 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCryptocurrency Portfolio Optimization by Neural Networks
Oct 02, 2023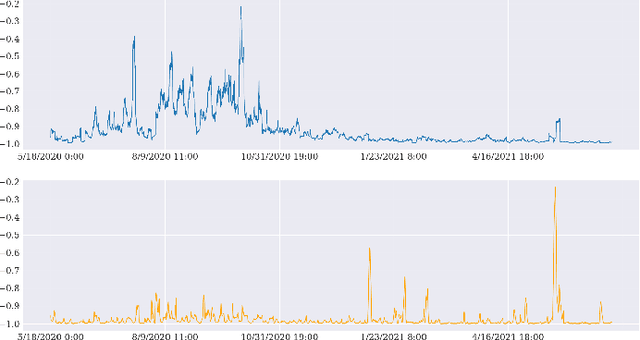
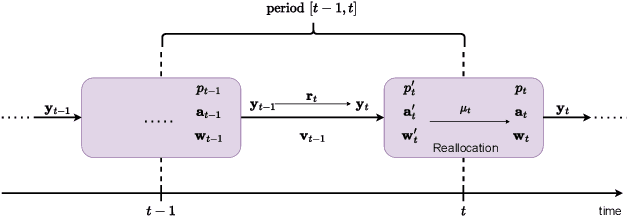
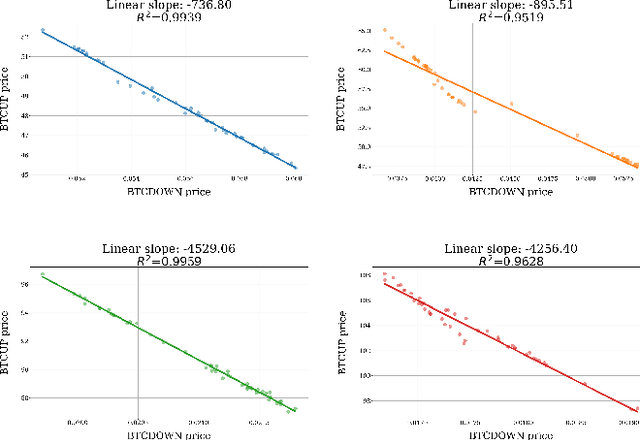
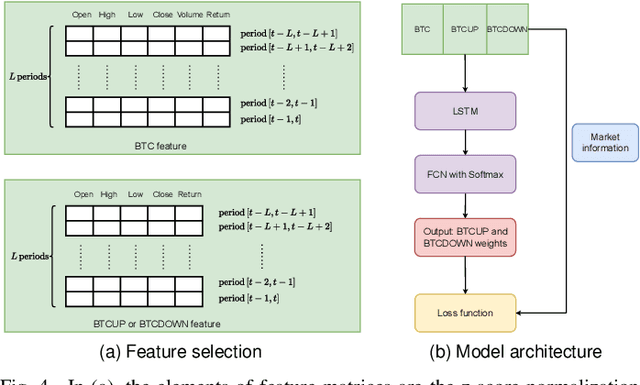
Many cryptocurrency brokers nowadays offer a variety of derivative assets that allow traders to perform hedging or speculation. This paper proposes an effective algorithm based on neural networks to take advantage of these investment products. The proposed algorithm constructs a portfolio that contains a pair of negatively correlated assets. A deep neural network, which outputs the allocation weight of each asset at a time interval, is trained to maximize the Sharpe ratio. A novel loss term is proposed to regulate the network's bias towards a specific asset, thus enforcing the network to learn an allocation strategy that is close to a minimum variance strategy. Extensive experiments were conducted using data collected from Binance spanning 19 months to evaluate the effectiveness of our approach. The backtest results show that the proposed algorithm can produce neural networks that are able to make profits in different market situations.
Recognition of Defective Mineral Wool Using Pruned ResNet Models
Nov 01, 2022



Mineral wool production is a non-linear process that makes it hard to control the final quality. Therefore, having a non-destructive method to analyze the product quality and recognize defective products is critical. For this purpose, we developed a visual quality control system for mineral wool. X-ray images of wool specimens were collected to create a training set of defective and non-defective samples. Afterward, we developed several recognition models based on the ResNet architecture to find the most efficient model. In order to have a light-weight and fast inference model for real-life applicability, two structural pruning methods are applied to the classifiers. Considering the low quantity of the dataset, cross-validation and augmentation methods are used during the training. As a result, we obtained a model with more than 98% accuracy, which in comparison to the current procedure used at the company, it can recognize 20% more defective products.
Augmented Bilinear Network for Incremental Multi-Stock Time-Series Classification
Jul 23, 2022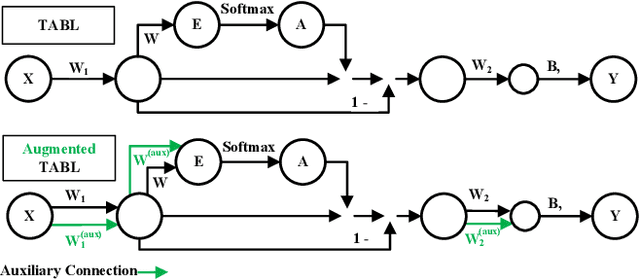
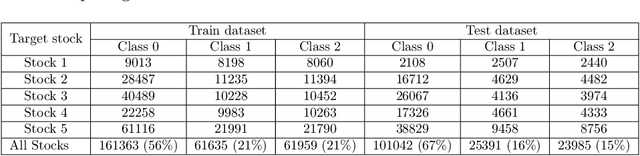
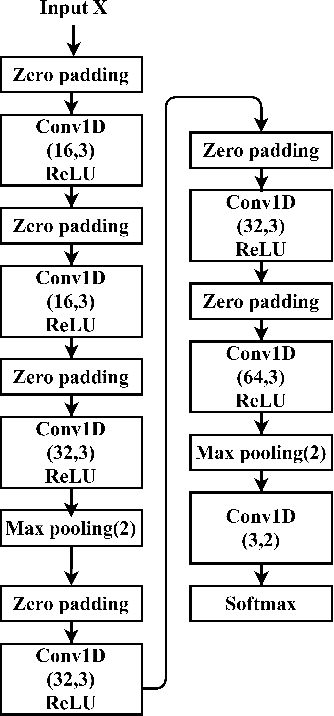
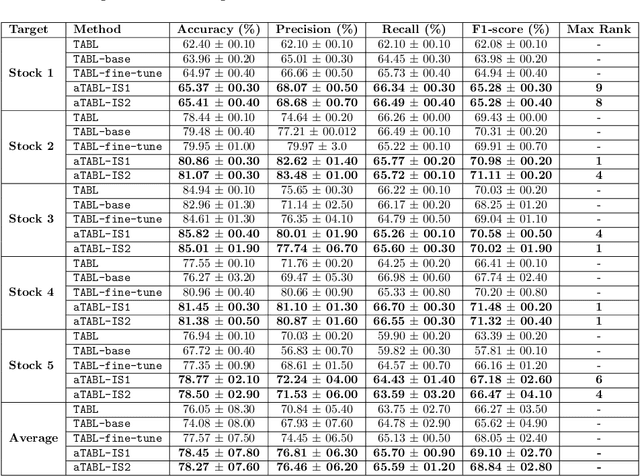
Deep Learning models have become dominant in tackling financial time-series analysis problems, overturning conventional machine learning and statistical methods. Most often, a model trained for one market or security cannot be directly applied to another market or security due to differences inherent in the market conditions. In addition, as the market evolves through time, it is necessary to update the existing models or train new ones when new data is made available. This scenario, which is inherent in most financial forecasting applications, naturally raises the following research question: How to efficiently adapt a pre-trained model to a new set of data while retaining performance on the old data, especially when the old data is not accessible? In this paper, we propose a method to efficiently retain the knowledge available in a neural network pre-trained on a set of securities and adapt it to achieve high performance in new ones. In our method, the prior knowledge encoded in a pre-trained neural network is maintained by keeping existing connections fixed, and this knowledge is adjusted for the new securities by a set of augmented connections, which are optimized using the new data. The auxiliary connections are constrained to be of low rank. This not only allows us to rapidly optimize for the new task but also reduces the storage and run-time complexity during the deployment phase. The efficiency of our approach is empirically validated in the stock mid-price movement prediction problem using a large-scale limit order book dataset. Experimental results show that our approach enhances prediction performance as well as reduces the overall number of network parameters.
Variational Neural Networks
Jul 04, 2022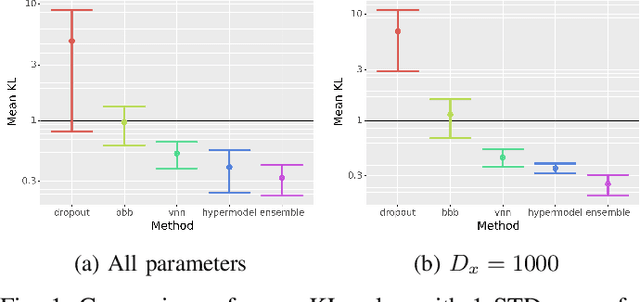
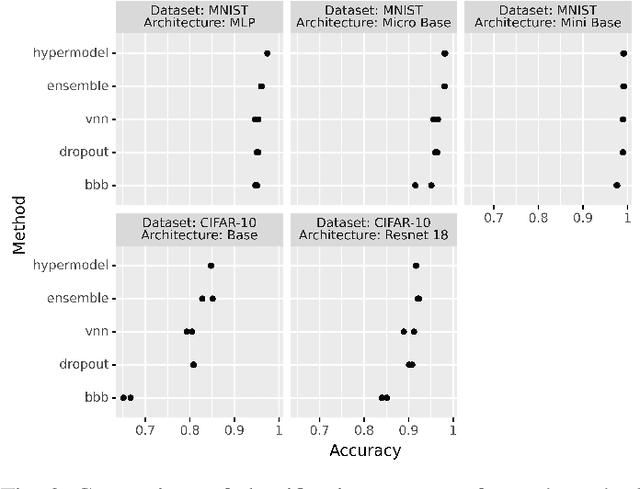
Bayesian Neural Networks (BNNs) provide a tool to estimate the uncertainty of a neural network by considering a distribution over weights and sampling different models for each input. In this paper, we propose a method for uncertainty estimation in neural networks called Variational Neural Network that, instead of considering a distribution over weights, generates parameters for the output distribution of a layer by transforming its inputs with learnable sub-layers. In uncertainty quality estimation experiments, we show that VNNs achieve better uncertainty quality than Monte Carlo Dropout or Bayes By Backpropagation methods.
Multi-head Temporal Attention-Augmented Bilinear Network for Financial time series prediction
Jan 14, 2022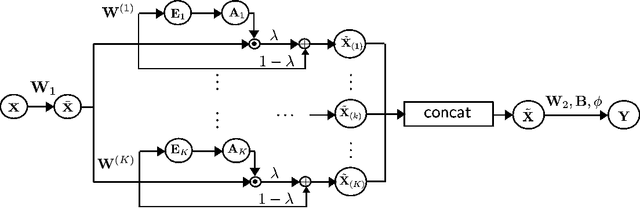
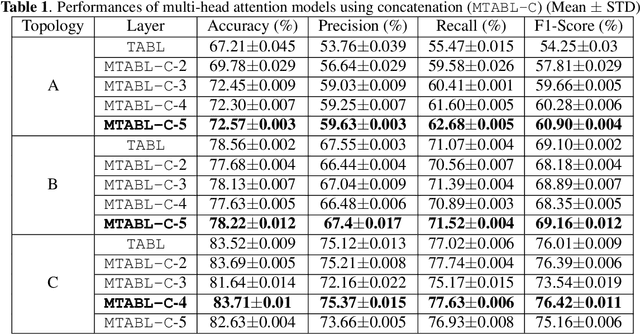
Financial time-series forecasting is one of the most challenging domains in the field of time-series analysis. This is mostly due to the highly non-stationary and noisy nature of financial time-series data. With progressive efforts of the community to design specialized neural networks incorporating prior domain knowledge, many financial analysis and forecasting problems have been successfully tackled. The temporal attention mechanism is a neural layer design that recently gained popularity due to its ability to focus on important temporal events. In this paper, we propose a neural layer based on the ideas of temporal attention and multi-head attention to extend the capability of the underlying neural network in focusing simultaneously on multiple temporal instances. The effectiveness of our approach is validated using large-scale limit-order book market data to forecast the direction of mid-price movements. Our experiments show that the use of multi-head temporal attention modules leads to enhanced prediction performances compared to baseline models.
Remote Multilinear Compressive Learning with Adaptive Compression
Sep 02, 2021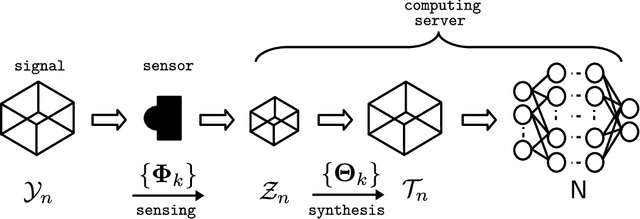
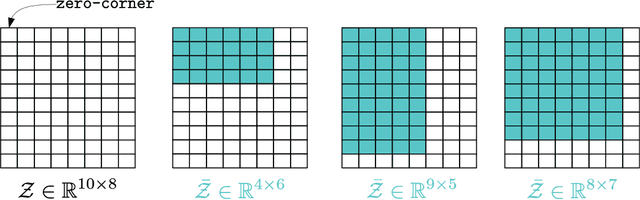
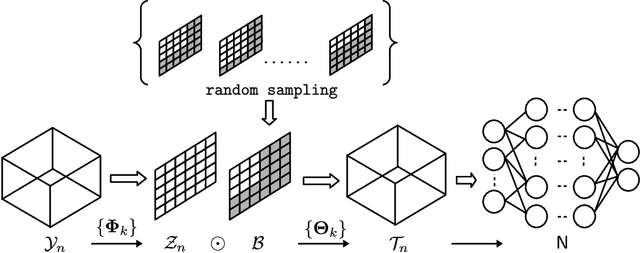
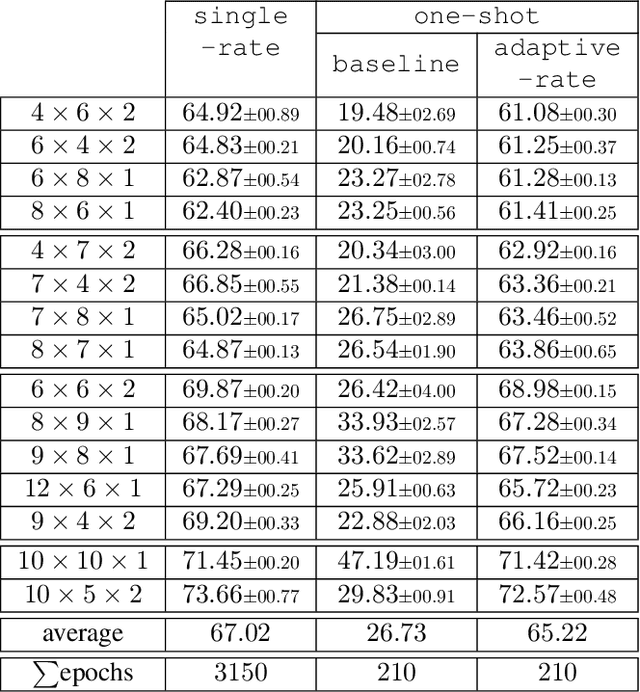
Multilinear Compressive Learning (MCL) is an efficient signal acquisition and learning paradigm for multidimensional signals. The level of signal compression affects the detection or classification performance of a MCL model, with higher compression rates often associated with lower inference accuracy. However, higher compression rates are more amenable to a wider range of applications, especially those that require low operating bandwidth and minimal energy consumption such as Internet-of-Things (IoT) applications. Many communication protocols provide support for adaptive data transmission to maximize the throughput and minimize energy consumption. By developing compressive sensing and learning models that can operate with an adaptive compression rate, we can maximize the informational content throughput of the whole application. In this paper, we propose a novel optimization scheme that enables such a feature for MCL models. Our proposal enables practical implementation of adaptive compressive signal acquisition and inference systems. Experimental results demonstrated that the proposed approach can significantly reduce the amount of computations required during the training phase of remote learning systems but also improve the informational content throughput via adaptive-rate sensing.
Bilinear Input Normalization for Neural Networks in Financial Forecasting
Sep 01, 2021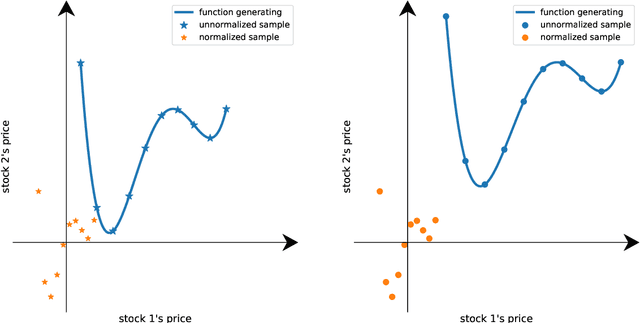
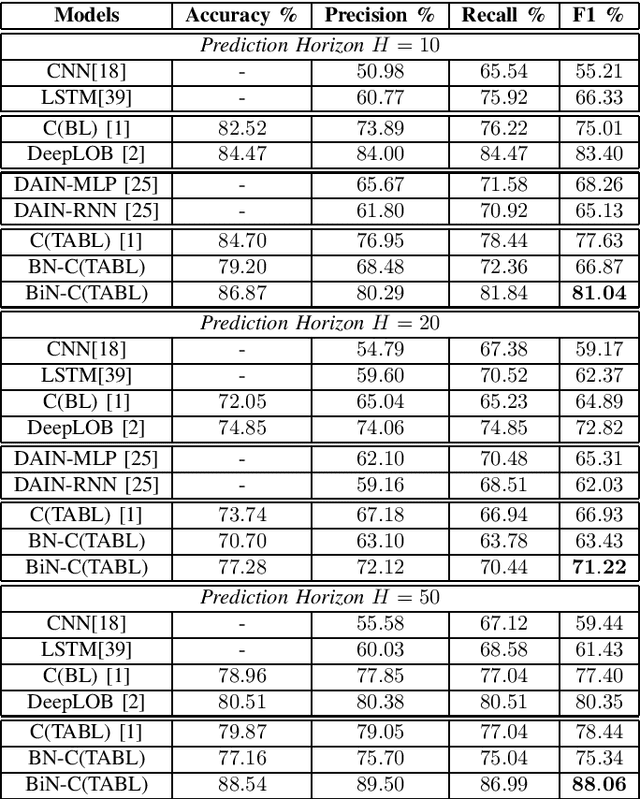
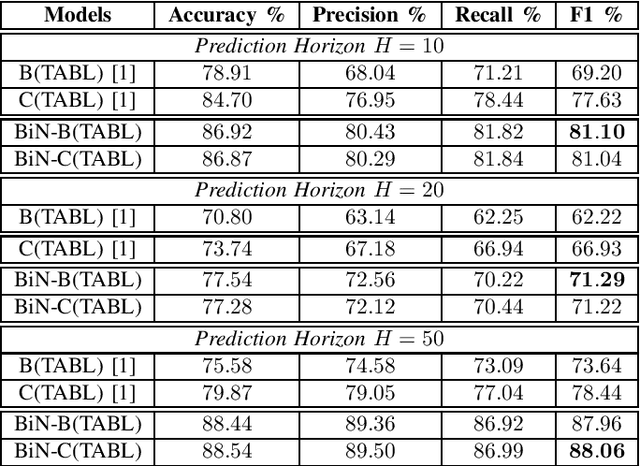
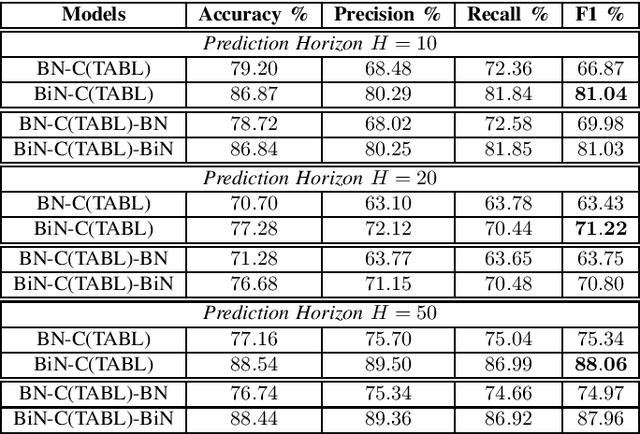
Data normalization is one of the most important preprocessing steps when building a machine learning model, especially when the model of interest is a deep neural network. This is because deep neural network optimized with stochastic gradient descent is sensitive to the input variable range and prone to numerical issues. Different than other types of signals, financial time-series often exhibit unique characteristics such as high volatility, non-stationarity and multi-modality that make them challenging to work with, often requiring expert domain knowledge for devising a suitable processing pipeline. In this paper, we propose a novel data-driven normalization method for deep neural networks that handle high-frequency financial time-series. The proposed normalization scheme, which takes into account the bimodal characteristic of financial multivariate time-series, requires no expert knowledge to preprocess a financial time-series since this step is formulated as part of the end-to-end optimization process. Our experiments, conducted with state-of-the-arts neural networks and high-frequency data from two large-scale limit order books coming from the Nordic and US markets, show significant improvements over other normalization techniques in forecasting future stock price dynamics.
Knowledge Distillation By Sparse Representation Matching
Mar 31, 2021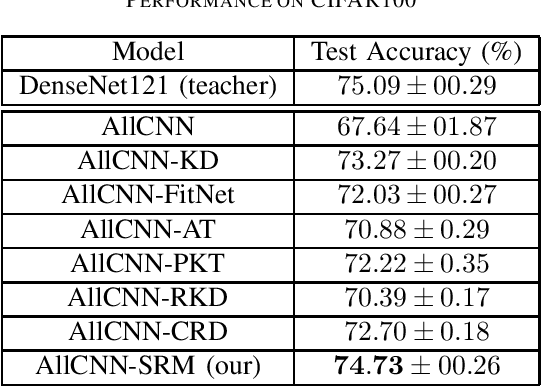

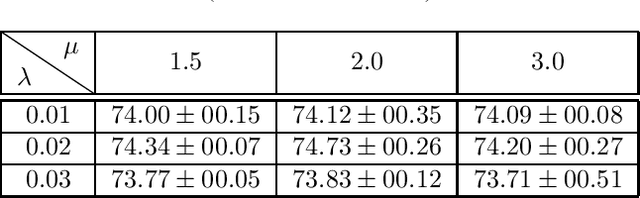

Knowledge Distillation refers to a class of methods that transfers the knowledge from a teacher network to a student network. In this paper, we propose Sparse Representation Matching (SRM), a method to transfer intermediate knowledge obtained from one Convolutional Neural Network (CNN) to another by utilizing sparse representation learning. SRM first extracts sparse representations of the hidden features of the teacher CNN, which are then used to generate both pixel-level and image-level labels for training intermediate feature maps of the student network. We formulate SRM as a neural processing block, which can be efficiently optimized using stochastic gradient descent and integrated into any CNN in a plug-and-play manner. Our experiments demonstrate that SRM is robust to architectural differences between the teacher and student networks, and outperforms other KD techniques across several datasets.
Performance Indicator in Multilinear Compressive Learning
Sep 22, 2020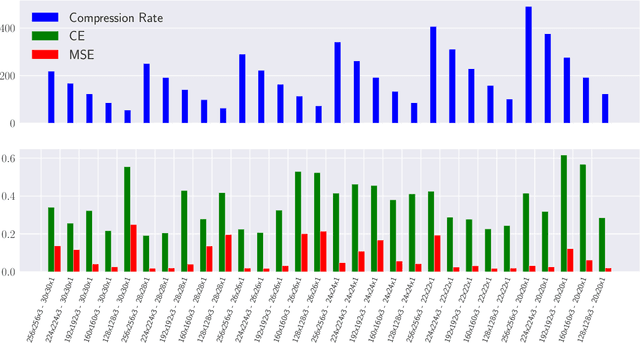
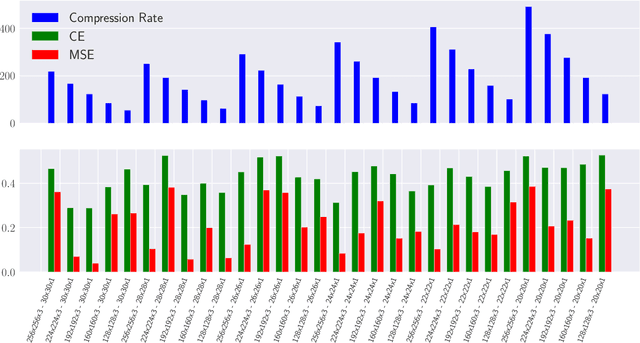
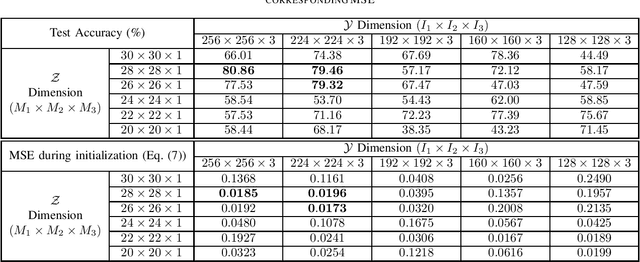
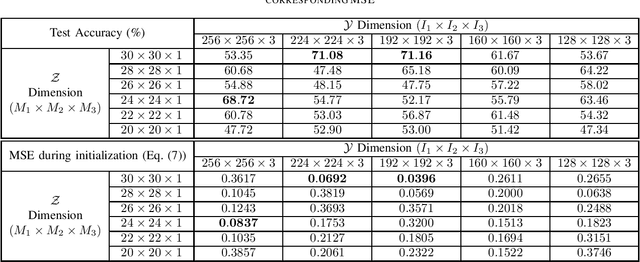
Recently, the Multilinear Compressive Learning (MCL) framework was proposed to efficiently optimize the sensing and learning steps when working with multidimensional signals, i.e. tensors. In Compressive Learning in general, and in MCL in particular, the number of compressed measurements captured by a compressive sensing device characterizes the storage requirement or the bandwidth requirement for transmission. This number, however, does not completely characterize the learning performance of a MCL system. In this paper, we analyze the relationship between the input signal resolution, the number of compressed measurements and the learning performance of MCL. Our empirical analysis shows that the reconstruction error obtained at the initialization step of MCL strongly correlates with the learning performance, thus can act as a good indicator to efficiently characterize learning performances obtained from different sensor configurations without optimizing the entire system.
Attention-based Neural Bag-of-Features Learning for Sequence Data
May 25, 2020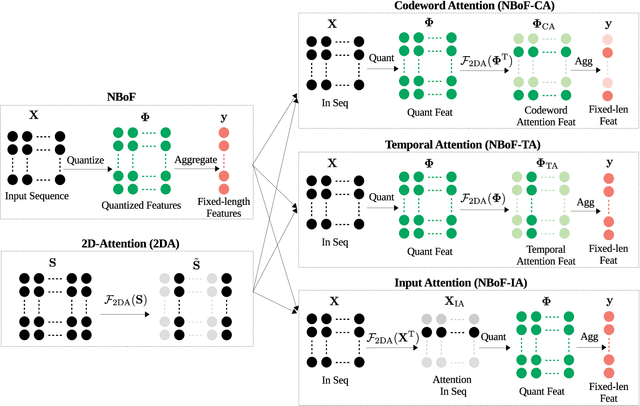
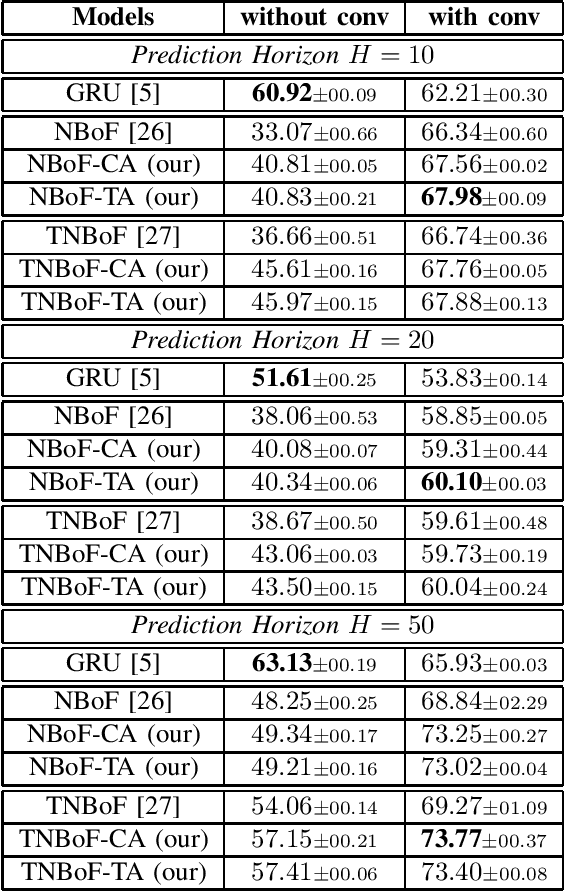

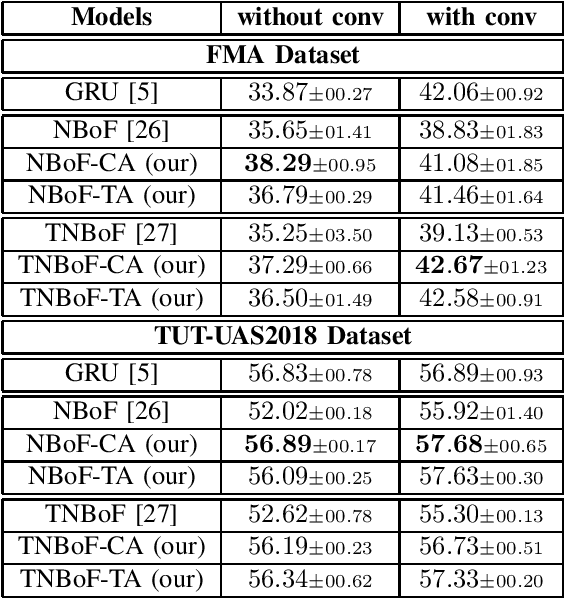
In this paper, we propose 2D-Attention (2DA), a generic attention formulation for sequence data, which acts as a complementary computation block that can detect and focus on relevant sources of information for the given learning objective. The proposed attention module is incorporated into the recently proposed Neural Bag of Feature (NBoF) model to enhance its learning capacity. Since 2DA acts as a plug-in layer, injecting it into different computation stages of the NBoF model results in different 2DA-NBoF architectures, each of which possesses a unique interpretation. We conducted extensive experiments in financial forecasting, audio analysis as well as medical diagnosis problems to benchmark the proposed formulations in comparison with existing methods, including the widely used Gated Recurrent Units. Our empirical analysis shows that the proposed attention formulations can not only improve performances of NBoF models but also make them resilient to noisy data.