 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Low-Rank Scaled Dot-product Attention
Dec 05, 2024Transformers are widely used for their ability to capture data relations in sequence processing, with great success for a wide range of static tasks. However, the computational and memory footprint of their main component, i.e., the Scaled Dot-product Attention, is commonly overlooked. This makes their adoption in applications involving stream data processing with constraints in response latency, computational and memory resources infeasible. Some works have proposed methods to lower the computational cost of transformers, i.e. low-rank approximations, sparsity in attention, and efficient formulations for Continual Inference. In this paper, we introduce a new formulation of the Scaled Dot-product Attention based on the Nystr\"om approximation that is suitable for Continual Inference. In experiments on Online Audio Classification and Online Action Detection tasks, the proposed Continual Scaled Dot-product Attention can lower the number of operations by up to three orders of magnitude compared to the original Transformers while retaining the predictive performance of competing models.
Efficient Online Processing with Deep Neural Networks
Jun 23, 2023
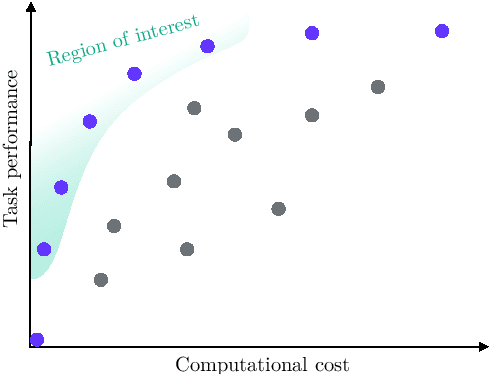


The capabilities and adoption of deep neural networks (DNNs) grow at an exhilarating pace: Vision models accurately classify human actions in videos and identify cancerous tissue in medical scans as precisely than human experts; large language models answer wide-ranging questions, generate code, and write prose, becoming the topic of everyday dinner-table conversations. Even though their uses are exhilarating, the continually increasing model sizes and computational complexities have a dark side. The economic cost and negative environmental externalities of training and serving models is in evident disharmony with financial viability and climate action goals. Instead of pursuing yet another increase in predictive performance, this dissertation is dedicated to the improvement of neural network efficiency. Specifically, a core contribution addresses the efficiency aspects during online inference. Here, the concept of Continual Inference Networks (CINs) is proposed and explored across four publications. CINs extend prior state-of-the-art methods developed for offline processing of spatio-temporal data and reuse their pre-trained weights, improving their online processing efficiency by an order of magnitude. These advances are attained through a bottom-up computational reorganization and judicious architectural modifications. The benefit to online inference is demonstrated by reformulating several widely used network architectures into CINs, including 3D CNNs, ST-GCNs, and Transformer Encoders. An orthogonal contribution tackles the concurrent adaptation and computational acceleration of a large source model into multiple lightweight derived models. Drawing on fusible adapter networks and structured pruning, Structured Pruning Adapters achieve superior predictive accuracy under aggressive pruning using significantly fewer learned weights compared to fine-tuning with pruning.
Structured Pruning Adapters
Nov 21, 2022We propose Structured Pruning Adapters (SPAs), a family of compressing, task-switching network adapters, that accelerate and specialize networks using tiny parameter sets. Specifically, we propose a channel- and a block-based SPA and evaluate them with a suite of pruning methods on both computer vision and natural language processing benchmarks. Compared to regular structured pruning with fine-tuning, our channel-SPA improves accuracy by 6.9% on average while using half the parameters at 90% pruned weights. Alternatively, it can learn adaptations with 17x fewer parameters at 70% pruning with 1.6% lower accuracy. Similarly, our block-SPA requires far fewer parameters than pruning with fine-tuning. Our experimental code and Python library of adapters are available at github.com/lukashedegaard/structured-pruning-adapters.
Continual Inference: A Library for Efficient Online Inference with Deep Neural Networks in PyTorch
Apr 07, 2022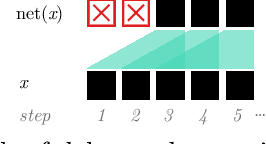


We present Continual Inference, a Python library for implementing Continual Inference Networks (CINs) in PyTorch, a class of Neural Networks designed specifically for efficient inference in both online and batch processing scenarios. We offer a comprehensive introduction and guide to CINs and their implementation in practice, and provide best-practices and code examples for composing complex modules for modern Deep Learning. Continual Inference is readily downloadable via the Python Package Index and at \url{www.github.com/lukashedegaard/continual-inference}.
Online Skeleton-based Action Recognition with Continual Spatio-Temporal Graph Convolutional Networks
Mar 21, 2022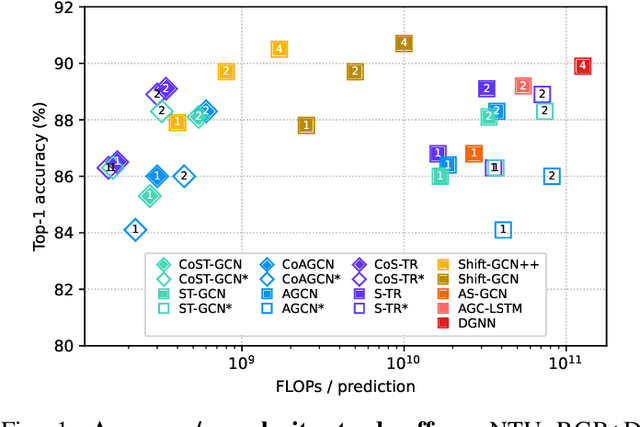


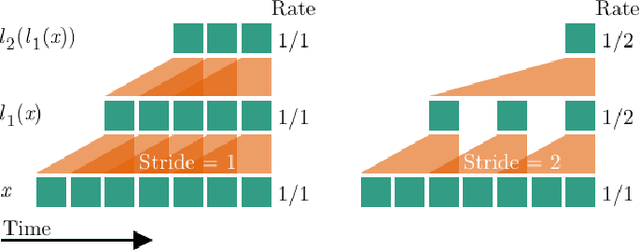
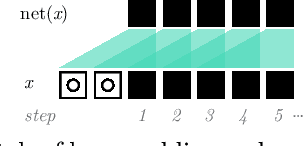
Graph-based reasoning over skeleton data has emerged as a promising approach for human action recognition. However, the application of prior graph-based methods, which predominantly employ whole temporal sequences as their input, to the setting of online inference entails considerable computational redundancy. In this paper, we tackle this issue by reformulating the Spatio-Temporal Graph Convolutional Neural Network as a Continual Inference Network, which can perform step-by-step predictions in time without repeat frame processing. To evaluate our method, we create a continual version of ST-GCN, CoST-GCN, alongside two derived methods with different self-attention mechanisms, CoAGCN and CoS-TR. We investigate weight transfer strategies and architectural modifications for inference acceleration, and perform experiments on the NTU RGB+D 60, NTU RGB+D 120, and Kinetics Skeleton 400 datasets. Retaining similar predictive accuracy, we observe up to 109x reduction in time complexity, on-hardware accelerations of 26x, and reductions in maximum allocated memory of 52% during online inference.
Continual Transformers: Redundancy-Free Attention for Online Inference
Jan 17, 2022Transformers are attention-based sequence transduction models, which have found widespread success in Natural Language Processing and Computer Vision applications. Yet, Transformers in their current form are inherently limited to operate on whole token sequences rather than on one token at a time. Consequently, their use during online inference entails considerable redundancy due to the overlap in successive token sequences. In this work, we propose novel formulations of the Scaled Dot-Product Attention, which enable Transformers to perform efficient online token-by-token inference in a continual input stream. Importantly, our modification is purely to the order of computations, while the produced outputs and learned weights are identical to those of the original Multi-Head Attention. To validate our approach, we conduct experiments on visual, audio, and audio-visual classification and detection tasks, i.e. Online Action Detection on THUMOS14 and TVSeries and Online Audio Classification on GTZAN, with remarkable results. Our continual one-block transformers reduce the floating point operations by respectively 63.5x and 51.5x in the Online Action Detection and Audio Classification experiments at similar predictive performance.
Continual 3D Convolutional Neural Networks for Real-time Processing of Videos
May 31, 2021



This paper introduces Continual 3D Convolutional Neural Networks (Co3D CNNs), a new computational formulation of spatio-temporal 3D CNNs, in which videos are processed frame-by-frame rather than by clip. In online processing tasks demanding frame-wise predictions, Co3D CNNs dispense with the computational redundancies of regular 3D CNNs, namely the repeated convolutions over frames, which appear in multiple clips. While yielding an order of magnitude in computational savings, Co3D CNNs have memory requirements comparable with that of corresponding regular 3D CNNs and are less affected by changes in the size of the temporal receptive field. We show that Continual 3D CNNs initialised on the weights from preexisting state-of-the-art video recognition models reduce the floating point operations for frame-wise computations by 10.0-12.4x while improving accuracy on Kinetics-400 by 2.3-3.8. Moreover, we investigate the transient start-up response of Co3D CNNs and perform an extensive benchmark of online processing speed as well as accuracy for publicly available state-of-the-art 3D CNNs on modern hardware.
Supervised Domain Adaptation: Were we doing Graph Embedding all along?
Apr 23, 2020



The performance of machine learning models tends to suffer when the distributions of the training and test data differ. Domain Adaptation is the process of closing the distribution gap between datasets. In this paper, we show that existing Domain Adaptation methods can be formulated as Graph Embedding methods in which the domain labels of samples coming from the source and target domains are incorporated into the structure of the intrinsic and penalty graphs used for the embedding. To this end, we define the underlying intrinsic and penalty graphs for three state-of-the-art supervised domain adaptation methods. In addition, we propose the Domain Adaptation via Graph Embedding (DAGE) method as a general solution for supervised Domain Adaptation, that can be combined with various graph structures for encoding pair-wise relationships between source and target domain data. Moreover, we highlight some generalisation and reproducibility issues related to the experimental setup commonly used to evaluate the performance of Domain Adaptation methods. We propose a new evaluation setup for more accurately assessing and comparing different supervised DA methods, and report experiments on the standard benchmark datasets Office31 and MNIST-USPS.
Supervised Domain Adaptation using Graph Embedding
Mar 09, 2020



Getting deep convolutional neural networks to perform well requires a large amount of training data. When the available labelled data is small, it is often beneficial to use transfer learning to leverage a related larger dataset (source) in order to improve the performance on the small dataset (target). Among the transfer learning approaches, domain adaptation methods assume that distributions between the two domains are shifted and attempt to realign them. In this paper, we consider the domain adaptation problem from the perspective of dimensionality reduction and propose a generic framework based on graph embedding. Instead of solving the generalised eigenvalue problem, we formulate the graph-preserving criterion as a loss in the neural network and learn a domain-invariant feature transformation in an end-to-end fashion. We show that the proposed approach leads to a powerful Domain Adaptation framework; a simple LDA-inspired instantiation of the framework leads to state-of-the-art performance on two of the most widely used Domain Adaptation benchmarks, Office31 and MNIST to USPS datasets.