 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-Aware Gaussian Graph Repair for Robust Graph Neural Networks
Jun 02, 2026Graph neural networks have achieved strong performance on graph-structured data, but their effectiveness depends heavily on the quality of the observed graph. In real applications, graph topology is often imperfect: noisy edges may connect unrelated nodes, while missing edges may prevent useful information from being propagated. Existing robust graph learning methods mainly address this problem by removing suspicious edges or by learning a new graph structure during training. However, edge removal alone cannot recover missing connections, and graph structure learning may introduce additional optimization complexity. In this paper, we propose Topology-Aware Gaussian Repair (TAGR), a simple graph repair framework for robust message passing in graph neural networks. Instead of learning a dense adjacency matrix, TAGR constructs a sparse feature-neighborhood graph using an adaptive Gaussian kernel and combines it with a topology-aware residual correction of the observed graph. The Gaussian repair component introduces auxiliary edges between feature-similar nodes, while the residual correction preserves and reweights the original topology according to local feature and structural consistency. The repaired graph can be used directly with standard graph neural networks without changing their architectures. Extensive experiments on benchmark citation networks show that TAGR improves the robustness of GNNs under both noisy-edge and missing-edge settings. The analysis further show that Gaussian feature-neighborhood repair provides the main robustness gain, while topology-aware residual correction improves stability when the observed graph is incomplete. These results suggest that effective graph robustness can be achieved through lightweight sparse graph repair rather than dense graph structure learning.
LOBERT: Generative AI Foundation Model for Limit Order Book Messages
Nov 16, 2025Modeling the dynamics of financial Limit Order Books (LOB) at the message level is challenging due to irregular event timing, rapid regime shifts, and the reactions of high-frequency traders to visible order flow. Previous LOB models require cumbersome data representations and lack adaptability outside their original tasks, leading us to introduce LOBERT, a general-purpose encoder-only foundation model for LOB data suitable for downstream fine-tuning. LOBERT adapts the original BERT architecture for LOB data by using a novel tokenization scheme that treats complete multi-dimensional messages as single tokens while retaining continuous representations of price, volume, and time. With these methods, LOBERT achieves leading performance in tasks such as predicting mid-price movements and next messages, while reducing the required context length compared to previous methods.
Variational Graph Convolutional Neural Networks
Jul 02, 2025Estimation of model uncertainty can help improve the explainability of Graph Convolutional Networks and the accuracy of the models at the same time. Uncertainty can also be used in critical applications to verify the results of the model by an expert or additional models. In this paper, we propose Variational Neural Network versions of spatial and spatio-temporal Graph Convolutional Networks. We estimate uncertainty in both outputs and layer-wise attentions of the models, which has the potential for improving model explainability. We showcase the benefits of these models in the social trading analysis and the skeleton-based human action recognition tasks on the Finnish board membership, NTU-60, NTU-120 and Kinetics datasets, where we show improvement in model accuracy in addition to estimated model uncertainties.
Learning hidden cascades via classification
May 16, 2025The spreading dynamics in social networks are often studied under the assumption that individuals' statuses, whether informed or infected, are fully observable. However, in many real-world situations, such statuses remain unobservable, which is crucial for determining an individual's potential to further spread the infection. While this final status is hidden, intermediate indicators such as symptoms of infection are observable and provide important insights into the spread process. We propose a partial observability-aware Machine Learning framework to learn the characteristics of the spreading model. We term the method Distribution Classification, which utilizes the power of classifiers to infer the underlying transmission dynamics. We evaluate our method on two types of synthetic networks and extend the study to a real-world insider trading network. Results show that the method performs well, especially on complex networks with high cyclic connectivity, supporting its utility in analyzing real-world spreading phenomena where direct observation of individual statuses is not possible.
Time-Series Foundation Model for Value-at-Risk
Oct 15, 2024



This study is the first to explore the application of a time-series foundation model for VaR estimation. Foundation models, pre-trained on vast and varied datasets, can be used in a zero-shot setting with relatively minimal data or further improved through finetuning. We compare the performance of Google's model, called TimesFM, against conventional parametric and non-parametric models, including GARCH, Generalized Autoregressive Score (GAS), and empirical quantile estimates, using daily returns from the S\&P 100 index and its constituents over 19 years. Our backtesting results indicate that, in terms of the actual-over-expected ratio, the fine-tuned TimesFM model consistently outperforms traditional methods. Regarding the quantile score loss function, it achieves performance comparable to the best econometric approach, the GAS model. Overall, the foundation model is either the best or among the top performers in forecasting VaR across the 0.01, 0.025, 0.05, and 0.1 VaR levels. We also found that fine-tuning significantly improves the results, and the model should not be used in zero-shot settings. Overall, foundation models can provide completely alternative approaches to traditional econometric methods, yet there are challenges to be tackled.
Forecasting mortality associated emergency department crowding
Oct 10, 2024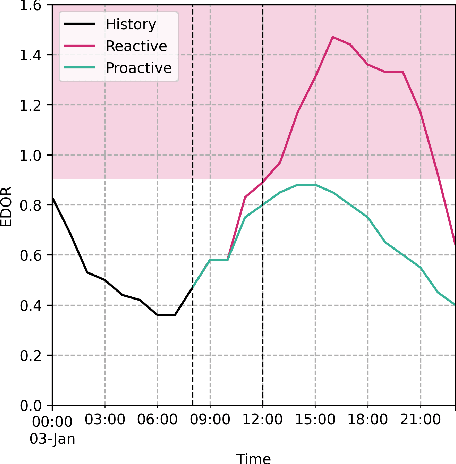
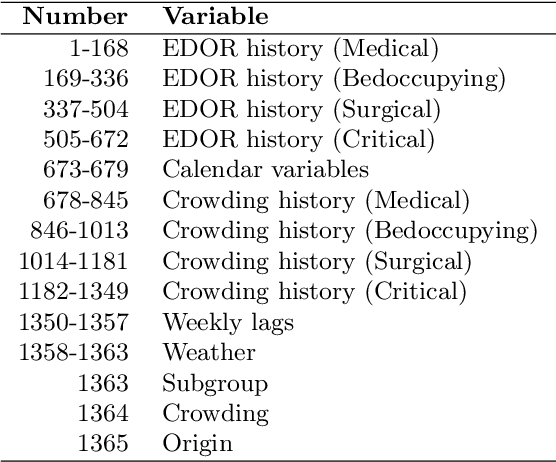
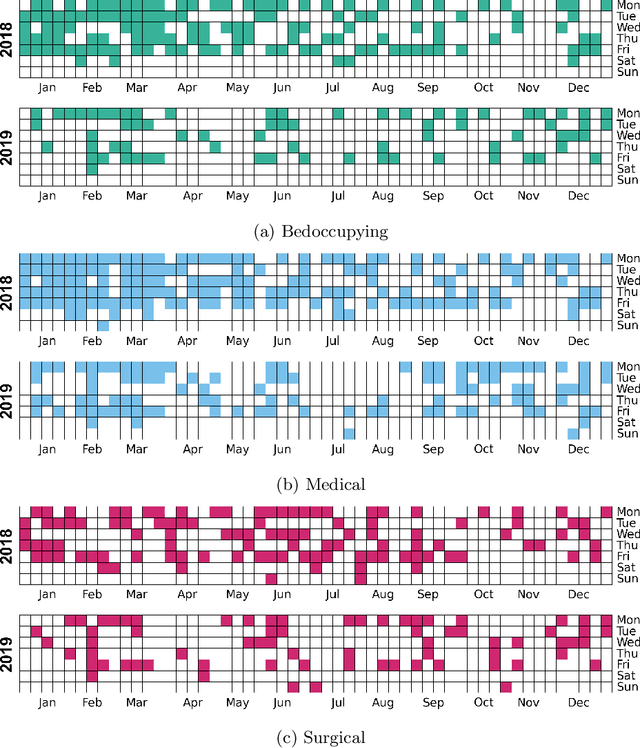

Emergency department (ED) crowding is a global public health issue that has been repeatedly associated with increased mortality. Predicting future service demand would enable preventative measures aiming to eliminate crowding along with it's detrimental effects. Recent findings in our ED indicate that occupancy ratios exceeding 90% are associated with increased 10-day mortality. In this paper, we aim to predict these crisis periods using retrospective data from a large Nordic ED with a LightGBM model. We provide predictions for the whole ED and individually for it's different operational sections. We demonstrate that afternoon crowding can be predicted at 11 a.m. with an AUC of 0.82 (95% CI 0.78-0.86) and at 8 a.m. with an AUC up to 0.79 (95% CI 0.75-0.83). Consequently we show that forecasting mortality-associated crowding using anonymous administrative data is feasible.
Cryptocurrency Portfolio Optimization by Neural Networks
Oct 02, 2023
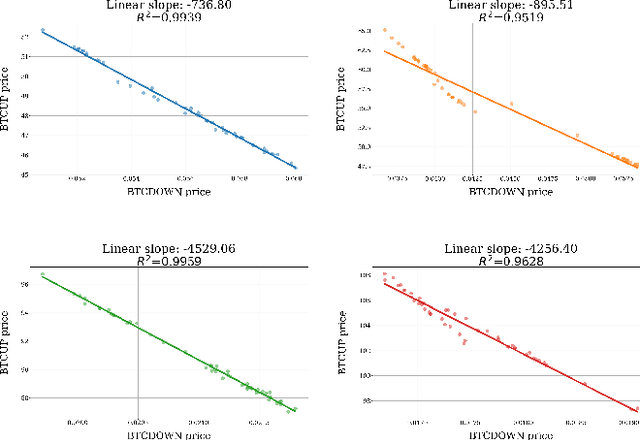
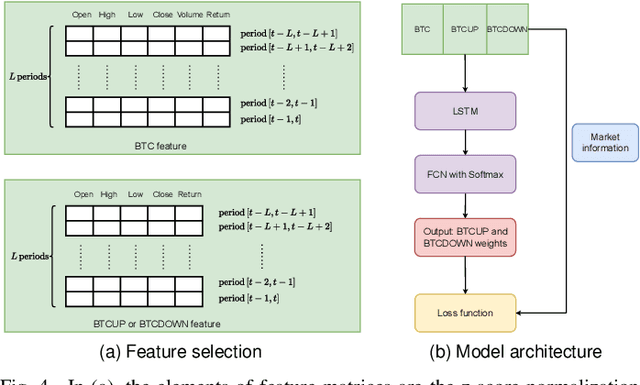
Many cryptocurrency brokers nowadays offer a variety of derivative assets that allow traders to perform hedging or speculation. This paper proposes an effective algorithm based on neural networks to take advantage of these investment products. The proposed algorithm constructs a portfolio that contains a pair of negatively correlated assets. A deep neural network, which outputs the allocation weight of each asset at a time interval, is trained to maximize the Sharpe ratio. A novel loss term is proposed to regulate the network's bias towards a specific asset, thus enforcing the network to learn an allocation strategy that is close to a minimum variance strategy. Extensive experiments were conducted using data collected from Binance spanning 19 months to evaluate the effectiveness of our approach. The backtest results show that the proposed algorithm can produce neural networks that are able to make profits in different market situations.
Credit Card Fraud Detection with Subspace Learning-based One-Class Classification
Sep 26, 2023


In an increasingly digitalized commerce landscape, the proliferation of credit card fraud and the evolution of sophisticated fraudulent techniques have led to substantial financial losses. Automating credit card fraud detection is a viable way to accelerate detection, reducing response times and minimizing potential financial losses. However, addressing this challenge is complicated by the highly imbalanced nature of the datasets, where genuine transactions vastly outnumber fraudulent ones. Furthermore, the high number of dimensions within the feature set gives rise to the ``curse of dimensionality". In this paper, we investigate subspace learning-based approaches centered on One-Class Classification (OCC) algorithms, which excel in handling imbalanced data distributions and possess the capability to anticipate and counter the transactions carried out by yet-to-be-invented fraud techniques. The study highlights the potential of subspace learning-based OCC algorithms by investigating the limitations of current fraud detection strategies and the specific challenges of credit card fraud detection. These algorithms integrate subspace learning into the data description; hence, the models transform the data into a lower-dimensional subspace optimized for OCC. Through rigorous experimentation and analysis, the study validated that the proposed approach helps tackle the curse of dimensionality and the imbalanced nature of credit card data for automatic fraud detection to mitigate financial losses caused by fraudulent activities.
Forecasting Emergency Department Crowding with Advanced Machine Learning Models and Multivariable Input
Aug 31, 2023Emergency department (ED) crowding is a significant threat to patient safety and it has been repeatedly associated with increased mortality. Forecasting future service demand has the potential patient outcomes. Despite active research on the subject, several gaps remain: 1) proposed forecasting models have become outdated due to quick influx of advanced machine learning models (ML), 2) amount of multivariable input data has been limited and 3) discrete performance metrics have been rarely reported. In this study, we document the performance of a set of advanced ML models in forecasting ED occupancy 24 hours ahead. We use electronic health record data from a large, combined ED with an extensive set of explanatory variables, including the availability of beds in catchment area hospitals, traffic data from local observation stations, weather variables, etc. We show that N-BEATS and LightGBM outpeform benchmarks with 11 % and 9 % respective improvements and that DeepAR predicts next day crowding with an AUC of 0.76 (95 % CI 0.69-0.84). To the best of our knowledge, this is the first study to document the superiority of LightGBM and N-BEATS over statistical benchmarks in the context of ED forecasting.
Optimum Output Long Short-Term Memory Cell for High-Frequency Trading Forecasting
Apr 20, 2023



High-frequency trading requires fast data processing without information lags for precise stock price forecasting. This high-paced stock price forecasting is usually based on vectors that need to be treated as sequential and time-independent signals due to the time irregularities that are inherent in high-frequency trading. A well-documented and tested method that considers these time-irregularities is a type of recurrent neural network, named long short-term memory neural network. This type of neural network is formed based on cells that perform sequential and stale calculations via gates and states without knowing whether their order, within the cell, is optimal. In this paper, we propose a revised and real-time adjusted long short-term memory cell that selects the best gate or state as its final output. Our cell is running under a shallow topology, has a minimal look-back period, and is trained online. This revised cell achieves lower forecasting error compared to other recurrent neural networks for online high-frequency trading forecasting tasks such as the limit order book mid-price prediction as it has been tested on two high-liquid US and two less-liquid Nordic stocks.