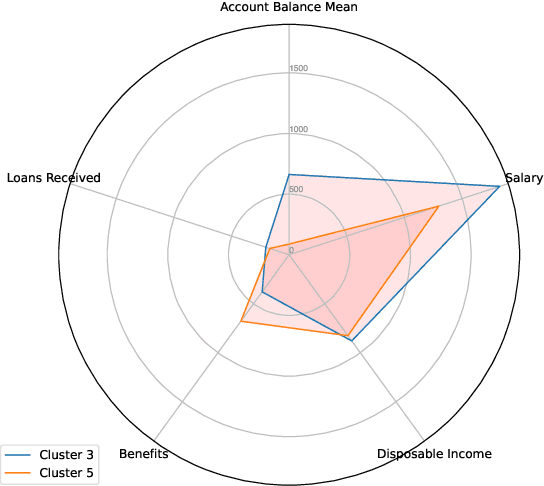
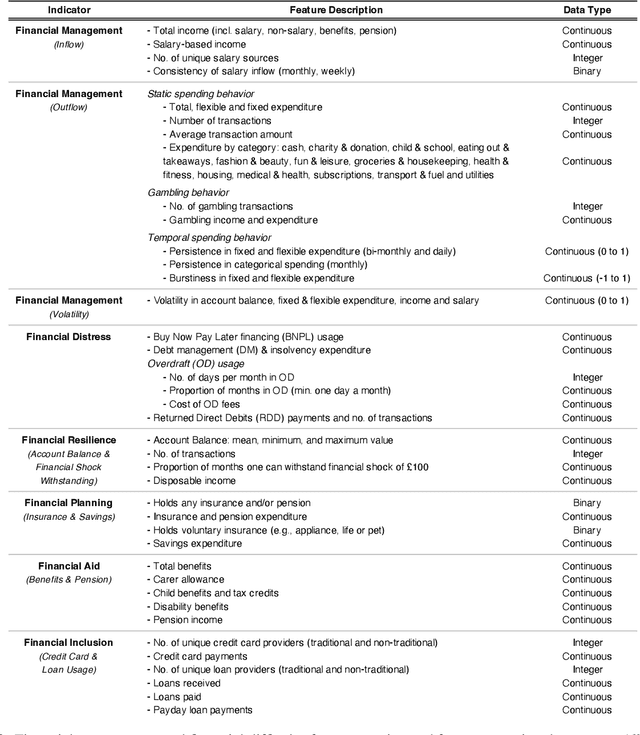
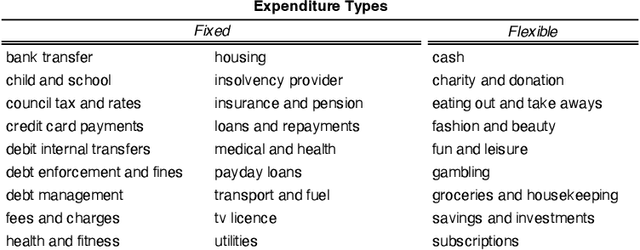
This research article analyses and demonstrates the hidden implications for fairness of seemingly neutral data coupled with powerful technology, such as machine learning (ML), using Open Banking as an example. Open Banking has ignited a revolution in financial services, opening new opportunities for customer acquisition, management, retention, and risk assessment. However, the granularity of transaction data holds potential for harm where unnoticed proxies for sensitive and prohibited characteristics may lead to indirect discrimination. Against this backdrop, we investigate the dimensions of financial vulnerability (FV), a global concern resulting from COVID-19 and rising inflation. Specifically, we look to understand the behavioral elements leading up to FV and its impact on at-risk, disadvantaged groups through the lens of fair interpretation. Using a unique dataset from a UK FinTech lender, we demonstrate the power of fine-grained transaction data while simultaneously cautioning its safe usage. Three ML classifiers are compared in predicting the likelihood of FV, and groups exhibiting different magnitudes and forms of FV are identified via clustering to highlight the effects of feature combination. Our results indicate that engineered features of financial behavior can be predictive of omitted personal information, particularly sensitive or protected characteristics, shedding light on the hidden dangers of Open Banking data. We discuss the implications and conclude fairness via unawareness is ineffective in this new technological environment.
Fair Models in Credit: Intersectional Discrimination and the Amplification of Inequity
Aug 01, 2023
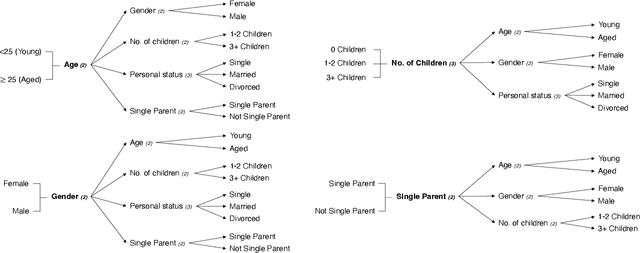


The increasing usage of new data sources and machine learning (ML) technology in credit modeling raises concerns with regards to potentially unfair decision-making that rely on protected characteristics (e.g., race, sex, age) or other socio-economic and demographic data. The authors demonstrate the impact of such algorithmic bias in the microfinance context. Difficulties in assessing credit are disproportionately experienced among vulnerable groups, however, very little is known about inequities in credit allocation between groups defined, not only by single, but by multiple and intersecting social categories. Drawing from the intersectionality paradigm, the study examines intersectional horizontal inequities in credit access by gender, age, marital status, single parent status and number of children. This paper utilizes data from the Spanish microfinance market as its context to demonstrate how pluralistic realities and intersectional identities can shape patterns of credit allocation when using automated decision-making systems. With ML technology being oblivious to societal good or bad, we find that a more thorough examination of intersectionality can enhance the algorithmic fairness lens to more authentically empower action for equitable outcomes and present a fairer path forward. We demonstrate that while on a high-level, fairness may exist superficially, unfairness can exacerbate at lower levels given combinatorial effects; in other words, the core fairness problem may be more complicated than current literature demonstrates. We find that in addition to legally protected characteristics, sensitive attributes such as single parent status and number of children can result in imbalanced harm. We discuss the implications of these findings for the financial services industry.