 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeRecycle: Reclaiming Guarantees from Probabilistic Certificates for Stochastic Dynamical Systems after Change
May 20, 2025



Autonomous systems operating in the real world encounter a range of uncertainties. Probabilistic neural Lyapunov certification is a powerful approach to proving safety of nonlinear stochastic dynamical systems. When faced with changes beyond the modeled uncertainties, e.g., unidentified obstacles, probabilistic certificates must be transferred to the new system dynamics. However, even when the changes are localized in a known part of the state space, state-of-the-art requires complete re-certification, which is particularly costly for neural certificates. We introduce VeRecycle, the first framework to formally reclaim guarantees for discrete-time stochastic dynamical systems. VeRecycle efficiently reuses probabilistic certificates when the system dynamics deviate only in a given subset of states. We present a general theoretical justification and algorithmic implementation. Our experimental evaluation shows scenarios where VeRecycle both saves significant computational effort and achieves competitive probabilistic guarantees in compositional neural control.
Neural Continuous-Time Supermartingale Certificates
Dec 23, 2024



We introduce for the first time a neural-certificate framework for continuous-time stochastic dynamical systems. Autonomous learning systems in the physical world demand continuous-time reasoning, yet existing learnable certificates for probabilistic verification assume discretization of the time continuum. Inspired by the success of training neural Lyapunov certificates for deterministic continuous-time systems and neural supermartingale certificates for stochastic discrete-time systems, we propose a framework that bridges the gap between continuous-time and probabilistic neural certification for dynamical systems under complex requirements. Our method combines machine learning and symbolic reasoning to produce formally certified bounds on the probabilities that a nonlinear system satisfies specifications of reachability, avoidance, and persistence. We present both the theoretical justification and the algorithmic implementation of our framework and showcase its efficacy on popular benchmarks.
In Search of Trees: Decision-Tree Policy Synthesis for Black-Box Systems via Search
Sep 05, 2024



Decision trees, owing to their interpretability, are attractive as control policies for (dynamical) systems. Unfortunately, constructing, or synthesising, such policies is a challenging task. Previous approaches do so by imitating a neural-network policy, approximating a tabular policy obtained via formal synthesis, employing reinforcement learning, or modelling the problem as a mixed-integer linear program. However, these works may require access to a hard-to-obtain accurate policy or a formal model of the environment (within reach of formal synthesis), and may not provide guarantees on the quality or size of the final tree policy. In contrast, we present an approach to synthesise optimal decision-tree policies given a black-box environment and specification, and a discretisation of the tree predicates, where optimality is defined with respect to the number of steps to achieve the goal. Our approach is a specialised search algorithm which systematically explores the (exponentially large) space of decision trees under the given discretisation. The key component is a novel pruning mechanism that significantly reduces the search space. Our approach represents a conceptually novel way of synthesising small decision-tree policies with optimality guarantees even for black-box environments with black-box specifications.
Synthesis of Hierarchical Controllers Based on Deep Reinforcement Learning Policies
Feb 21, 2024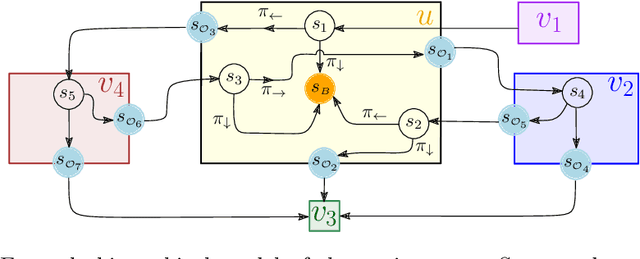
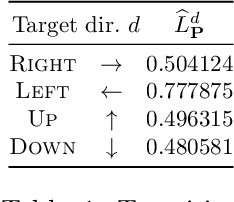
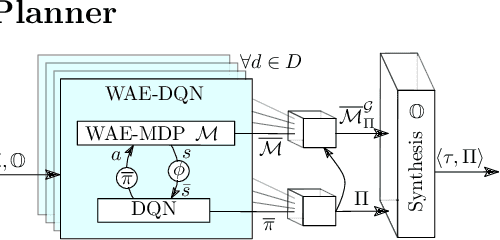
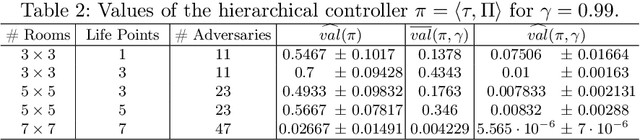
We propose a novel approach to the problem of controller design for environments modeled as Markov decision processes (MDPs). Specifically, we consider a hierarchical MDP a graph with each vertex populated by an MDP called a "room". We first apply deep reinforcement learning (DRL) to obtain low-level policies for each room, scaling to large rooms of unknown structure. We then apply reactive synthesis to obtain a high-level planner that chooses which low-level policy to execute in each room. The central challenge in synthesizing the planner is the need for modeling rooms. We address this challenge by developing a DRL procedure to train concise "latent" policies together with PAC guarantees on their performance. Unlike previous approaches, ours circumvents a model distillation step. Our approach combats sparse rewards in DRL and enables reusability of low-level policies. We demonstrate feasibility in a case study involving agent navigation amid moving obstacles.
Into the unknown: Active monitoring of neural networks
Sep 14, 2020
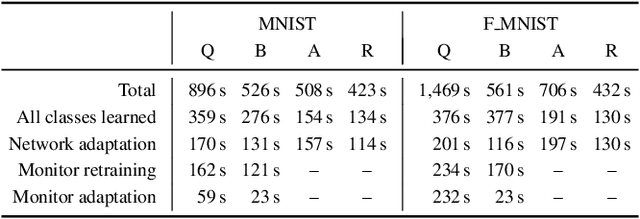
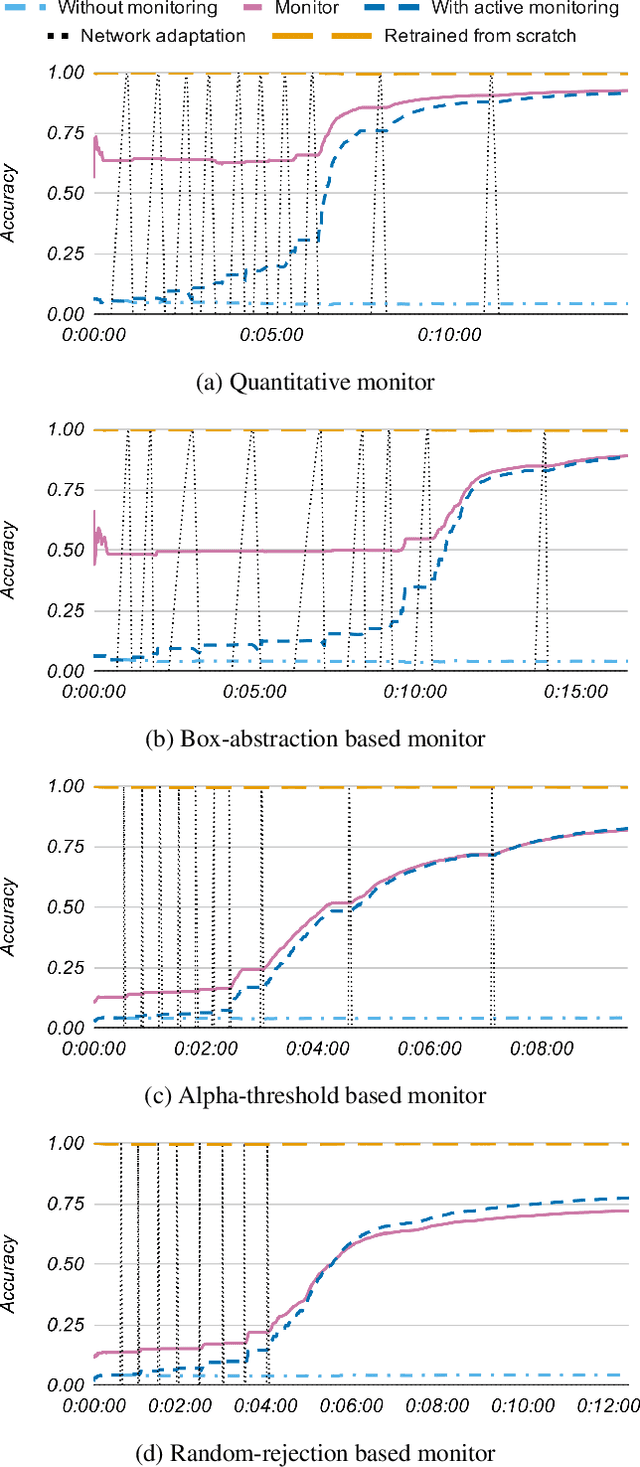
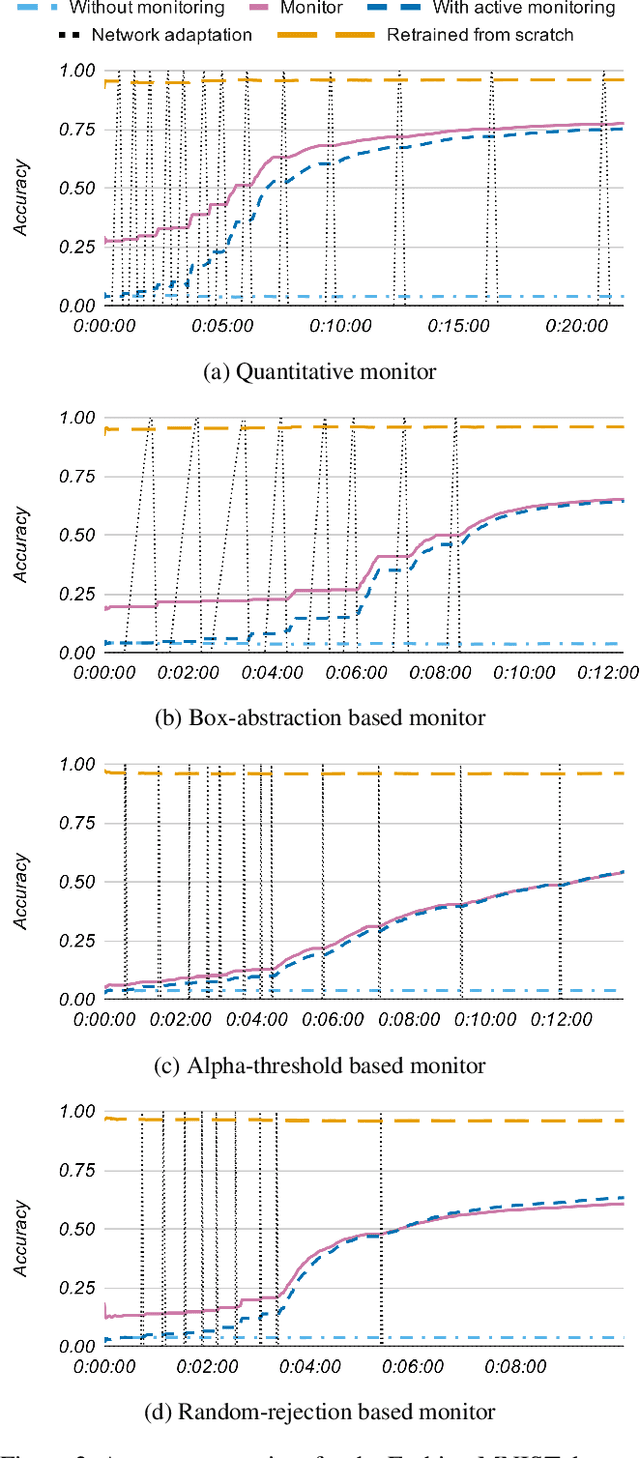
Machine-learning techniques achieve excellent performance in modern applications. In particular, neural networks enable training classifiers, often used in safety-critical applications, to complete a variety of tasks without human supervision. Neural-network models have neither the means to identify what they do not know nor to interact with the human user before making a decision. When deployed in the real world, such models work reliably in scenarios they have seen during training. In unfamiliar situations, however, they can exhibit unpredictable behavior compromising safety of the whole system. We propose an algorithmic framework for active monitoring of neural-network classifiers that allows for their deployment in dynamic environments where unknown input classes appear frequently. Based on quantitative monitoring of the feature layer, we detect novel inputs and ask an authority for labels, thus enabling us to adapt to these novel classes. A neural network wrapped in our framework achieves higher classification accuracy on unknown input classes over time compared to the original standalone model. The typical approach to adapt to unknown input classes is to retrain the neural-network classifier on an augmented training dataset. However, the system is vulnerable before such a dataset is available. Owing to the underlying monitor, we adapt the framework to novel inputs incrementally, thereby improving short-term reliability of the classification.
MurTree: Optimal Classification Trees via Dynamic Programming and Search
Jul 24, 2020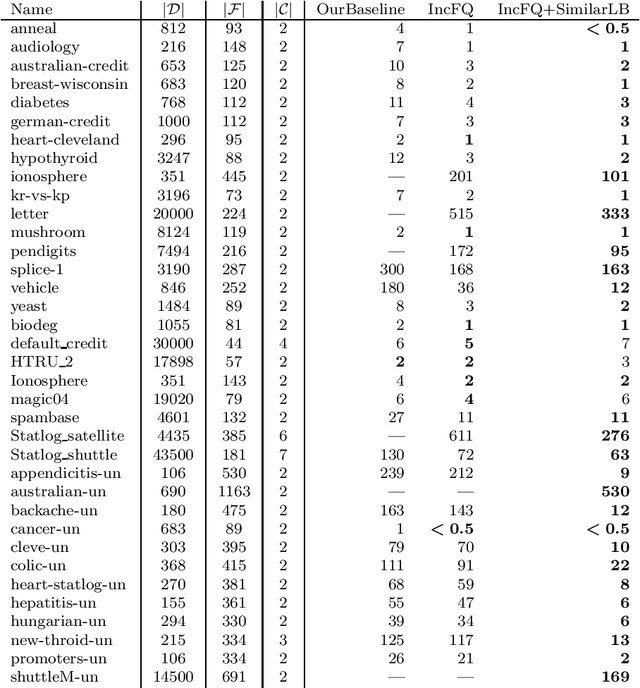
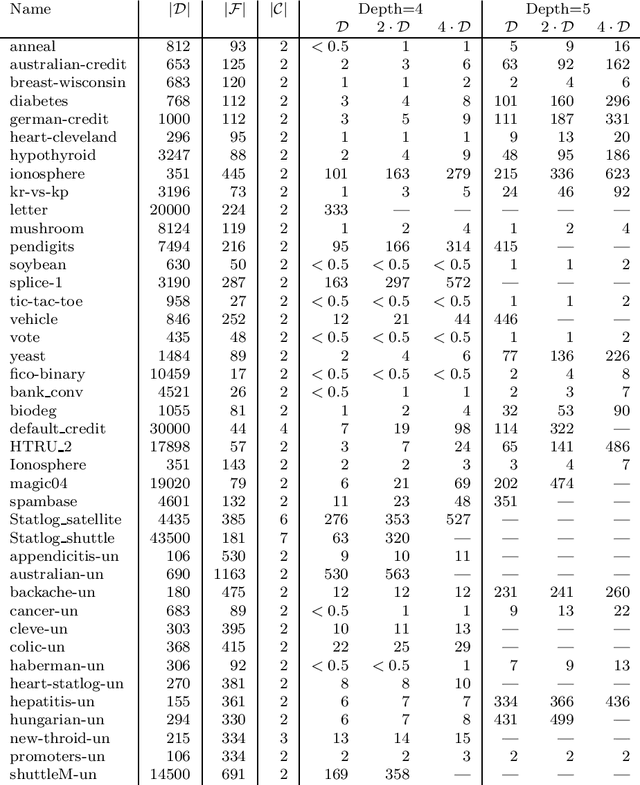
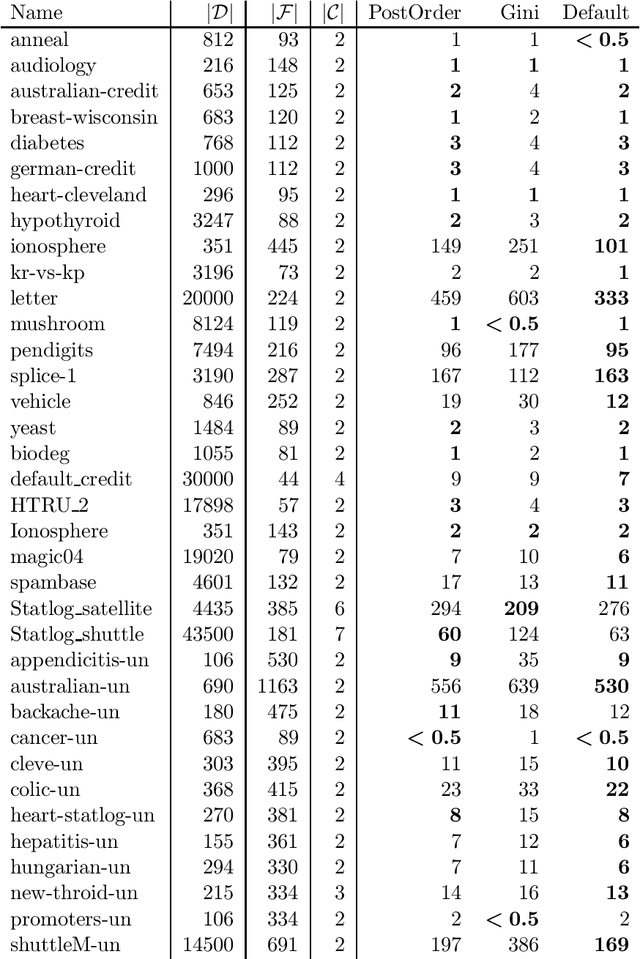
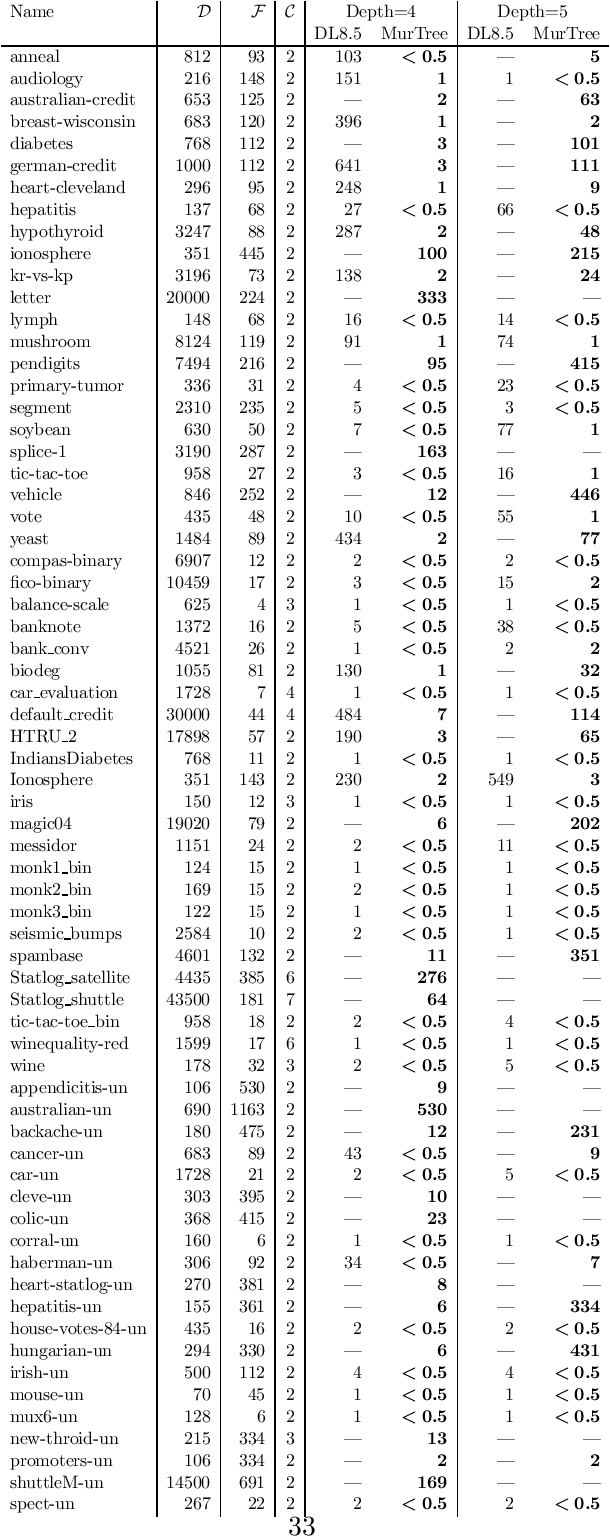
Decision tree learning is a widely used approach in machine learning, favoured in applications that require concise and interpretable models. Heuristic methods are traditionally used to quickly produce models with reasonably high accuracy. A commonly criticised point, however, is that the resulting trees may not necessarily be the best representation of the data in terms of accuracy, size, and other considerations such as fairness. In recent years, this motivated the development of optimal classification tree algorithms that globally optimise the decision tree in contrast to heuristic methods that perform a sequence of locally optimal decisions. We follow this line of work and provide a novel algorithm for learning optimal classification trees based on dynamic programming and search. Our algorithm supports constraints on the depth of the tree and number of nodes and we argue it can be extended with other requirements. The success of our approach is attributed to a series of specialised techniques that exploit properties unique to classification trees. Whereas algorithms for optimal classification trees have traditionally been plagued by high runtimes and limited scalability, we show in a detailed experimental study that our approach uses only a fraction of the time required by the state-of-the-art and can handle datasets with tens of thousands of instances, providing several orders of magnitude improvements and notably contributing towards the practical realisation of optimal decision trees.
Formal Methods with a Touch of Magic
May 25, 2020
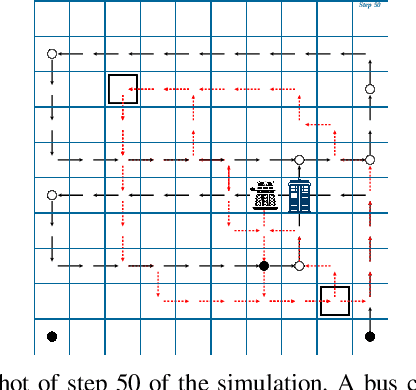

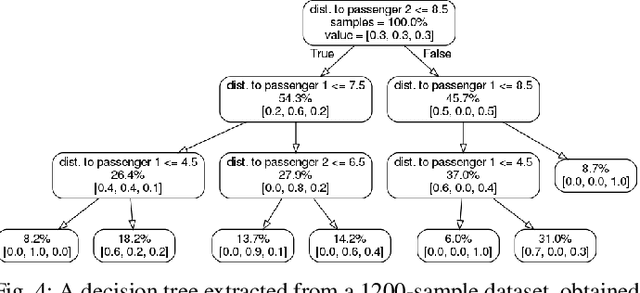
Machine learning and formal methods have complimentary benefits and drawbacks. In this work, we address the controller-design problem with a combination of techniques from both fields. The use of black-box neural networks in deep reinforcement learning (deep RL) poses a challenge for such a combination. Instead of reasoning formally about the output of deep RL, which we call the {\em wizard}, we extract from it a decision-tree based model, which we refer to as the {\em magic book}. Using the extracted model as an intermediary, we are able to handle problems that are infeasible for either deep RL or formal methods by themselves. First, we suggest, for the first time, combining a magic book in a synthesis procedure. We synthesize a stand-alone correct-by-design controller that enjoys the favorable performance of RL. Second, we incorporate a magic book in a bounded model checking (BMC) procedure. BMC allows us to find numerous traces of the plant under the control of the wizard, which a user can use to increase the trustworthiness of the wizard and direct further training.
Outside the Box: Abstraction-Based Monitoring of Neural Networks
Nov 29, 2019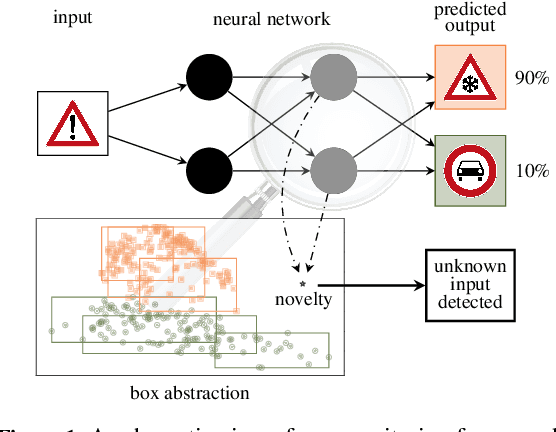

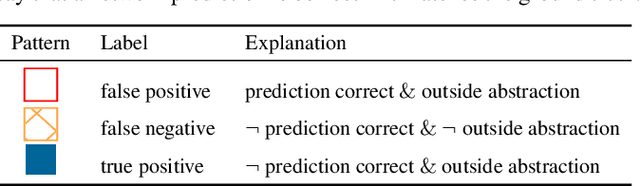
Neural networks have demonstrated unmatched performance in a range of classification tasks. Despite numerous efforts of the research community, novelty detection remains one of the significant limitations of neural networks. The ability to identify previously unseen inputs as novel is crucial for our understanding of the decisions made by neural networks. At runtime, inputs not falling into any of the categories learned during training cannot be classified correctly by the neural network. Existing approaches treat the neural network as a black box and try to detect novel inputs based on the confidence of the output predictions. However, neural networks are not trained to reduce their confidence for novel inputs, which limits the effectiveness of these approaches. We propose a framework to monitor a neural network by observing the hidden layers. We employ a common abstraction from program analysis - boxes - to identify novel behaviors in the monitored layers, i.e., inputs that cause behaviors outside the box. For each neuron, the boxes range over the values seen in training. The framework is efficient and flexible to achieve a desired trade-off between raising false warnings and detecting novel inputs. We illustrate the performance and the robustness to variability in the unknown classes on popular image-classification benchmarks.
ARES: Adaptive Receding-Horizon Synthesis of Optimal Plans
Dec 21, 2016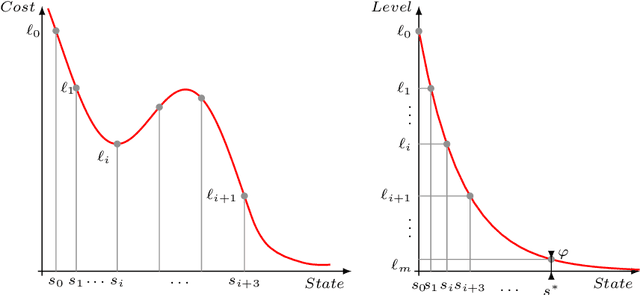
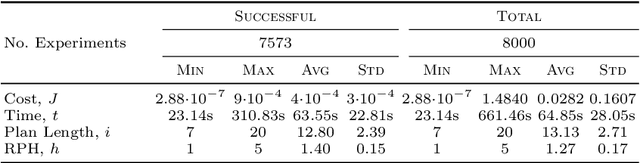
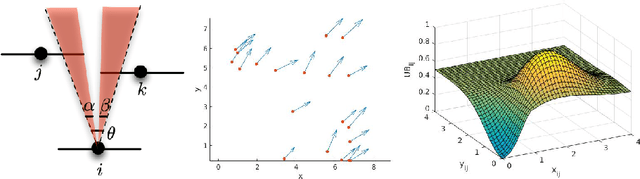
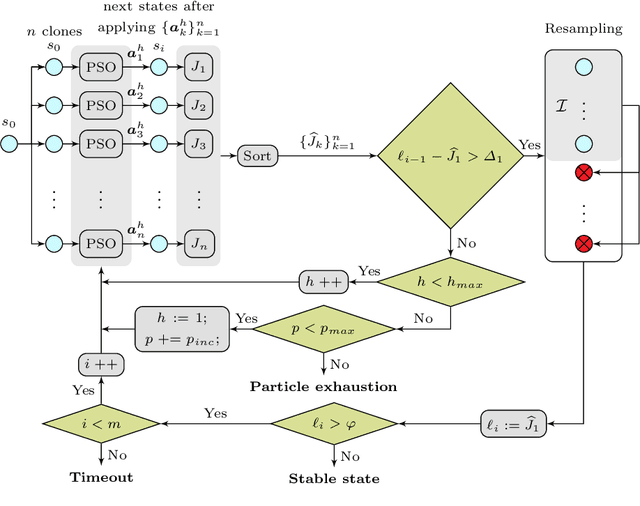
We introduce ARES, an efficient approximation algorithm for generating optimal plans (action sequences) that take an initial state of a Markov Decision Process (MDP) to a state whose cost is below a specified (convergence) threshold. ARES uses Particle Swarm Optimization, with adaptive sizing for both the receding horizon and the particle swarm. Inspired by Importance Splitting, the length of the horizon and the number of particles are chosen such that at least one particle reaches a next-level state, that is, a state where the cost decreases by a required delta from the previous-level state. The level relation on states and the plans constructed by ARES implicitly define a Lyapunov function and an optimal policy, respectively, both of which could be explicitly generated by applying ARES to all states of the MDP, up to some topological equivalence relation. We also assess the effectiveness of ARES by statistically evaluating its rate of success in generating optimal plans. The ARES algorithm resulted from our desire to clarify if flying in V-formation is a flocking policy that optimizes energy conservation, clear view, and velocity alignment. That is, we were interested to see if one could find optimal plans that bring a flock from an arbitrary initial state to a state exhibiting a single connected V-formation. For flocks with 7 birds, ARES is able to generate a plan that leads to a V-formation in 95% of the 8,000 random initial configurations within 63 seconds, on average. ARES can also be easily customized into a model-predictive controller (MPC) with an adaptive receding horizon and statistical guarantees of convergence. To the best of our knowledge, our adaptive-sizing approach is the first to provide convergence guarantees in receding-horizon techniques.