 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Self-Federated Learning for Energy Efficient Cooperative Intelligence in Society 5.0
Jul 10, 2025Federated Learning offers privacy-preserving collaborative intelligence but struggles to meet the sustainability demands of emerging IoT ecosystems necessary for Society 5.0-a human-centered technological future balancing social advancement with environmental responsibility. The excessive communication bandwidth and computational resources required by traditional FL approaches make them environmentally unsustainable at scale, creating a fundamental conflict with green AI principles as billions of resource-constrained devices attempt to participate. To this end, we introduce Sparse Proximity-based Self-Federated Learning (SParSeFuL), a resource-aware approach that bridges this gap by combining aggregate computing for self-organization with neural network sparsification to reduce energy and bandwidth consumption.
ProFed: a Benchmark for Proximity-based non-IID Federated Learning
Mar 26, 2025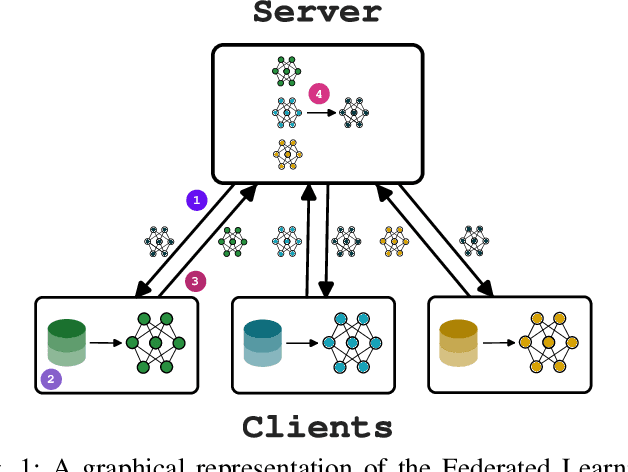
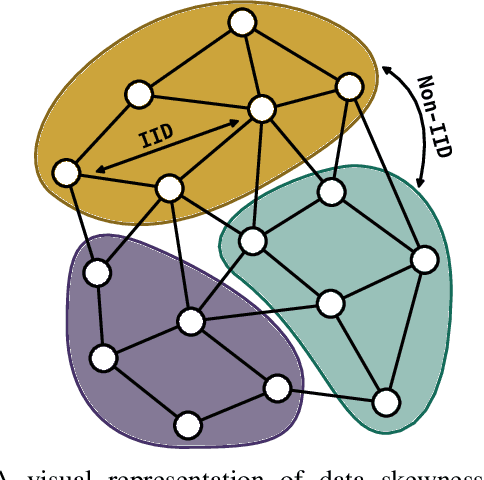
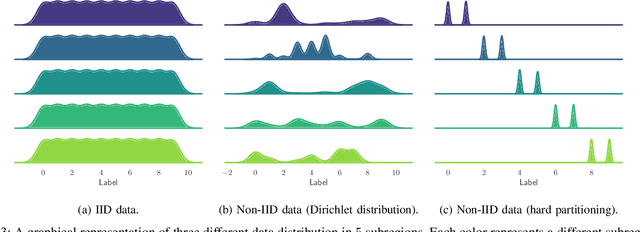

In recent years, cro:flFederated learning (FL) has gained significant attention within the machine learning community. Although various FL algorithms have been proposed in the literature, their performance often degrades when data across clients is non-independently and identically distributed (non-IID). This skewness in data distribution often emerges from geographic patterns, with notable examples including regional linguistic variations in text data or localized traffic patterns in urban environments. Such scenarios result in IID data within specific regions but non-IID data across regions. However, existing FL algorithms are typically evaluated by randomly splitting non-IID data across devices, disregarding their spatial distribution. To address this gap, we introduce ProFed, a benchmark that simulates data splits with varying degrees of skewness across different regions. We incorporate several skewness methods from the literature and apply them to well-known datasets, including MNIST, FashionMNIST, CIFAR-10, and CIFAR-100. Our goal is to provide researchers with a standardized framework to evaluate FL algorithms more effectively and consistently against established baselines.
FBFL: A Field-Based Coordination Approach for Data Heterogeneity in Federated Learning
Feb 12, 2025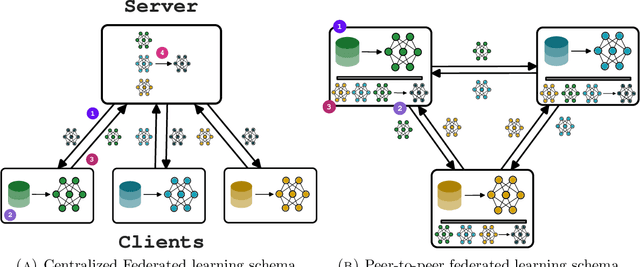

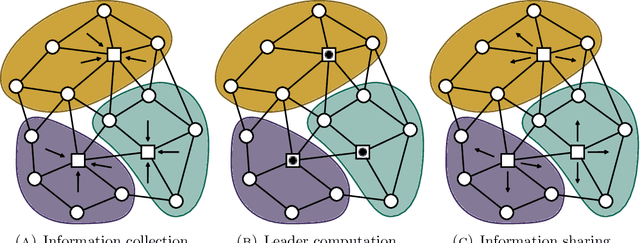

In the last years, Federated learning (FL) has become a popular solution to train machine learning models in domains with high privacy concerns. However, FL scalability and performance face significant challenges in real-world deployments where data across devices are non-independently and identically distributed (non-IID). The heterogeneity in data distribution frequently arises from spatial distribution of devices, leading to degraded model performance in the absence of proper handling. Additionally, FL typical reliance on centralized architectures introduces bottlenecks and single-point-of-failure risks, particularly problematic at scale or in dynamic environments. To close this gap, we propose Field-Based Federated Learning (FBFL), a novel approach leveraging macroprogramming and field coordination to address these limitations through: (i) distributed spatial-based leader election for personalization to mitigate non-IID data challenges; and (ii) construction of a self-organizing, hierarchical architecture using advanced macroprogramming patterns. Moreover, FBFL not only overcomes the aforementioned limitations, but also enables the development of more specialized models tailored to the specific data distribution in each subregion. This paper formalizes FBFL and evaluates it extensively using MNIST, FashionMNIST, and Extended MNIST datasets. We demonstrate that, when operating under IID data conditions, FBFL performs comparably to the widely-used FedAvg algorithm. Furthermore, in challenging non-IID scenarios, FBFL not only outperforms FedAvg but also surpasses other state-of-the-art methods, namely FedProx and Scaffold, which have been specifically designed to address non-IID data distributions. Additionally, we showcase the resilience of FBFL's self-organizing hierarchical architecture against server failures.
Proximity-based Self-Federated Learning
Jul 17, 2024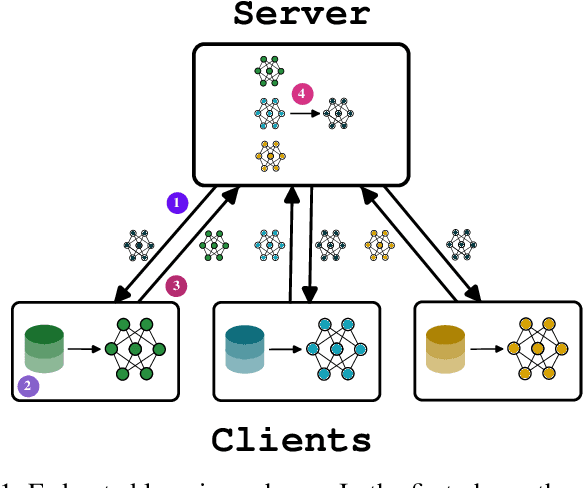



In recent advancements in machine learning, federated learning allows a network of distributed clients to collaboratively develop a global model without needing to share their local data. This technique aims to safeguard privacy, countering the vulnerabilities of conventional centralized learning methods. Traditional federated learning approaches often rely on a central server to coordinate model training across clients, aiming to replicate the same model uniformly across all nodes. However, these methods overlook the significance of geographical and local data variances in vast networks, potentially affecting model effectiveness and applicability. Moreover, relying on a central server might become a bottleneck in large networks, such as the ones promoted by edge computing. Our paper introduces a novel, fully-distributed federated learning strategy called proximity-based self-federated learning that enables the self-organised creation of multiple federations of clients based on their geographic proximity and data distribution without exchanging raw data. Indeed, unlike traditional algorithms, our approach encourages clients to share and adjust their models with neighbouring nodes based on geographic proximity and model accuracy. This method not only addresses the limitations posed by diverse data distributions but also enhances the model's adaptability to different regional characteristics creating specialized models for each federation. We demonstrate the efficacy of our approach through simulations on well-known datasets, showcasing its effectiveness over the conventional centralized federated learning framework.
Software Engineering for Collective Cyber-Physical Ecosystems
Jun 07, 2024

Today's distributed and pervasive computing addresses large-scale cyber-physical ecosystems, characterised by dense and large networks of devices capable of computation, communication and interaction with the environment and people. While most research focusses on treating these systems as "composites" (i.e., heterogeneous functional complexes), recent developments in fields such as self-organising systems and swarm robotics have opened up a complementary perspective: treating systems as "collectives" (i.e., uniform, collaborative, and self-organising groups of entities). This article explores the motivations, state of the art, and implications of this "collective computing paradigm" in software engineering, discusses its peculiar challenges, and outlines a path for future research, touching on aspects such as macroprogramming, collective intelligence, self-adaptive middleware, learning, synthesis, and experimentation of collective behaviour.
MacroSwarm: A Field-based Compositional Framework for Swarm Programming
Jan 19, 2024



Swarm behaviour engineering is an area of research that seeks to investigate methods and techniques for coordinating computation and action within groups of simple agents to achieve complex global goals like pattern formation, collective movement, clustering, and distributed sensing. Despite recent progress in the analysis and engineering of swarms (of drones, robots, vehicles), there is still a need for general design and implementation methods and tools that can be used to define complex swarm behaviour in a principled way. To contribute to this quest, this article proposes a new field-based coordination approach, called MacroSwarm, to design and program swarm behaviour in terms of reusable and fully composable functional blocks embedding collective computation and coordination. Based on the macroprogramming paradigm of aggregate computing, MacroSwarm builds on the idea of expressing each swarm behaviour block as a pure function mapping sensing fields into actuation goal fields, e.g. including movement vectors. In order to demonstrate the expressiveness, compositionality, and practicality of MacroSwarm as a framework for collective intelligence, we perform a variety of simulations covering common patterns of flocking, morphogenesis, and collective decision-making.