 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexTime: A Benchmark for Temporal Ordering of Legal Events
Jun 04, 2025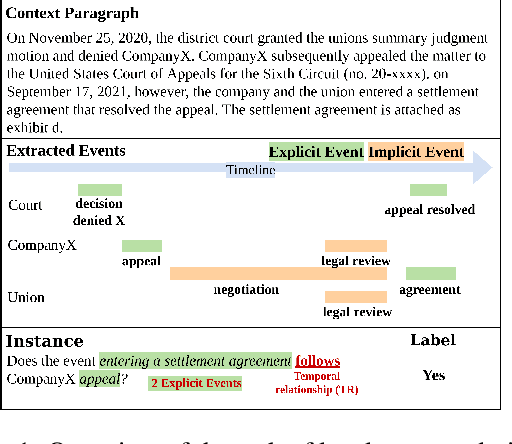
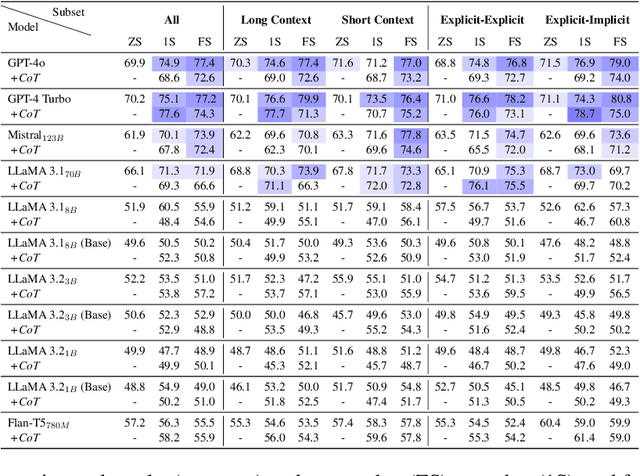
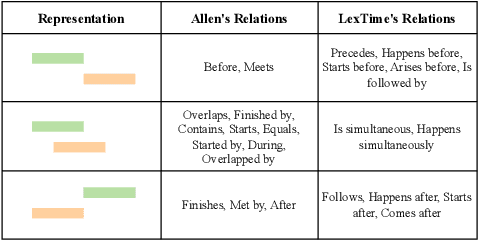
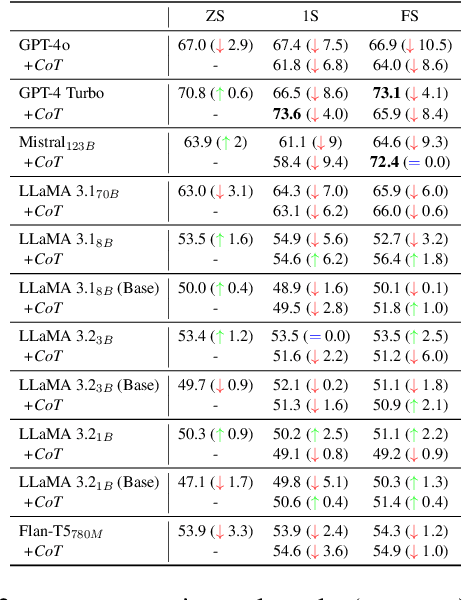
Temporal reasoning in legal texts is important for applications like case law analysis and compliance monitoring. However, existing datasets lack expert language evaluation, leaving a gap in understanding how LLMs manage event ordering in legal contexts. We introduce LexTime, the first dataset designed to evaluate LLMs' event ordering capabilities in legal language, consisting of 512 instances from U.S. Federal Complaints with annotated event pairs and their temporal relations. Our findings show that (1) LLMs are more accurate on legal event ordering than on narrative (up to +10.5%); (2) longer input contexts and implicit events boost accuracy, reaching 80.8% for implicit-explicit event pairs; (3) legal linguistic complexities and nested clauses remain a challenge. We investigate how context length, explicit vs implicit event pairs, and legal language features affect model performance, demonstrating the need for specific modeling strategies to enhance temporal event reasoning.
When Fairness Isn't Statistical: The Limits of Machine Learning in Evaluating Legal Reasoning
Jun 04, 2025Legal decisions are increasingly evaluated for fairness, consistency, and bias using machine learning (ML) techniques. In high-stakes domains like refugee adjudication, such methods are often applied to detect disparities in outcomes. Yet it remains unclear whether statistical methods can meaningfully assess fairness in legal contexts shaped by discretion, normative complexity, and limited ground truth. In this paper, we empirically evaluate three common ML approaches (feature-based analysis, semantic clustering, and predictive modeling) on a large, real-world dataset of 59,000+ Canadian refugee decisions (AsyLex). Our experiments show that these methods produce divergent and sometimes contradictory signals, that predictive modeling often depends on contextual and procedural features rather than legal features, and that semantic clustering fails to capture substantive legal reasoning. We show limitations of statistical fairness evaluation, challenge the assumption that statistical regularity equates to fairness, and argue that current computational approaches fall short of evaluating fairness in legally discretionary domains. We argue that evaluating fairness in law requires methods grounded not only in data, but in legal reasoning and institutional context.
Are We Done with MMLU?
Jun 07, 2024



Maybe not. We identify and analyse errors in the popular Massive Multitask Language Understanding (MMLU) benchmark. Even though MMLU is widely adopted, our analysis demonstrates numerous ground truth errors that obscure the true capabilities of LLMs. For example, we find that 57% of the analysed questions in the Virology subset contain errors. To address this issue, we introduce a comprehensive framework for identifying dataset errors using a novel error taxonomy. Then, we create MMLU-Redux, which is a subset of 3,000 manually re-annotated questions across 30 MMLU subjects. Using MMLU-Redux, we demonstrate significant discrepancies with the model performance metrics that were originally reported. Our results strongly advocate for revising MMLU's error-ridden questions to enhance its future utility and reliability as a benchmark. Therefore, we open up MMLU-Redux for additional annotation https://huggingface.co/datasets/edinburgh-dawg/mmlu-redux.
Do Language Models Learn about Legal Entity Types during Pretraining?
Oct 19, 2023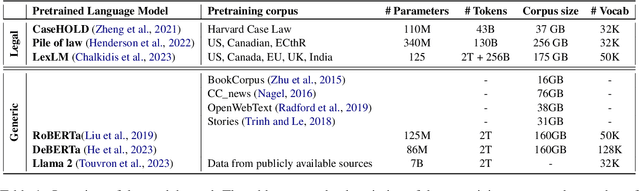
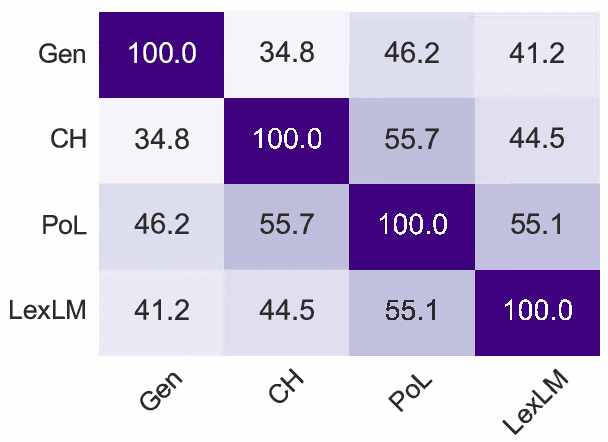
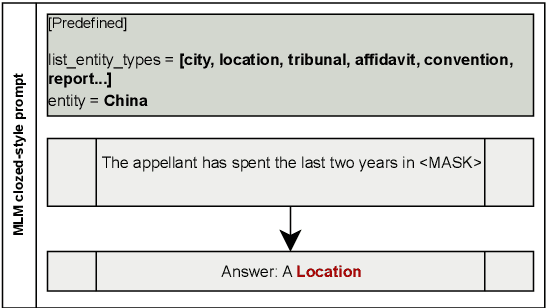
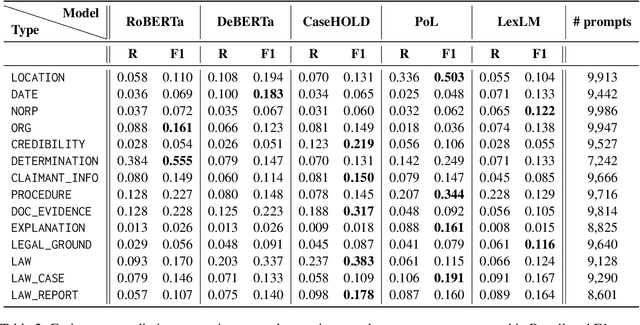
Language Models (LMs) have proven their ability to acquire diverse linguistic knowledge during the pretraining phase, potentially serving as a valuable source of incidental supervision for downstream tasks. However, there has been limited research conducted on the retrieval of domain-specific knowledge, and specifically legal knowledge. We propose to explore the task of Entity Typing, serving as a proxy for evaluating legal knowledge as an essential aspect of text comprehension, and a foundational task to numerous downstream legal NLP applications. Through systematic evaluation and analysis and two types of prompting (cloze sentences and QA-based templates) and to clarify the nature of these acquired cues, we compare diverse types and lengths of entities both general and domain-specific entities, semantics or syntax signals, and different LM pretraining corpus (generic and legal-oriented) and architectures (encoder BERT-based and decoder-only with Llama2). We show that (1) Llama2 performs well on certain entities and exhibits potential for substantial improvement with optimized prompt templates, (2) law-oriented LMs show inconsistent performance, possibly due to variations in their training corpus, (3) LMs demonstrate the ability to type entities even in the case of multi-token entities, (4) all models struggle with entities belonging to sub-domains of the law (5) Llama2 appears to frequently overlook syntactic cues, a shortcoming less present in BERT-based architectures.
Empowering Refugee Claimants and their Lawyers: Using Machine Learning to Examine Decision-Making in Refugee Law
Aug 22, 2023Our project aims at helping and supporting stakeholders in refugee status adjudications, such as lawyers, judges, governing bodies, and claimants, in order to make better decisions through data-driven intelligence and increase the understanding and transparency of the refugee application process for all involved parties. This PhD project has two primary objectives: (1) to retrieve past cases, and (2) to analyze legal decision-making processes on a dataset of Canadian cases. In this paper, we present the current state of our work, which includes a completed experiment on part (1) and ongoing efforts related to part (2). We believe that NLP-based solutions are well-suited to address these challenges, and we investigate the feasibility of automating all steps involved. In addition, we introduce a novel benchmark for future NLP research in refugee law. Our methodology aims to be inclusive to all end-users and stakeholders, with expected benefits including reduced time-to-decision, fairer and more transparent outcomes, and improved decision quality.
Automated Refugee Case Analysis: An NLP Pipeline for Supporting Legal Practitioners
May 24, 2023In this paper, we introduce an end-to-end pipeline for retrieving, processing, and extracting targeted information from legal cases. We investigate an under-studied legal domain with a case study on refugee law in Canada. Searching case law for past similar cases is a key part of legal work for both lawyers and judges, the potential end-users of our prototype. While traditional named-entity recognition labels such as dates provide meaningful information in legal work, we propose to extend existing models and retrieve a total of 19 useful categories of items from refugee cases. After creating a novel data set of cases, we perform information extraction based on state-of-the-art neural named-entity recognition (NER). We test different architectures including two transformer models, using contextual and non-contextual embeddings, and compare general purpose versus domain-specific pre-training. The results demonstrate that models pre-trained on legal data perform best despite their smaller size, suggesting that domain matching had a larger effect than network architecture. We achieve a F1 score above 90% on five of the targeted categories and over 80% on four further categories.