 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProFed: a Benchmark for Proximity-based non-IID Federated Learning
Paper and Code
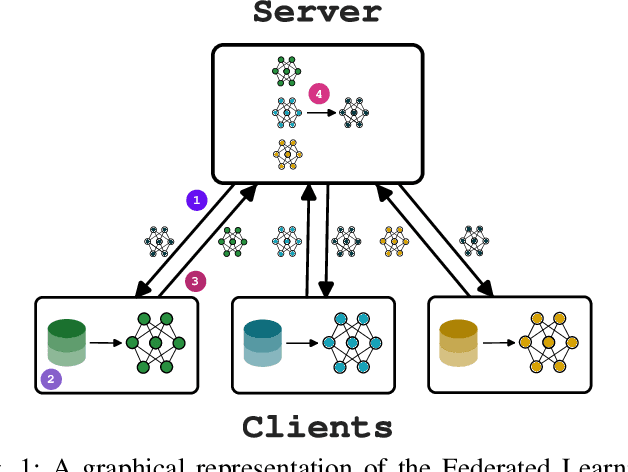
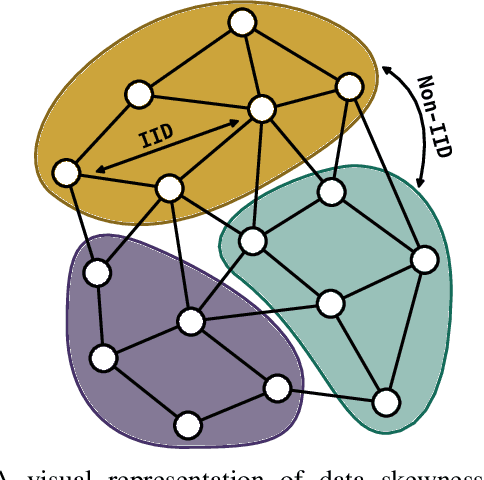
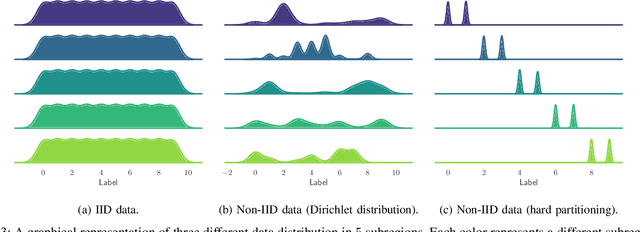

In recent years, cro:flFederated learning (FL) has gained significant attention within the machine learning community. Although various FL algorithms have been proposed in the literature, their performance often degrades when data across clients is non-independently and identically distributed (non-IID). This skewness in data distribution often emerges from geographic patterns, with notable examples including regional linguistic variations in text data or localized traffic patterns in urban environments. Such scenarios result in IID data within specific regions but non-IID data across regions. However, existing FL algorithms are typically evaluated by randomly splitting non-IID data across devices, disregarding their spatial distribution. To address this gap, we introduce ProFed, a benchmark that simulates data splits with varying degrees of skewness across different regions. We incorporate several skewness methods from the literature and apply them to well-known datasets, including MNIST, FashionMNIST, CIFAR-10, and CIFAR-100. Our goal is to provide researchers with a standardized framework to evaluate FL algorithms more effectively and consistently against established baselines.