 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Gradient Clustering: Convergence and the Effect of Initialization
Mar 20, 2026We study the effects of center initialization on the performance of a family of distributed gradient-based clustering algorithms introduced in [1], that work over connected networks of users. In the considered scenario, each user contains a local dataset and communicates only with its immediate neighbours, with the aim of finding a global clustering of the joint data. We perform extensive numerical experiments, evaluating the effects of center initialization on the performance of our family of methods, demonstrating that our methods are more resilient to the effects of initialization, compared to centralized gradient clustering [2]. Next, inspired by the $K$-means++ initialization [3], we propose a novel distributed center initialization scheme, which is shown to improve the performance of our methods, compared to the baseline random initialization.
Tight Long-Term Tail Decay of (Clipped) SGD in Non-Convex Optimization
Feb 05, 2026The study of tail behaviour of SGD-induced processes has been attracting a lot of interest, due to offering strong guarantees with respect to individual runs of an algorithm. While many works provide high-probability guarantees, quantifying the error rate for a fixed probability threshold, there is a lack of work directly studying the probability of failure, i.e., quantifying the tail decay rate for a fixed error threshold. Moreover, existing results are of finite-time nature, limiting their ability to capture the true long-term tail decay which is more informative for modern learning models, typically trained for millions of iterations. Our work closes these gaps, by studying the long-term tail decay of SGD-based methods through the lens of large deviations theory, establishing several strong results in the process. First, we provide an upper bound on the tails of the gradient norm-squared of the best iterate produced by (vanilla) SGD, for non-convex costs and bounded noise, with long-term decay at rate $e^{-t/\log(t)}$. Next, we relax the noise assumption by considering clipped SGD (c-SGD) under heavy-tailed noise with bounded moment of order $p \in (1,2]$, showing an upper bound with long-term decay at rate $e^{-t^{β_p}/\log(t)}$, where $β_p = \frac{4(p-1)}{3p-2}$ for $p \in (1,2)$ and $e^{-t/\log^2(t)}$ for $p = 2$. Finally, we provide lower bounds on the tail decay, at rate $e^{-t}$, showing that our rates for both SGD and c-SGD are tight, up to poly-logarithmic factors. Notably, our results demonstrate an order of magnitude faster long-term tail decay compared to existing work based on finite-time bounds, which show rates $e^{-\sqrt{t}}$ and $e^{-t^{β_p/2}}$, $p \in (1,2]$, for SGD and c-SGD, respectively. As such, we uncover regimes where the tails decay much faster than previously known, providing stronger long-term guarantees for individual runs.
Modular Federated Learning: A Meta-Framework Perspective
May 13, 2025Federated Learning (FL) enables distributed machine learning training while preserving privacy, representing a paradigm shift for data-sensitive and decentralized environments. Despite its rapid advancements, FL remains a complex and multifaceted field, requiring a structured understanding of its methodologies, challenges, and applications. In this survey, we introduce a meta-framework perspective, conceptualising FL as a composition of modular components that systematically address core aspects such as communication, optimisation, security, and privacy. We provide a historical contextualisation of FL, tracing its evolution from distributed optimisation to modern distributed learning paradigms. Additionally, we propose a novel taxonomy distinguishing Aggregation from Alignment, introducing the concept of alignment as a fundamental operator alongside aggregation. To bridge theory with practice, we explore available FL frameworks in Python, facilitating real-world implementation. Finally, we systematise key challenges across FL sub-fields, providing insights into open research questions throughout the meta-framework modules. By structuring FL within a meta-framework of modular components and emphasising the dual role of Aggregation and Alignment, this survey provides a holistic and adaptable foundation for understanding and advancing FL research and deployment.
A Unified Framework for Gradient-based Clustering of Distributed Data
Feb 02, 2024



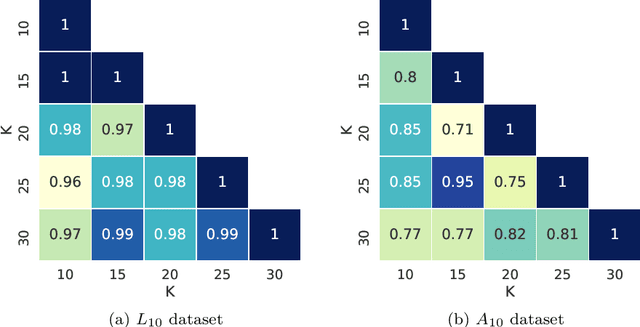
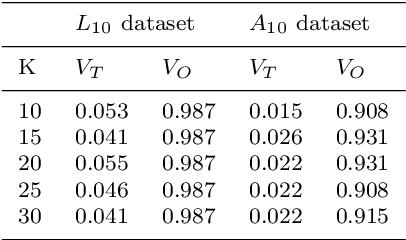
We develop a family of distributed clustering algorithms that work over networks of users. In the proposed scenario, users contain a local dataset and communicate only with their immediate neighbours, with the aim of finding a clustering of the full, joint data. The proposed family, termed Distributed Gradient Clustering (DGC-$\mathcal{F}_\rho$), is parametrized by $\rho \geq 1$, controling the proximity of users' center estimates, with $\mathcal{F}$ determining the clustering loss. Specialized to popular clustering losses like $K$-means and Huber loss, DGC-$\mathcal{F}_\rho$ gives rise to novel distributed clustering algorithms DGC-KM$_\rho$ and DGC-HL$_\rho$, while a novel clustering loss based on the logistic function leads to DGC-LL$_\rho$. We provide a unified analysis and establish several strong results, under mild assumptions. First, the sequence of centers generated by the methods converges to a well-defined notion of fixed point, under any center initialization and value of $\rho$. Second, as $\rho$ increases, the family of fixed points produced by DGC-$\mathcal{F}_\rho$ converges to a notion of consensus fixed points. We show that consensus fixed points of DGC-$\mathcal{F}_{\rho}$ are equivalent to fixed points of gradient clustering over the full data, guaranteeing a clustering of the full data is produced. For the special case of Bregman losses, we show that our fixed points converge to the set of Lloyd points. Numerical experiments on real data confirm our theoretical findings and demonstrate strong performance of the methods.
Distributed Solution of the Inverse Rig Problem in Blendshape Facial Animation
Mar 26, 2023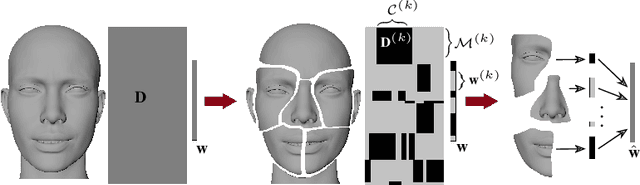


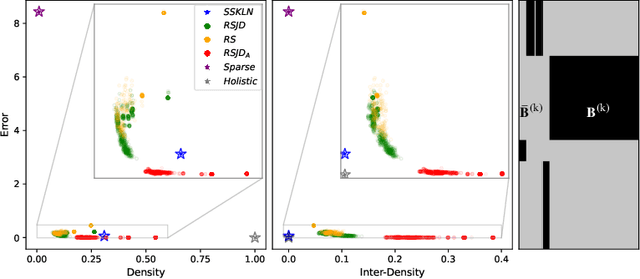
The problem of rig inversion is central in facial animation as it allows for a realistic and appealing performance of avatars. With the increasing complexity of modern blendshape models, execution times increase beyond practically feasible solutions. A possible approach towards a faster solution is clustering, which exploits the spacial nature of the face, leading to a distributed method. In this paper, we go a step further, involving cluster coupling to get more confident estimates of the overlapping components. Our algorithm applies the Alternating Direction Method of Multipliers, sharing the overlapping weights between the subproblems. The results obtained with this technique show a clear advantage over the naive clustered approach, as measured in different metrics of success and visual inspection. The method applies to an arbitrary clustering of the face. We also introduce a novel method for choosing the number of clusters in a data-free manner. The method tends to find a clustering such that the resulting clustering graph is sparse but without losing essential information. Finally, we give a new variant of a data-free clustering algorithm that produces good scores with respect to the mentioned strategy for choosing the optimal clustering.
High-fidelity Interpretable Inverse Rig: An Accurate and Sparse Solution Optimizing the Quartic Blendshape Model
Feb 09, 2023



We propose a method to fit arbitrarily accurate blendshape rig models by solving the inverse rig problem in realistic human face animation. The method considers blendshape models with different levels of added corrections and solves the regularized least-squares problem using coordinate descent, i.e., iteratively estimating blendshape weights. Besides making the optimization easier to solve, this approach ensures that mutually exclusive controllers will not be activated simultaneously and improves the goodness of fit after each iteration. We show experimentally that the proposed method yields solutions with mesh error comparable to or lower than the state-of-the-art approaches while significantly reducing the cardinality of the weight vector (over 20 percent), hence giving a high-fidelity reconstruction of the reference expression that is easier to manipulate in the post-production manually. Python scripts for the algorithm will be publicly available upon acceptance of the paper.
Tax Evasion Risk Management Using a Hybrid Unsupervised Outlier Detection Method
Feb 25, 2021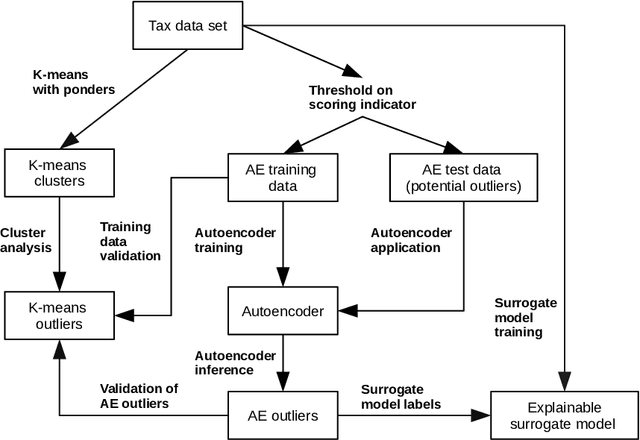
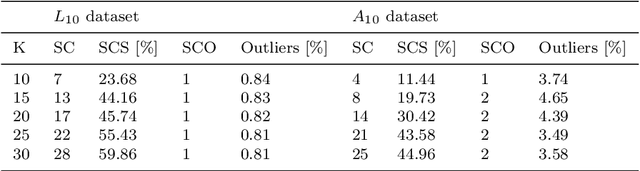
Big data methods are becoming an important tool for tax fraud detection around the world. Unsupervised learning approach is the dominant framework due to the lack of label and ground truth in corresponding data sets although these methods suffer from low interpretability. HUNOD, a novel hybrid unsupervised outlier detection method for tax evasion risk management, is presented in this paper. In contrast to previous methods proposed in the literature, the HUNOD method combines two outlier detection approaches based on two different machine learning designs (i.e, clustering and representational learning) to detect and internally validate outliers in a given tax dataset. The HUNOD method allows its users to incorporate relevant domain knowledge into both constituent outlier detection approaches in order to detect outliers relevant for a given economic context. The interpretability of obtained outliers is achieved by training explainable-by-design surrogate models over results of unsupervised outlier detection methods. The experimental evaluation of the HUNOD method is conducted on two datasets derived from the database on individual personal income tax declarations collected by the Tax Administration of Serbia. The obtained results show that the method indicates between 90% and 98% internally validated outliers depending on the clustering configuration and employed regularization mechanisms for representational learning.