 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Low-Rank Scaled Dot-product Attention
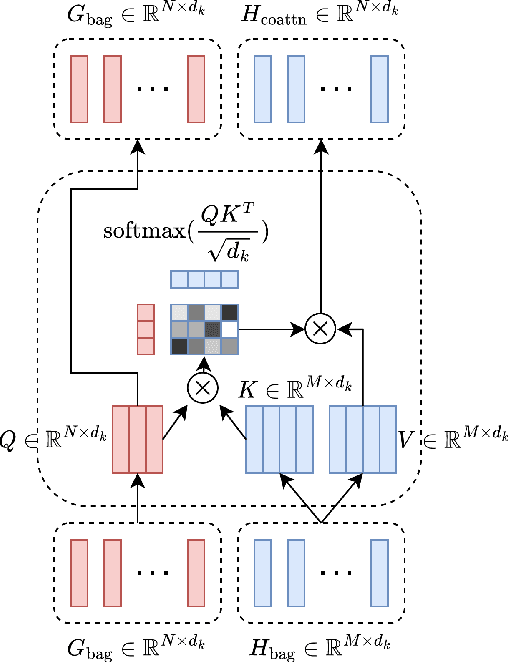
Dec 05, 2024Transformers are widely used for their ability to capture data relations in sequence processing, with great success for a wide range of static tasks. However, the computational and memory footprint of their main component, i.e., the Scaled Dot-product Attention, is commonly overlooked. This makes their adoption in applications involving stream data processing with constraints in response latency, computational and memory resources infeasible. Some works have proposed methods to lower the computational cost of transformers, i.e. low-rank approximations, sparsity in attention, and efficient formulations for Continual Inference. In this paper, we introduce a new formulation of the Scaled Dot-product Attention based on the Nystr\"om approximation that is suitable for Continual Inference. In experiments on Online Audio Classification and Online Action Detection tasks, the proposed Continual Scaled Dot-product Attention can lower the number of operations by up to three orders of magnitude compared to the original Transformers while retaining the predictive performance of competing models.
Audio-Visual Dataset and Method for Anomaly Detection in Traffic Videos
May 24, 2023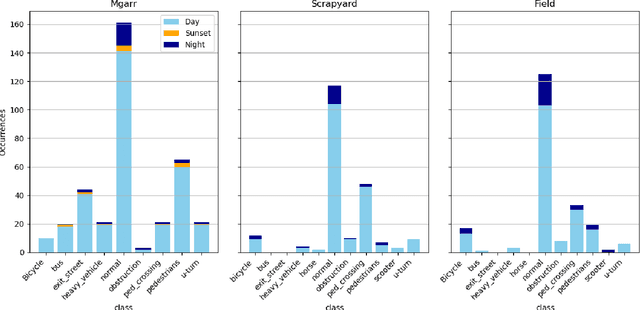
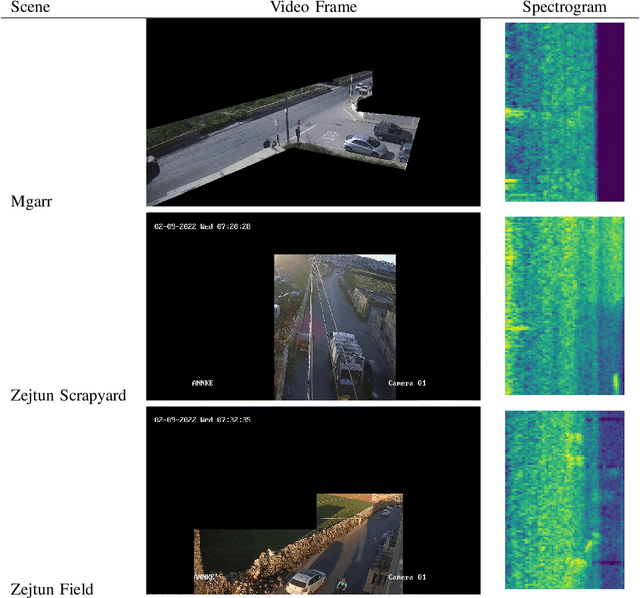

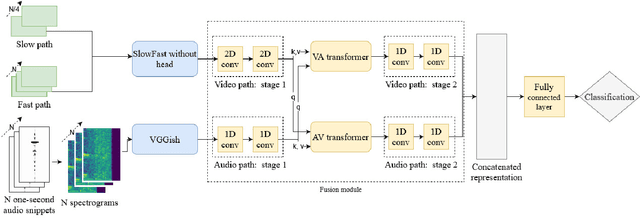
We introduce the first audio-visual dataset for traffic anomaly detection taken from real-world scenes, called MAVAD, with a diverse range of weather and illumination conditions. In addition, we propose a novel method named AVACA that combines visual and audio features extracted from video sequences by means of cross-attention to detect anomalies. We demonstrate that the addition of audio improves the performance of AVACA by up to 5.2%. We also evaluate the impact of image anonymization, showing only a minor decrease in performance averaging at 1.7%.
Accurate Gigapixel Crowd Counting by Iterative Zooming and Refinement
May 16, 2023
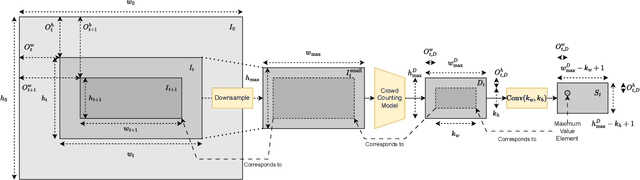


The increasing prevalence of gigapixel resolutions has presented new challenges for crowd counting. Such resolutions are far beyond the memory and computation limits of current GPUs, and available deep neural network architectures and training procedures are not designed for such massive inputs. Although several methods have been proposed to address these challenges, they are either limited to downsampling the input image to a small size, or borrowing from other gigapixel tasks, which are not tailored for crowd counting. In this paper, we propose a novel method called GigaZoom, which iteratively zooms into the densest areas of the image and refines coarser density maps with finer details. Through experiments, we show that GigaZoom obtains the state-of-the-art for gigapixel crowd counting and improves the accuracy of the next best method by 42%.
PromptMix: Text-to-image diffusion models enhance the performance of lightweight networks
Jan 31, 2023



Many deep learning tasks require annotations that are too time consuming for human operators, resulting in small dataset sizes. This is especially true for dense regression problems such as crowd counting which requires the location of every person in the image to be annotated. Techniques such as data augmentation and synthetic data generation based on simulations can help in such cases. In this paper, we introduce PromptMix, a method for artificially boosting the size of existing datasets, that can be used to improve the performance of lightweight networks. First, synthetic images are generated in an end-to-end data-driven manner, where text prompts are extracted from existing datasets via an image captioning deep network, and subsequently introduced to text-to-image diffusion models. The generated images are then annotated using one or more high-performing deep networks, and mixed with the real dataset for training the lightweight network. By extensive experiments on five datasets and two tasks, we show that PromptMix can significantly increase the performance of lightweight networks by up to 26%.
Crowd Counting on Heavily Compressed Images with Curriculum Pre-Training
Aug 15, 2022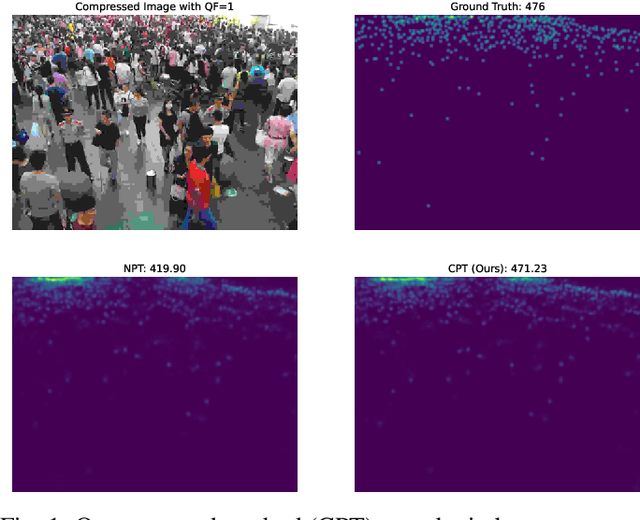

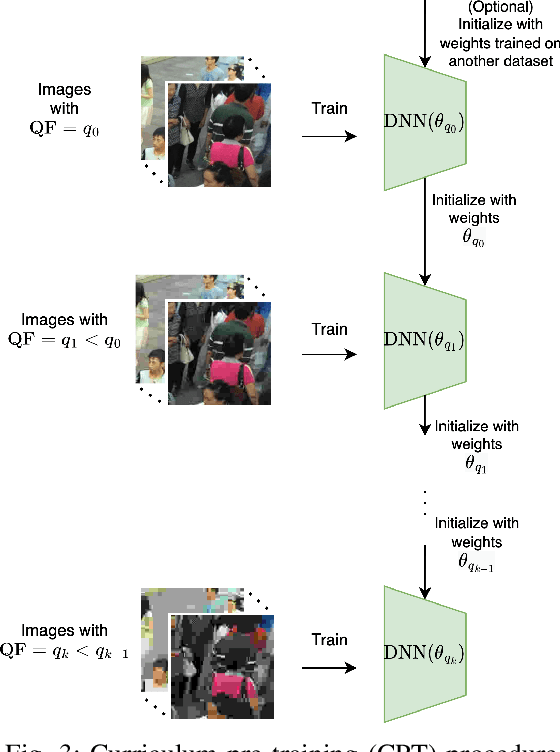
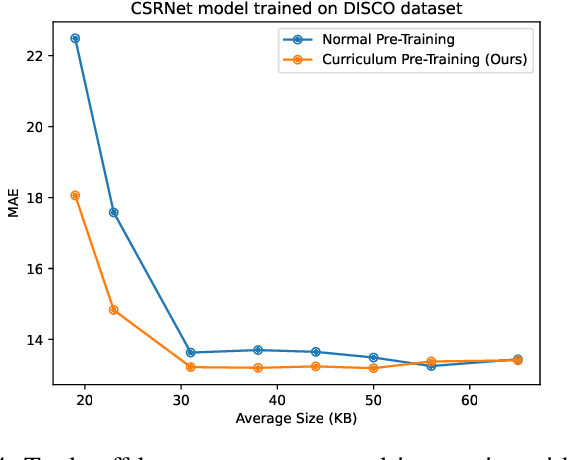
JPEG image compression algorithm is a widely used technique for image size reduction in edge and cloud computing settings. However, applying such lossy compression on images processed by deep neural networks can lead to significant accuracy degradation. Inspired by the curriculum learning paradigm, we present a novel training approach called curriculum pre-training (CPT) for crowd counting on compressed images, which alleviates the drop in accuracy resulting from lossy compression. We verify the effectiveness of our approach by extensive experiments on three crowd counting datasets, two crowd counting DNN models and various levels of compression. Our proposed training method is not overly sensitive to hyper-parameters, and reduces the error, particularly for heavily compressed images, by up to 19.70%.
Efficient High-Resolution Deep Learning: A Survey
Jul 26, 2022
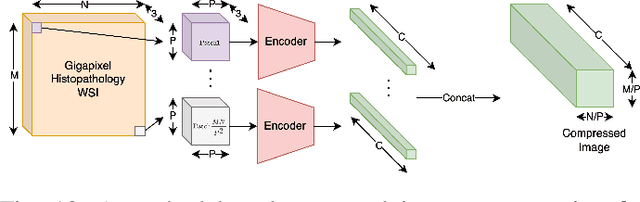

Cameras in modern devices such as smartphones, satellites and medical equipment are capable of capturing very high resolution images and videos. Such high-resolution data often need to be processed by deep learning models for cancer detection, automated road navigation, weather prediction, surveillance, optimizing agricultural processes and many other applications. Using high-resolution images and videos as direct inputs for deep learning models creates many challenges due to their high number of parameters, computation cost, inference latency and GPU memory consumption. Simple approaches such as resizing the images to a lower resolution are common in the literature, however, they typically significantly decrease accuracy. Several works in the literature propose better alternatives in order to deal with the challenges of high-resolution data and improve accuracy and speed while complying with hardware limitations and time restrictions. This survey describes such efficient high-resolution deep learning methods, summarizes real-world applications of high-resolution deep learning, and provides comprehensive information about available high-resolution datasets.
Analysis of the Effect of Low-Overhead Lossy Image Compression on the Performance of Visual Crowd Counting for Smart City Applications
Jul 20, 2022

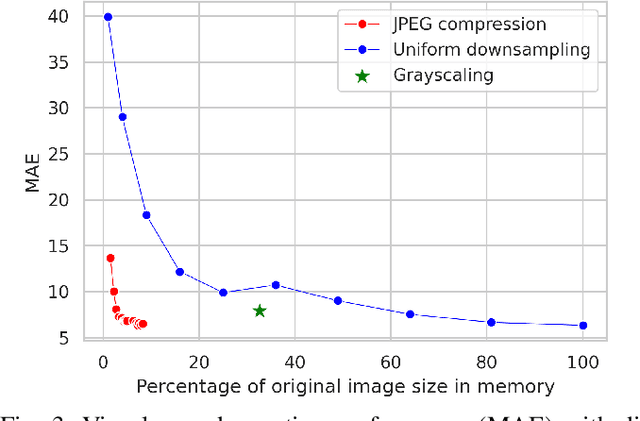
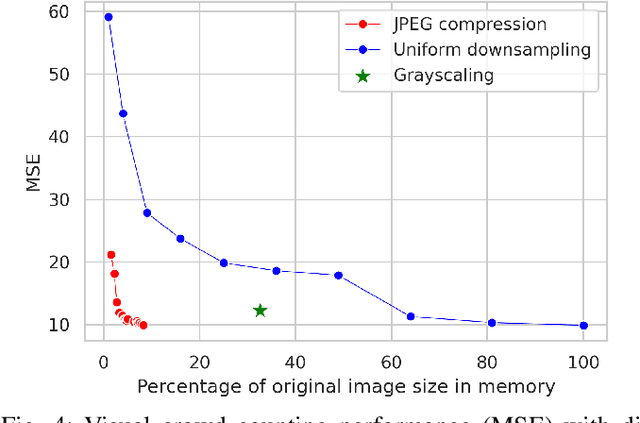
Images and video frames captured by cameras placed throughout smart cities are often transmitted over the network to a server to be processed by deep neural networks for various tasks. Transmission of raw images, i.e., without any form of compression, requires high bandwidth and can lead to congestion issues and delays in transmission. The use of lossy image compression techniques can reduce the quality of the images, leading to accuracy degradation. In this paper, we analyze the effect of applying low-overhead lossy image compression methods on the accuracy of visual crowd counting, and measure the trade-off between bandwidth reduction and the obtained accuracy.
Dynamic Split Computing for Efficient Deep Edge Intelligence
May 23, 2022

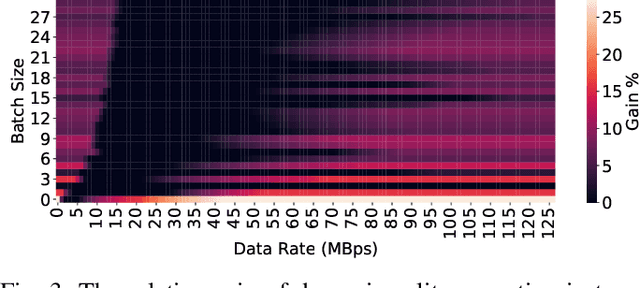
Deploying deep neural networks (DNNs) on IoT and mobile devices is a challenging task due to their limited computational resources. Thus, demanding tasks are often entirely offloaded to edge servers which can accelerate inference, however, it also causes communication cost and evokes privacy concerns. In addition, this approach leaves the computational capacity of end devices unused. Split computing is a paradigm where a DNN is split into two sections; the first section is executed on the end device, and the output is transmitted to the edge server where the final section is executed. Here, we introduce dynamic split computing, where the optimal split location is dynamically selected based on the state of the communication channel. By using natural bottlenecks that already exist in modern DNN architectures, dynamic split computing avoids retraining and hyperparameter optimization, and does not have any negative impact on the final accuracy of DNNs. Through extensive experiments, we show that dynamic split computing achieves faster inference in edge computing environments where the data rate and server load vary over time.
Continual Transformers: Redundancy-Free Attention for Online Inference
Jan 17, 2022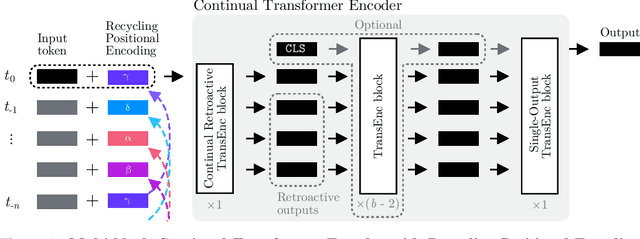



Transformers are attention-based sequence transduction models, which have found widespread success in Natural Language Processing and Computer Vision applications. Yet, Transformers in their current form are inherently limited to operate on whole token sequences rather than on one token at a time. Consequently, their use during online inference entails considerable redundancy due to the overlap in successive token sequences. In this work, we propose novel formulations of the Scaled Dot-Product Attention, which enable Transformers to perform efficient online token-by-token inference in a continual input stream. Importantly, our modification is purely to the order of computations, while the produced outputs and learned weights are identical to those of the original Multi-Head Attention. To validate our approach, we conduct experiments on visual, audio, and audio-visual classification and detection tasks, i.e. Online Action Detection on THUMOS14 and TVSeries and Online Audio Classification on GTZAN, with remarkable results. Our continual one-block transformers reduce the floating point operations by respectively 63.5x and 51.5x in the Online Action Detection and Audio Classification experiments at similar predictive performance.
Multi-Exit Vision Transformer for Dynamic Inference
Jun 30, 2021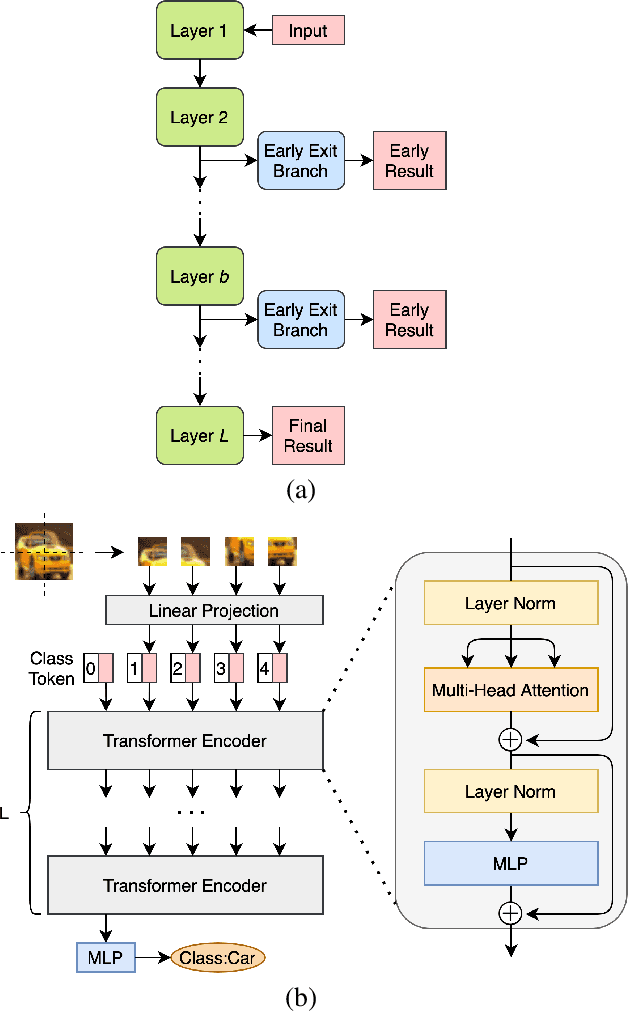
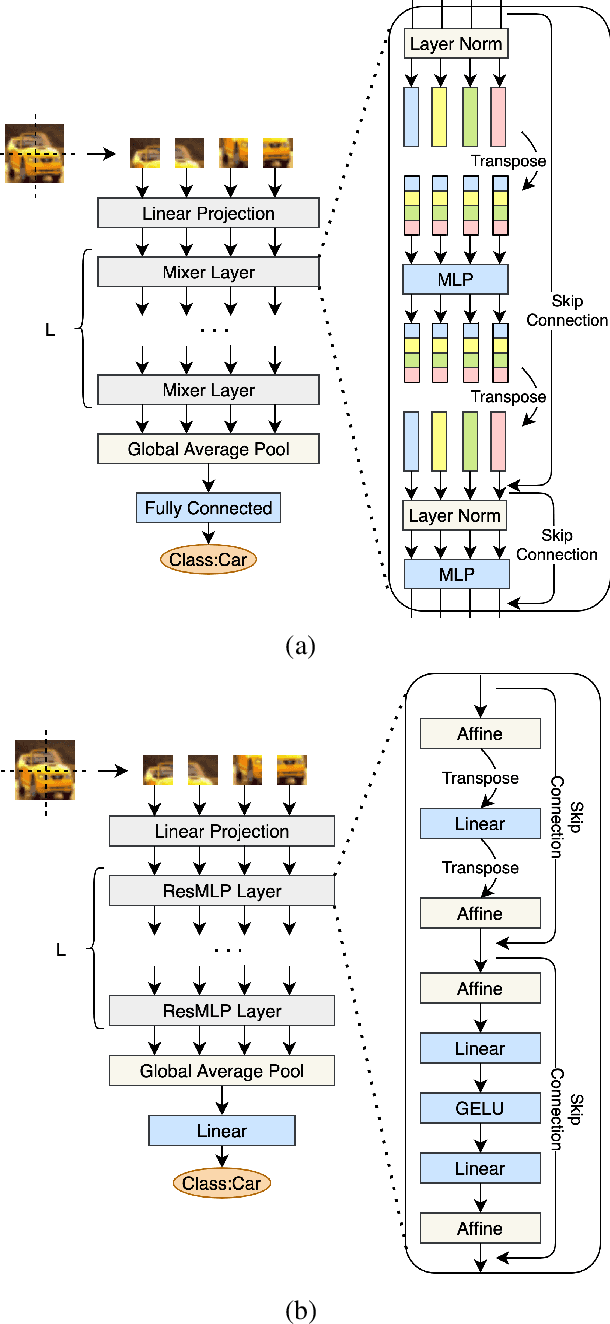
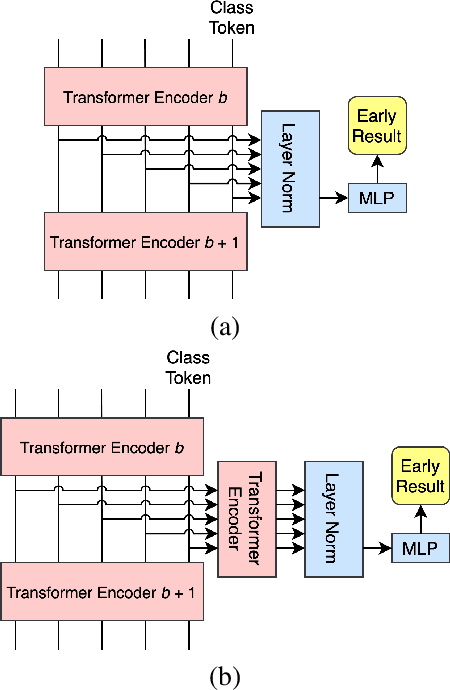
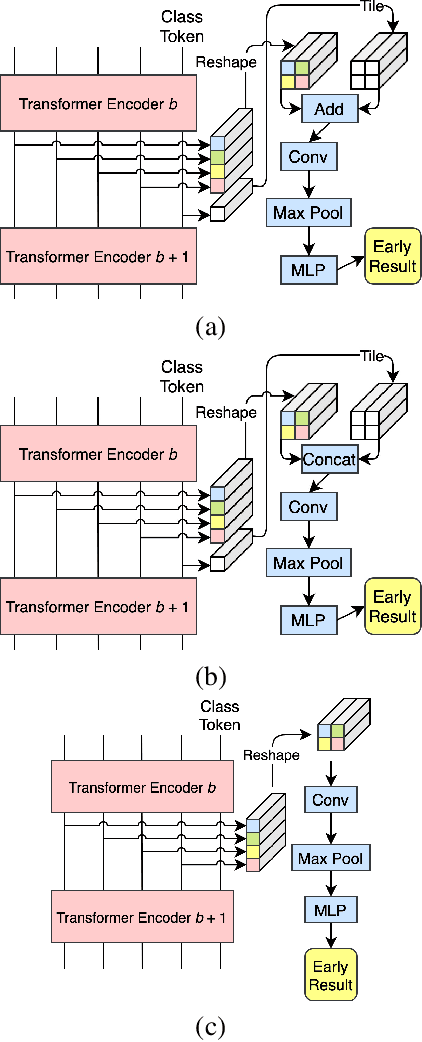
Deep neural networks can be converted to multi-exit architectures by inserting early exit branches after some of their intermediate layers. This allows their inference process to become dynamic, which is useful for time critical IoT applications with stringent latency requirements, but with time-variant communication and computation resources. In particular, in edge computing systems and IoT networks where the exact computation time budget is variable and not known beforehand. Vision Transformer is a recently proposed architecture which has since found many applications across various domains of computer vision. In this work, we propose seven different architectures for early exit branches that can be used for dynamic inference in Vision Transformer backbones. Through extensive experiments involving both classification and regression problems, we show that each one of our proposed architectures could prove useful in the trade-off between accuracy and speed.