 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Gradient Clustering: Convergence and the Effect of Initialization
Mar 20, 2026We study the effects of center initialization on the performance of a family of distributed gradient-based clustering algorithms introduced in [1], that work over connected networks of users. In the considered scenario, each user contains a local dataset and communicates only with its immediate neighbours, with the aim of finding a global clustering of the joint data. We perform extensive numerical experiments, evaluating the effects of center initialization on the performance of our family of methods, demonstrating that our methods are more resilient to the effects of initialization, compared to centralized gradient clustering [2]. Next, inspired by the $K$-means++ initialization [3], we propose a novel distributed center initialization scheme, which is shown to improve the performance of our methods, compared to the baseline random initialization.
Tight Long-Term Tail Decay of (Clipped) SGD in Non-Convex Optimization
Feb 05, 2026The study of tail behaviour of SGD-induced processes has been attracting a lot of interest, due to offering strong guarantees with respect to individual runs of an algorithm. While many works provide high-probability guarantees, quantifying the error rate for a fixed probability threshold, there is a lack of work directly studying the probability of failure, i.e., quantifying the tail decay rate for a fixed error threshold. Moreover, existing results are of finite-time nature, limiting their ability to capture the true long-term tail decay which is more informative for modern learning models, typically trained for millions of iterations. Our work closes these gaps, by studying the long-term tail decay of SGD-based methods through the lens of large deviations theory, establishing several strong results in the process. First, we provide an upper bound on the tails of the gradient norm-squared of the best iterate produced by (vanilla) SGD, for non-convex costs and bounded noise, with long-term decay at rate $e^{-t/\log(t)}$. Next, we relax the noise assumption by considering clipped SGD (c-SGD) under heavy-tailed noise with bounded moment of order $p \in (1,2]$, showing an upper bound with long-term decay at rate $e^{-t^{β_p}/\log(t)}$, where $β_p = \frac{4(p-1)}{3p-2}$ for $p \in (1,2)$ and $e^{-t/\log^2(t)}$ for $p = 2$. Finally, we provide lower bounds on the tail decay, at rate $e^{-t}$, showing that our rates for both SGD and c-SGD are tight, up to poly-logarithmic factors. Notably, our results demonstrate an order of magnitude faster long-term tail decay compared to existing work based on finite-time bounds, which show rates $e^{-\sqrt{t}}$ and $e^{-t^{β_p/2}}$, $p \in (1,2]$, for SGD and c-SGD, respectively. As such, we uncover regimes where the tails decay much faster than previously known, providing stronger long-term guarantees for individual runs.
A Unified Framework for Gradient-based Clustering of Distributed Data
Feb 02, 2024



We develop a family of distributed clustering algorithms that work over networks of users. In the proposed scenario, users contain a local dataset and communicate only with their immediate neighbours, with the aim of finding a clustering of the full, joint data. The proposed family, termed Distributed Gradient Clustering (DGC-$\mathcal{F}_\rho$), is parametrized by $\rho \geq 1$, controling the proximity of users' center estimates, with $\mathcal{F}$ determining the clustering loss. Specialized to popular clustering losses like $K$-means and Huber loss, DGC-$\mathcal{F}_\rho$ gives rise to novel distributed clustering algorithms DGC-KM$_\rho$ and DGC-HL$_\rho$, while a novel clustering loss based on the logistic function leads to DGC-LL$_\rho$. We provide a unified analysis and establish several strong results, under mild assumptions. First, the sequence of centers generated by the methods converges to a well-defined notion of fixed point, under any center initialization and value of $\rho$. Second, as $\rho$ increases, the family of fixed points produced by DGC-$\mathcal{F}_\rho$ converges to a notion of consensus fixed points. We show that consensus fixed points of DGC-$\mathcal{F}_{\rho}$ are equivalent to fixed points of gradient clustering over the full data, guaranteeing a clustering of the full data is produced. For the special case of Bregman losses, we show that our fixed points converge to the set of Lloyd points. Numerical experiments on real data confirm our theoretical findings and demonstrate strong performance of the methods.
Dynamic Split Computing for Efficient Deep Edge Intelligence
May 23, 2022

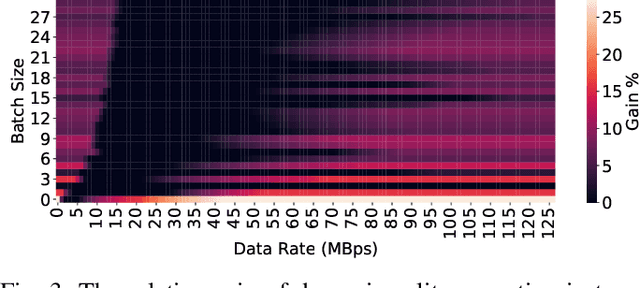
Deploying deep neural networks (DNNs) on IoT and mobile devices is a challenging task due to their limited computational resources. Thus, demanding tasks are often entirely offloaded to edge servers which can accelerate inference, however, it also causes communication cost and evokes privacy concerns. In addition, this approach leaves the computational capacity of end devices unused. Split computing is a paradigm where a DNN is split into two sections; the first section is executed on the end device, and the output is transmitted to the edge server where the final section is executed. Here, we introduce dynamic split computing, where the optimal split location is dynamically selected based on the state of the communication channel. By using natural bottlenecks that already exist in modern DNN architectures, dynamic split computing avoids retraining and hyperparameter optimization, and does not have any negative impact on the final accuracy of DNNs. Through extensive experiments, we show that dynamic split computing achieves faster inference in edge computing environments where the data rate and server load vary over time.