 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterexample-Guided Repair of Reinforcement Learning Systems Using Safety Critics
May 24, 2024Naively trained Deep Reinforcement Learning agents may fail to satisfy vital safety constraints. To avoid costly retraining, we may desire to repair a previously trained reinforcement learning agent to obviate unsafe behaviour. We devise a counterexample-guided repair algorithm for repairing reinforcement learning systems leveraging safety critics. The algorithm jointly repairs a reinforcement learning agent and a safety critic using gradient-based constrained optimisation.
Verifying Global Neural Network Specifications using Hyperproperties
Jun 21, 2023

Current approaches to neural network verification focus on specifications that target small regions around known input data points, such as local robustness. Thus, using these approaches, we can not obtain guarantees for inputs that are not close to known inputs. Yet, it is highly likely that a neural network will encounter such truly unseen inputs during its application. We study global specifications that - when satisfied - provide guarantees for all potential inputs. We introduce a hyperproperty formalism that allows for expressing global specifications such as monotonicity, Lipschitz continuity, global robustness, and dependency fairness. Our formalism enables verifying global specifications using existing neural network verification approaches by leveraging capabilities for verifying general computational graphs. Thereby, we extend the scope of guarantees that can be provided using existing methods. Recent success in verifying specific global specifications shows that attaining strong guarantees for all potential data points is feasible.
A Robust Optimisation Perspective on Counterexample-Guided Repair of Neural Networks
Jan 26, 2023



Counterexample-guided repair aims at creating neural networks with mathematical safety guarantees, facilitating the application of neural networks in safety-critical domains. However, whether counterexample-guided repair is guaranteed to terminate remains an open question. We approach this question by showing that counterexample-guided repair can be viewed as a robust optimisation algorithm. While termination guarantees for neural network repair itself remain beyond our reach, we prove termination for more restrained machine learning models and disprove termination in a general setting. We empirically study the practical implications of our theoretical results, demonstrating the suitability of common verifiers and falsifiers for repair despite a disadvantageous theoretical result. Additionally, we use our theoretical insights to devise a novel algorithm for repairing linear regression models, surpassing existing approaches.
DeepOpt: Scalable Specification-based Falsification of Neural Networks using Black-Box Optimization
Jun 03, 2021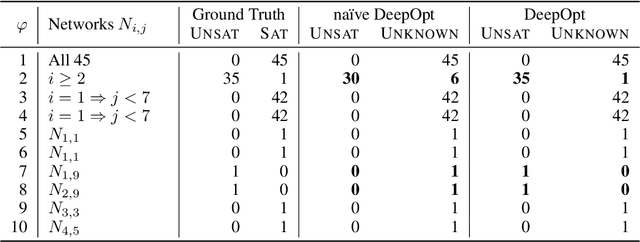
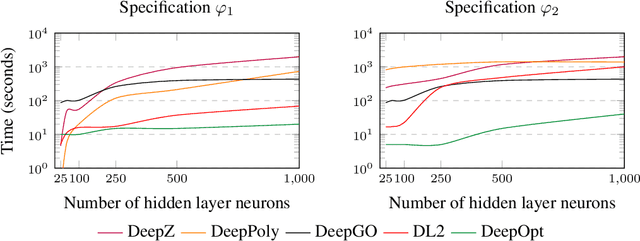

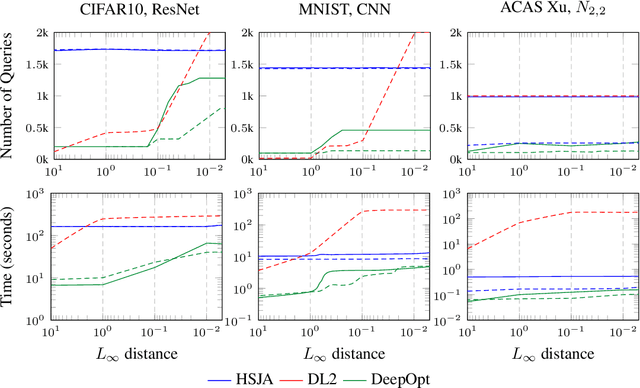
Decisions made by deep neural networks (DNNs) have a tremendous impact on the dependability of the systems that they are embedded into, which is of particular concern in the realm of safety-critical systems. In this paper we consider specification-based falsification of DNNs with the aim to support debugging and repair. We propose DeepOpt, a falsification technique based on black-box optimization, which generates counterexamples from a DNN in a refinement loop. DeepOpt can analyze input-output specifications, which makes it more general than falsification approaches that only support robustness specifications. The key idea is to algebraically combine the DNN with the input and output constraints derived from the specification. We have implemented DeepOpt and evaluated it on DNNs of varying sizes and architectures. Experimental comparisons demonstrate DeepOpt's precision and scalability; in particular, DeepOpt requires very few queries to the DNN.