 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Privacy: Temporally Consistent Video Anonymization via Token Pruning for Privacy Preserving Action Recognition
Mar 27, 2026Recent advances in large-scale video models have significantly improved video understanding across domains such as surveillance, healthcare, and entertainment. However, these models also amplify privacy risks by encoding sensitive attributes, including facial identity, race, and gender. While image anonymization has been extensively studied, video anonymization remains relatively underexplored, even though modern video models can leverage spatiotemporal motion patterns as biometric identifiers. To address this challenge, we propose a novel attention-driven spatiotemporal video anonymization framework based on systematic disentanglement of utility and privacy features. Our key insight is that attention mechanisms in Vision Transformers (ViTs) can be explicitly structured to separate action-relevant information from privacy-sensitive content. Building on this insight, we introduce two task-specific classification tokens, an action CLS token and a privacy CLS token, that learn complementary representations within a shared Transformer backbone. We contrast their attention distributions to compute a utility-privacy score for each spatiotemporal tubelet, and keep the top-k tubelets with the highest scores. This selectively prunes tubelets dominated by privacy cues while preserving those most critical for action recognition. Extensive experiments demonstrate that our approach maintains action recognition performance comparable to models trained on raw videos, while substantially reducing privacy leakage. These results indicate that attention-driven spatiotemporal pruning offers an effective and principled solution for privacy-preserving video analytics.
Fixed-Persona SLMs with Modular Memory: Scalable NPC Dialogue on Consumer Hardware
Nov 13, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in generating human-like text, yet their applicability to dialogue systems in computer games remains limited. This limitation arises from their substantial hardware requirements, latency constraints, and the necessity to maintain clearly defined knowledge boundaries within a game setting. In this paper, we propose a modular NPC dialogue system that leverages Small Language Models (SLMs), fine-tuned to encode specific NPC personas and integrated with runtime-swappable memory modules. These memory modules preserve character-specific conversational context and world knowledge, enabling expressive interactions and long-term memory without retraining or model reloading during gameplay. We comprehensively evaluate our system using three open-source SLMs: DistilGPT-2, TinyLlama-1.1B-Chat, and Mistral-7B-Instruct, trained on synthetic persona-aligned data and benchmarked on consumer-grade hardware. While our approach is motivated by applications in gaming, its modular design and persona-driven memory architecture hold significant potential for broader adoption in domains requiring expressive, scalable, and memory-rich conversational agents, such as virtual assistants, customer support bots, or interactive educational systems.
FBFL: A Field-Based Coordination Approach for Data Heterogeneity in Federated Learning
Feb 12, 2025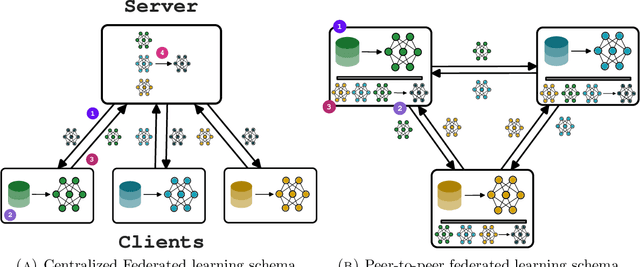

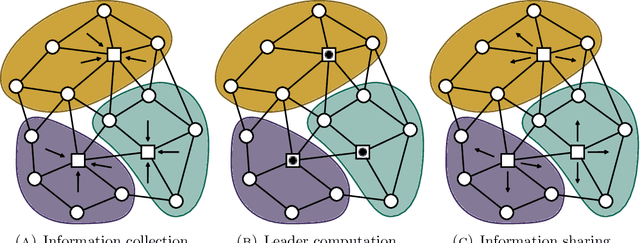

In the last years, Federated learning (FL) has become a popular solution to train machine learning models in domains with high privacy concerns. However, FL scalability and performance face significant challenges in real-world deployments where data across devices are non-independently and identically distributed (non-IID). The heterogeneity in data distribution frequently arises from spatial distribution of devices, leading to degraded model performance in the absence of proper handling. Additionally, FL typical reliance on centralized architectures introduces bottlenecks and single-point-of-failure risks, particularly problematic at scale or in dynamic environments. To close this gap, we propose Field-Based Federated Learning (FBFL), a novel approach leveraging macroprogramming and field coordination to address these limitations through: (i) distributed spatial-based leader election for personalization to mitigate non-IID data challenges; and (ii) construction of a self-organizing, hierarchical architecture using advanced macroprogramming patterns. Moreover, FBFL not only overcomes the aforementioned limitations, but also enables the development of more specialized models tailored to the specific data distribution in each subregion. This paper formalizes FBFL and evaluates it extensively using MNIST, FashionMNIST, and Extended MNIST datasets. We demonstrate that, when operating under IID data conditions, FBFL performs comparably to the widely-used FedAvg algorithm. Furthermore, in challenging non-IID scenarios, FBFL not only outperforms FedAvg but also surpasses other state-of-the-art methods, namely FedProx and Scaffold, which have been specifically designed to address non-IID data distributions. Additionally, we showcase the resilience of FBFL's self-organizing hierarchical architecture against server failures.
Proximity-based Self-Federated Learning
Jul 17, 2024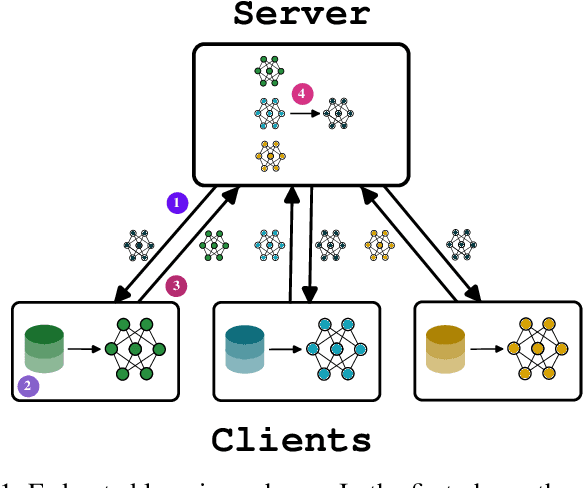



In recent advancements in machine learning, federated learning allows a network of distributed clients to collaboratively develop a global model without needing to share their local data. This technique aims to safeguard privacy, countering the vulnerabilities of conventional centralized learning methods. Traditional federated learning approaches often rely on a central server to coordinate model training across clients, aiming to replicate the same model uniformly across all nodes. However, these methods overlook the significance of geographical and local data variances in vast networks, potentially affecting model effectiveness and applicability. Moreover, relying on a central server might become a bottleneck in large networks, such as the ones promoted by edge computing. Our paper introduces a novel, fully-distributed federated learning strategy called proximity-based self-federated learning that enables the self-organised creation of multiple federations of clients based on their geographic proximity and data distribution without exchanging raw data. Indeed, unlike traditional algorithms, our approach encourages clients to share and adjust their models with neighbouring nodes based on geographic proximity and model accuracy. This method not only addresses the limitations posed by diverse data distributions but also enhances the model's adaptability to different regional characteristics creating specialized models for each federation. We demonstrate the efficacy of our approach through simulations on well-known datasets, showcasing its effectiveness over the conventional centralized federated learning framework.
Adaptive Parameterization of Deep Learning Models for Federated Learning
Feb 06, 2023



Federated Learning offers a way to train deep neural networks in a distributed fashion. While this addresses limitations related to distributed data, it incurs a communication overhead as the model parameters or gradients need to be exchanged regularly during training. This can be an issue with large scale distribution of learning asks and negate the benefit of the respective resource distribution. In this paper, we we propose to utilise parallel Adapters for Federated Learning. Using various datasets, we show that Adapters can be applied with different Federated Learning techniques. We highlight that our approach can achieve similar inference performance compared to training the full model while reducing the communication overhead drastically. We further explore the applicability of Adapters in cross-silo and cross-device settings, as well as different non-IID data distributions.
Analysis of the Effect of Low-Overhead Lossy Image Compression on the Performance of Visual Crowd Counting for Smart City Applications
Jul 20, 2022

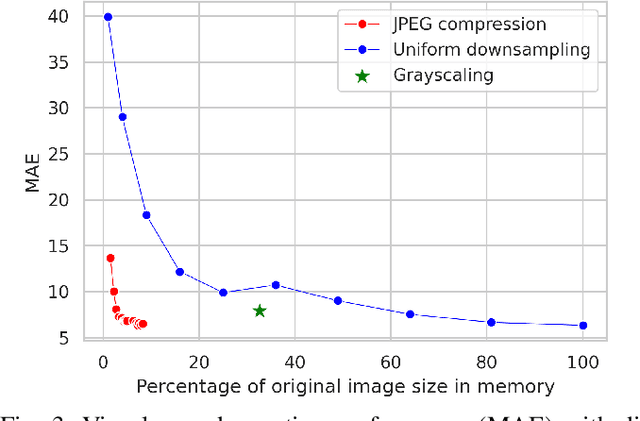
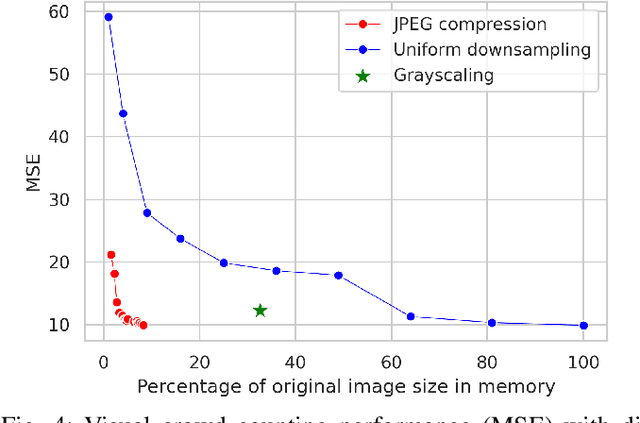
Images and video frames captured by cameras placed throughout smart cities are often transmitted over the network to a server to be processed by deep neural networks for various tasks. Transmission of raw images, i.e., without any form of compression, requires high bandwidth and can lead to congestion issues and delays in transmission. The use of lossy image compression techniques can reduce the quality of the images, leading to accuracy degradation. In this paper, we analyze the effect of applying low-overhead lossy image compression methods on the accuracy of visual crowd counting, and measure the trade-off between bandwidth reduction and the obtained accuracy.
RMQFMU: Bridging the Real World with Co-simulation Technical Report
Jul 08, 2021

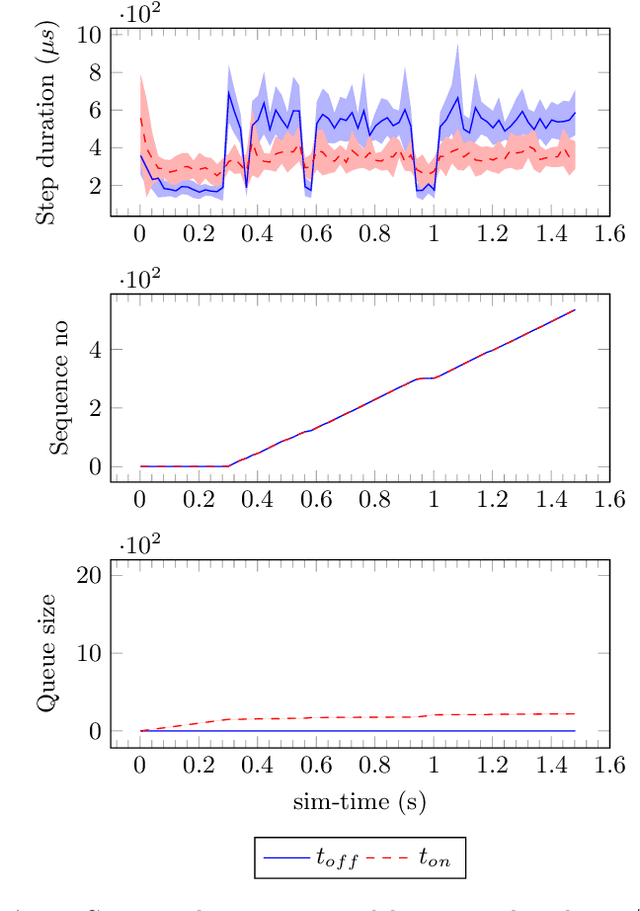
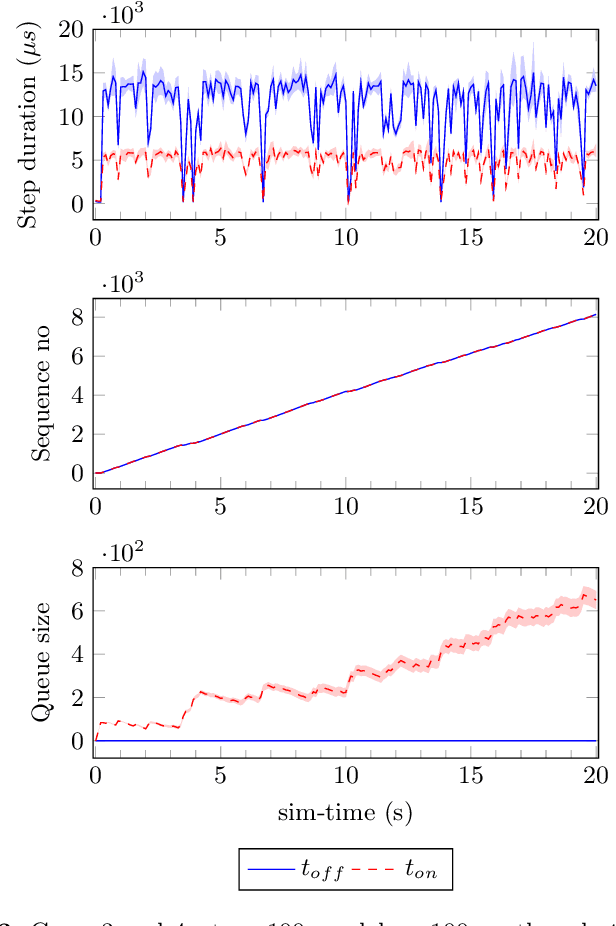
In this paper we present an experience report for the RMQFMU, a plug and play tool, that enables feeding data to/from an FMI2-based co-simulation environment based on the AMQP protocol. Bridging the co-simulation to an external environment allows on one side to feed historical data to the co-simulation, serving different purposes, such as visualisation and/or data analysis. On the other side, such a tool facilitates the realisation of the digital twin concept by coupling co-simulation and hardware/robots close to real-time. In the paper we present limitations of the initial version of the RMQFMU with respect to the capability of bridging co-simulation with the real world. To provide the desired functionality of the tool, we present in a step-by-step fashion how these limitations, and subsequent limitations, are alleviated. We perform various experiments in order to give reason to the modifications carried out. Finally, we report on two case-studies where we have adopted the RMQFMU, and provide guidelines meant to aid practitioners in its use.
ARES: Adaptive Receding-Horizon Synthesis of Optimal Plans
Dec 21, 2016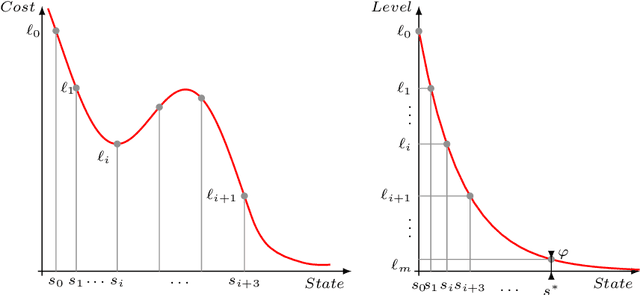
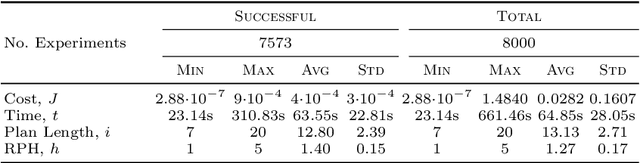
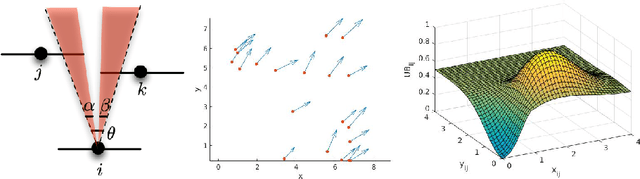
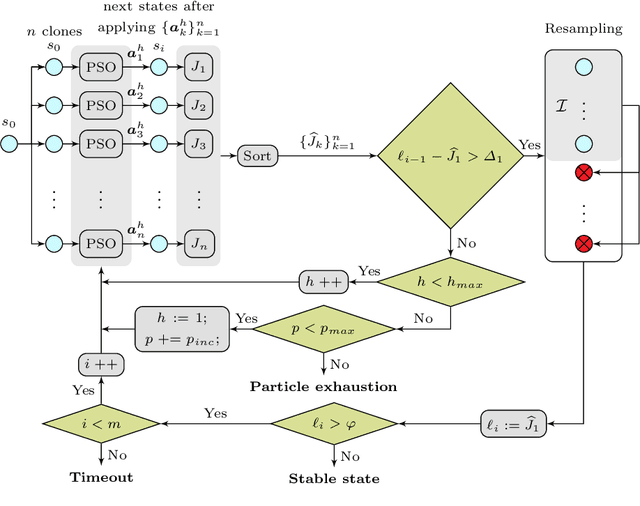
We introduce ARES, an efficient approximation algorithm for generating optimal plans (action sequences) that take an initial state of a Markov Decision Process (MDP) to a state whose cost is below a specified (convergence) threshold. ARES uses Particle Swarm Optimization, with adaptive sizing for both the receding horizon and the particle swarm. Inspired by Importance Splitting, the length of the horizon and the number of particles are chosen such that at least one particle reaches a next-level state, that is, a state where the cost decreases by a required delta from the previous-level state. The level relation on states and the plans constructed by ARES implicitly define a Lyapunov function and an optimal policy, respectively, both of which could be explicitly generated by applying ARES to all states of the MDP, up to some topological equivalence relation. We also assess the effectiveness of ARES by statistically evaluating its rate of success in generating optimal plans. The ARES algorithm resulted from our desire to clarify if flying in V-formation is a flocking policy that optimizes energy conservation, clear view, and velocity alignment. That is, we were interested to see if one could find optimal plans that bring a flock from an arbitrary initial state to a state exhibiting a single connected V-formation. For flocks with 7 birds, ARES is able to generate a plan that leads to a V-formation in 95% of the 8,000 random initial configurations within 63 seconds, on average. ARES can also be easily customized into a model-predictive controller (MPC) with an adaptive receding horizon and statistical guarantees of convergence. To the best of our knowledge, our adaptive-sizing approach is the first to provide convergence guarantees in receding-horizon techniques.