 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Language Models Learn about Legal Entity Types during Pretraining?
Paper and Code
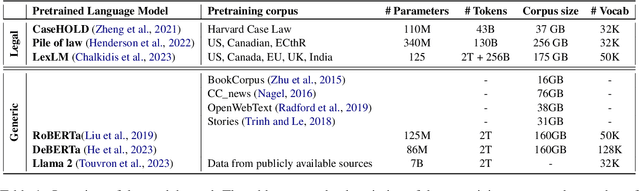
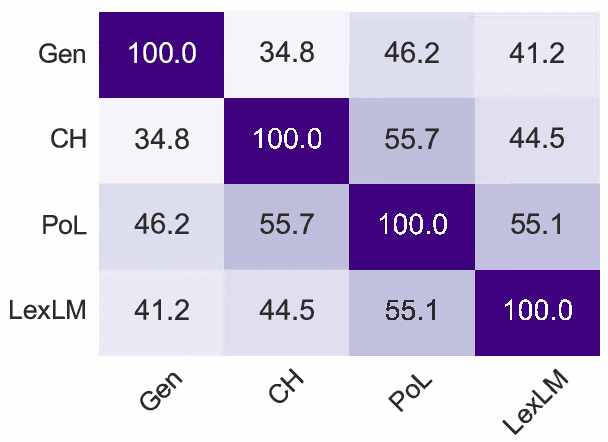
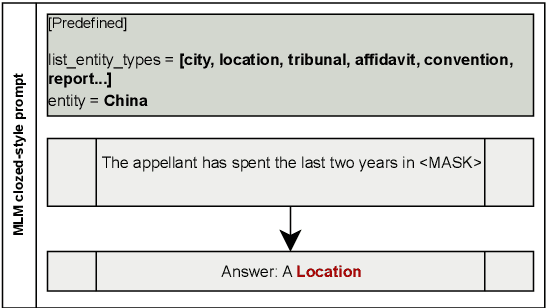
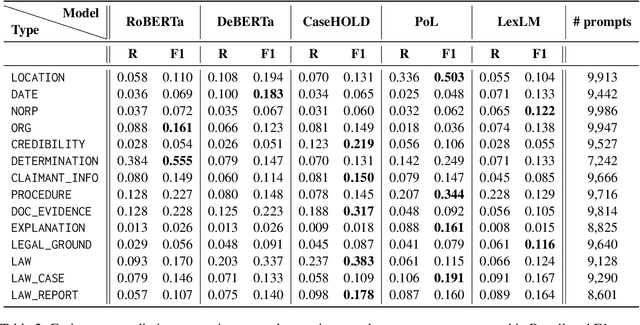
Language Models (LMs) have proven their ability to acquire diverse linguistic knowledge during the pretraining phase, potentially serving as a valuable source of incidental supervision for downstream tasks. However, there has been limited research conducted on the retrieval of domain-specific knowledge, and specifically legal knowledge. We propose to explore the task of Entity Typing, serving as a proxy for evaluating legal knowledge as an essential aspect of text comprehension, and a foundational task to numerous downstream legal NLP applications. Through systematic evaluation and analysis and two types of prompting (cloze sentences and QA-based templates) and to clarify the nature of these acquired cues, we compare diverse types and lengths of entities both general and domain-specific entities, semantics or syntax signals, and different LM pretraining corpus (generic and legal-oriented) and architectures (encoder BERT-based and decoder-only with Llama2). We show that (1) Llama2 performs well on certain entities and exhibits potential for substantial improvement with optimized prompt templates, (2) law-oriented LMs show inconsistent performance, possibly due to variations in their training corpus, (3) LMs demonstrate the ability to type entities even in the case of multi-token entities, (4) all models struggle with entities belonging to sub-domains of the law (5) Llama2 appears to frequently overlook syntactic cues, a shortcoming less present in BERT-based architectures.