 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the State of Synchronization of Financial Time Series using Cross Recurrence Plots
Nov 02, 2022Cross-correlation analysis is a powerful tool for understanding the mutual dynamics of time series. This study introduces a new method for predicting the future state of synchronization of the dynamics of two financial time series. To this end, we use the cross-recurrence plot analysis as a nonlinear method for quantifying the multidimensional coupling in the time domain of two time series and for determining their state of synchronization. We adopt a deep learning framework for methodologically addressing the prediction of the synchronization state based on features extracted from dynamically sub-sampled cross-recurrence plots. We provide extensive experiments on several stocks, major constituents of the S\&P100 index, to empirically validate our approach. We find that the task of predicting the state of synchronization of two time series is in general rather difficult, but for certain pairs of stocks attainable with very satisfactory performance.
Distribution Agnostic Symbolic Representations for Time Series Dimensionality Reduction and Online Anomaly Detection
May 20, 2021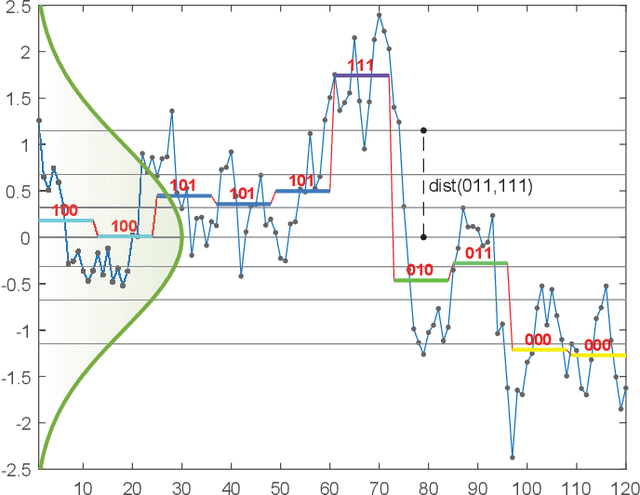
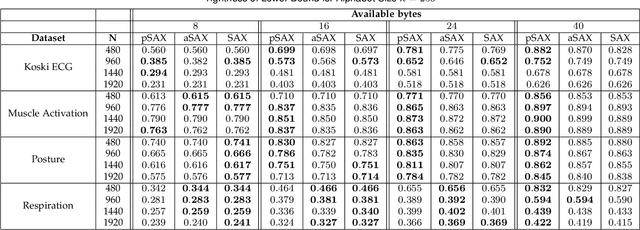
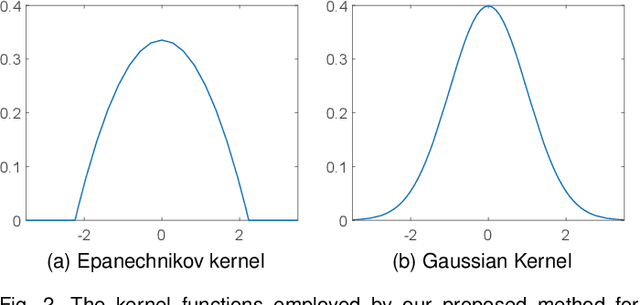
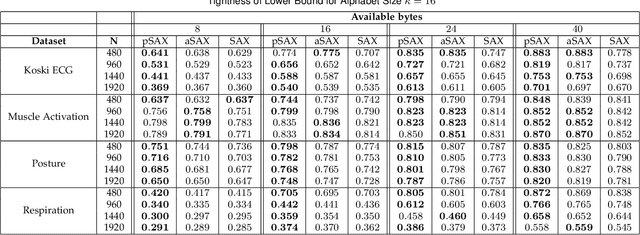
Due to the importance of the lower bounding distances and the attractiveness of symbolic representations, the family of symbolic aggregate approximations (SAX) has been used extensively for encoding time series data. However, typical SAX-based methods rely on two restrictive assumptions; the Gaussian distribution and equiprobable symbols. This paper proposes two novel data-driven SAX-based symbolic representations, distinguished by their discretization steps. The first representation, oriented for general data compaction and indexing scenarios, is based on the combination of kernel density estimation and Lloyd-Max quantization to minimize the information loss and mean squared error in the discretization step. The second method, oriented for high-level mining tasks, employs the Mean-Shift clustering method and is shown to enhance anomaly detection in the lower-dimensional space. Besides, we verify on a theoretical basis a previously observed phenomenon of the intrinsic process that results in a lower than the expected variance of the intermediate piecewise aggregate approximation. This phenomenon causes an additional information loss but can be avoided with a simple modification. The proposed representations possess all the attractive properties of the conventional SAX method. Furthermore, experimental evaluation on real-world datasets demonstrates their superiority compared to the traditional SAX and an alternative data-driven SAX variant.