 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Graph Convolutional Neural Networks
Jul 02, 2025Estimation of model uncertainty can help improve the explainability of Graph Convolutional Networks and the accuracy of the models at the same time. Uncertainty can also be used in critical applications to verify the results of the model by an expert or additional models. In this paper, we propose Variational Neural Network versions of spatial and spatio-temporal Graph Convolutional Networks. We estimate uncertainty in both outputs and layer-wise attentions of the models, which has the potential for improving model explainability. We showcase the benefits of these models in the social trading analysis and the skeleton-based human action recognition tasks on the Finnish board membership, NTU-60, NTU-120 and Kinetics datasets, where we show improvement in model accuracy in addition to estimated model uncertainties.
Continual Low-Rank Scaled Dot-product Attention
Dec 05, 2024Transformers are widely used for their ability to capture data relations in sequence processing, with great success for a wide range of static tasks. However, the computational and memory footprint of their main component, i.e., the Scaled Dot-product Attention, is commonly overlooked. This makes their adoption in applications involving stream data processing with constraints in response latency, computational and memory resources infeasible. Some works have proposed methods to lower the computational cost of transformers, i.e. low-rank approximations, sparsity in attention, and efficient formulations for Continual Inference. In this paper, we introduce a new formulation of the Scaled Dot-product Attention based on the Nystr\"om approximation that is suitable for Continual Inference. In experiments on Online Audio Classification and Online Action Detection tasks, the proposed Continual Scaled Dot-product Attention can lower the number of operations by up to three orders of magnitude compared to the original Transformers while retaining the predictive performance of competing models.
Uncertainty-Aware AB3DMOT by Variational 3D Object Detection
Feb 12, 2023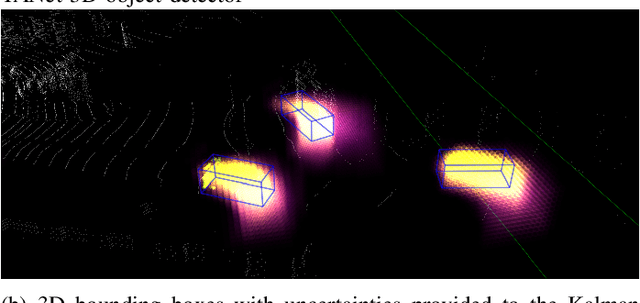
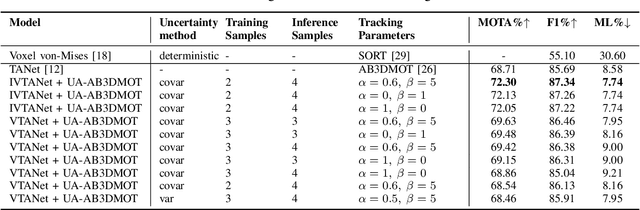
Autonomous driving needs to rely on high-quality 3D object detection to ensure safe navigation in the world. Uncertainty estimation is an effective tool to provide statistically accurate predictions, while the associated detection uncertainty can be used to implement a more safe navigation protocol or include the user in the loop. In this paper, we propose a Variational Neural Network-based TANet 3D object detector to generate 3D object detections with uncertainty and introduce these detections to an uncertainty-aware AB3DMOT tracker. This is done by applying a linear transformation to the estimated uncertainty matrix, which is subsequently used as a measurement noise for the adopted Kalman filter. We implement two ways to estimate output uncertainty, i.e., internally, by computing the variance of the CNNs outputs and then propagating the uncertainty through the post-processing, and externally, by associating the final predictions of different samples and computing the covariance of each predicted box. In experiments, we show that the external uncertainty estimation leads to better results, outperforming both internal uncertainty estimation and classical tracking approaches. Furthermore, we propose a method to initialize the Variational 3D object detector with a pretrained TANet model, which leads to the best performing models.
Variational Voxel Pseudo Image Tracking
Feb 12, 2023


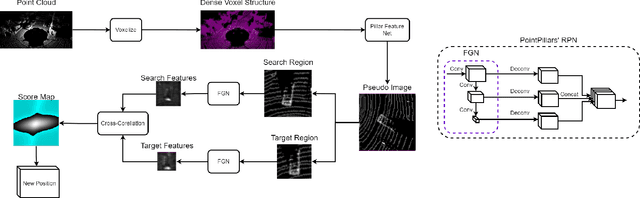
Uncertainty estimation is an important task for critical problems, such as robotics and autonomous driving, because it allows creating statistically better perception models and signaling the model's certainty in its predictions to the decision method or a human supervisor. In this paper, we propose a Variational Neural Network-based version of a Voxel Pseudo Image Tracking (VPIT) method for 3D Single Object Tracking. The Variational Feature Generation Network of the proposed Variational VPIT computes features for target and search regions and the corresponding uncertainties, which are later combined using an uncertainty-aware cross-correlation module in one of two ways: by computing similarity between the corresponding uncertainties and adding it to the regular cross-correlation values, or by penalizing the uncertain feature channels to increase influence of the certain features. In experiments, we show that both methods improve tracking performance, while penalization of uncertain features provides the best uncertainty quality.
Layer Ensembles
Oct 10, 2022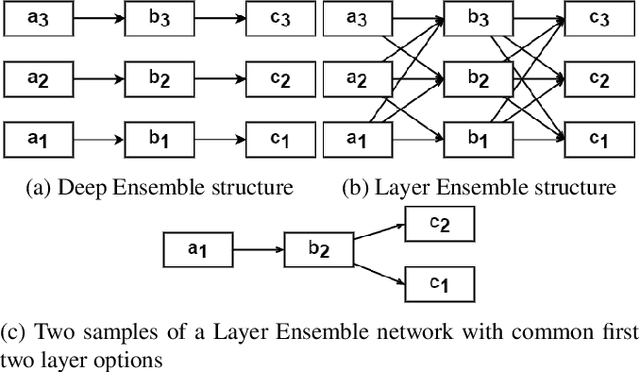
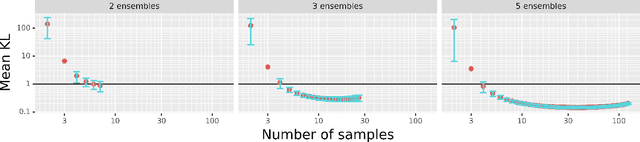
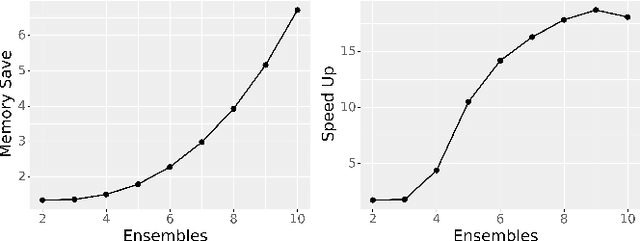
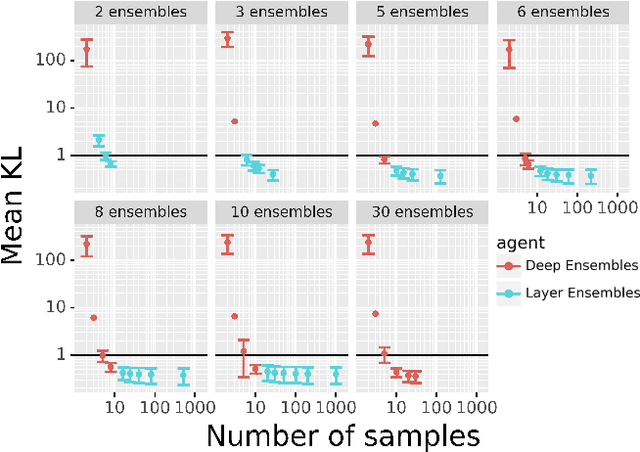
Deep Ensembles, as a type of Bayesian Neural Networks, can be used to estimate uncertainty on the prediction of multiple neural networks by collecting votes from each network and computing the difference in those predictions. In this paper, we introduce a novel method for uncertainty estimation called Layer Ensembles that considers a set of independent categorical distributions for each layer of the network, giving many more possible samples with overlapped layers, than in the regular Deep Ensembles. We further introduce Optimized Layer Ensembles with an inference procedure that reuses common layer outputs, achieving up to 19x speed up and quadratically reducing memory usage. We also show that Layer Ensembles can be further improved by ranking samples, resulting in models that require less memory and time to run while achieving higher uncertainty quality than Deep Ensembles.
Variational Neural Networks
Jul 04, 2022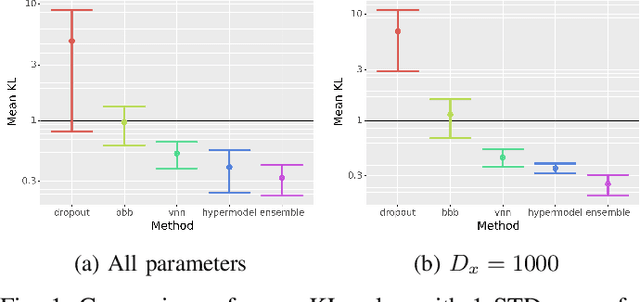
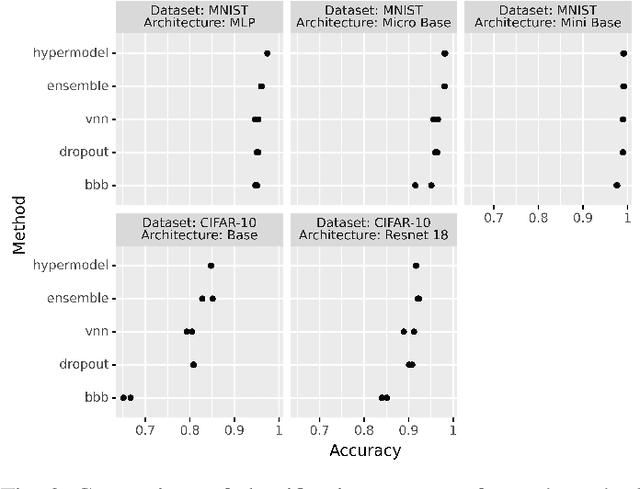
Bayesian Neural Networks (BNNs) provide a tool to estimate the uncertainty of a neural network by considering a distribution over weights and sampling different models for each input. In this paper, we propose a method for uncertainty estimation in neural networks called Variational Neural Network that, instead of considering a distribution over weights, generates parameters for the output distribution of a layer by transforming its inputs with learnable sub-layers. In uncertainty quality estimation experiments, we show that VNNs achieve better uncertainty quality than Monte Carlo Dropout or Bayes By Backpropagation methods.
VPIT: Real-time Embedded Single Object 3D Tracking Using Voxel Pseudo Images
Jun 06, 2022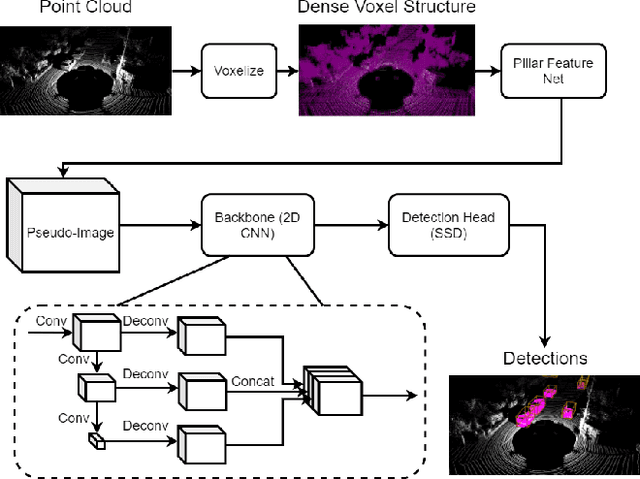


In this paper, we propose a novel voxel-based 3D single object tracking (3D SOT) method called Voxel Pseudo Image Tracking (VPIT). VPIT is the first method that uses voxel pseudo images for 3D SOT. The input point cloud is structured by pillar-based voxelization, and the resulting pseudo image is used as an input to a 2D-like Siamese SOT method. The pseudo image is created in the Bird's-eye View (BEV) coordinates, and therefore the objects in it have constant size. Thus, only the object rotation can change in the new coordinate system and not the object scale. For this reason, we replace multi-scale search with a multi-rotation search, where differently rotated search regions are compared against a single target representation to predict both position and rotation of the object. Experiments on KITTI Tracking dataset show that VPIT is the fastest 3D SOT method and maintains competitive Success and Precision values. Application of a SOT method in a real-world scenario meets with limitations such as lower computational capabilities of embedded devices and a latency-unforgiving environment, where the method is forced to skip certain data frames if the inference speed is not high enough. We implement a real-time evaluation protocol and show that other methods lose most of their performance on embedded devices, while VPIT maintains its ability to track the object.
Analysis of voxel-based 3D object detection methods efficiency for real-time embedded systems
May 21, 2021
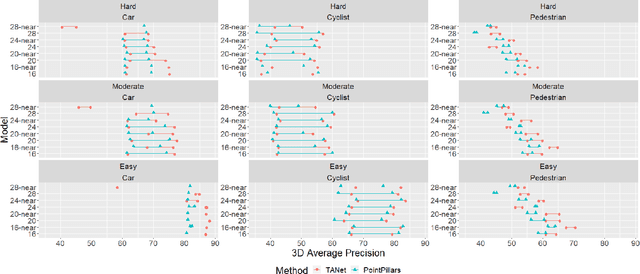
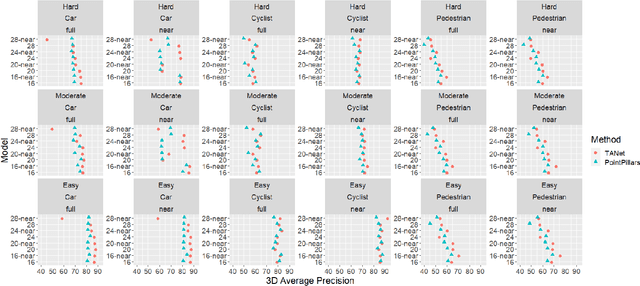
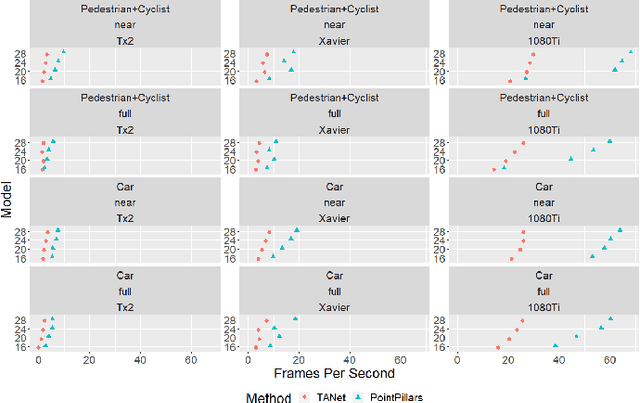
Real-time detection of objects in the 3D scene is one of the tasks an autonomous agent needs to perform for understanding its surroundings. While recent Deep Learning-based solutions achieve satisfactory performance, their high computational cost renders their application in real-life settings in which computations need to be performed on embedded platforms intractable. In this paper, we analyze the efficiency of two popular voxel-based 3D object detection methods providing a good compromise between high performance and speed based on two aspects, their ability to detect objects located at large distances from the agent and their ability to operate in real time on embedded platforms equipped with high-performance GPUs. Our experiments show that these methods mostly fail to detect distant small objects due to the sparsity of the input point clouds at large distances. Moreover, models trained on near objects achieve similar or better performance compared to those trained on all objects in the scene. This means that the models learn object appearance representations mostly from near objects. Our findings suggest that a considerable part of the computations of existing methods is focused on locations of the scene that do not contribute with successful detection. This means that the methods can achieve a speed-up of $40$-$60\%$ by restricting operation to near objects while not sacrificing much in performance.