 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Deep Learning for Computer-Aided Design: A Survey
Feb 27, 2024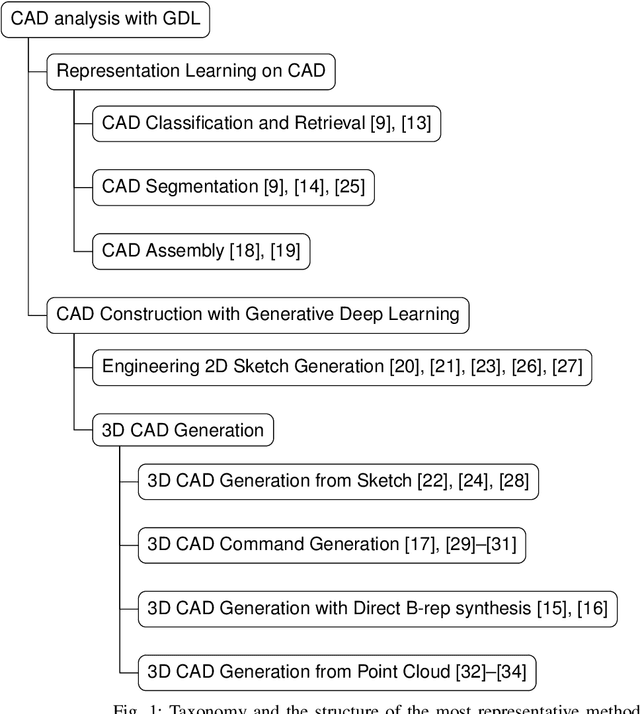


Geometric Deep Learning techniques have become a transformative force in the field of Computer-Aided Design (CAD), and have the potential to revolutionize how designers and engineers approach and enhance the design process. By harnessing the power of machine learning-based methods, CAD designers can optimize their workflows, save time and effort while making better informed decisions, and create designs that are both innovative and practical. The ability to process the CAD designs represented by geometric data and to analyze their encoded features enables the identification of similarities among diverse CAD models, the proposition of alternative designs and enhancements, and even the generation of novel design alternatives. This survey offers a comprehensive overview of learning-based methods in computer-aided design across various categories, including similarity analysis and retrieval, 2D and 3D CAD model synthesis, and CAD generation from point clouds. Additionally, it provides a complete list of benchmark datasets and their characteristics, along with open-source codes that have propelled research in this domain. The final discussion delves into the challenges prevalent in this field, followed by potential future research directions in this rapidly evolving field.
Learning Diversified Feature Representations for Facial Expression Recognition in the Wild
Oct 17, 2022Diversity of the features extracted by deep neural networks is important for enhancing the model generalization ability and accordingly its performance in different learning tasks. Facial expression recognition in the wild has attracted interest in recent years due to the challenges existing in this area for extracting discriminative and informative features from occluded images in real-world scenarios. In this paper, we propose a mechanism to diversify the features extracted by CNN layers of state-of-the-art facial expression recognition architectures for enhancing the model capacity in learning discriminative features. To evaluate the effectiveness of the proposed approach, we incorporate this mechanism in two state-of-the-art models to (i) diversify local/global features in an attention-based model and (ii) diversify features extracted by different learners in an ensemble-based model. Experimental results on three well-known facial expression recognition in-the-wild datasets, AffectNet, FER+, and RAF-DB, show the effectiveness of our method, achieving the state-of-the-art performance of 89.99% on RAF-DB, 89.34% on FER+ and the competitive accuracy of 60.02% on AffectNet dataset.
Online Skeleton-based Action Recognition with Continual Spatio-Temporal Graph Convolutional Networks
Mar 21, 2022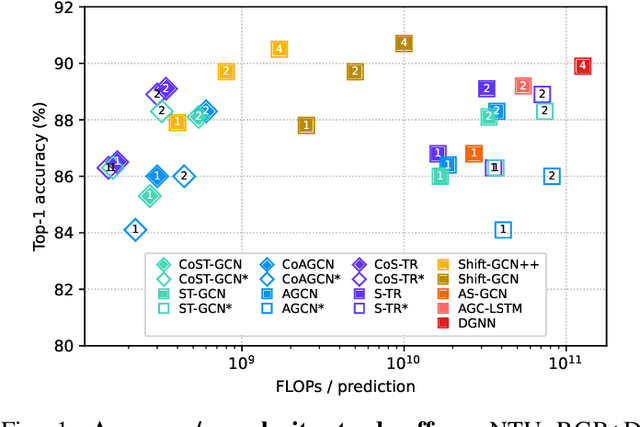


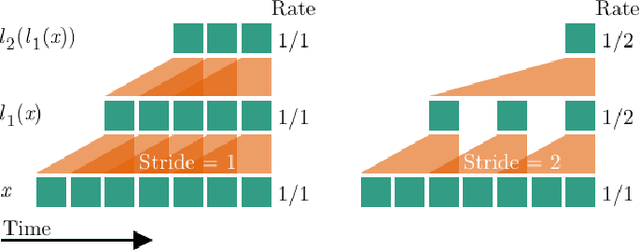
Graph-based reasoning over skeleton data has emerged as a promising approach for human action recognition. However, the application of prior graph-based methods, which predominantly employ whole temporal sequences as their input, to the setting of online inference entails considerable computational redundancy. In this paper, we tackle this issue by reformulating the Spatio-Temporal Graph Convolutional Neural Network as a Continual Inference Network, which can perform step-by-step predictions in time without repeat frame processing. To evaluate our method, we create a continual version of ST-GCN, CoST-GCN, alongside two derived methods with different self-attention mechanisms, CoAGCN and CoS-TR. We investigate weight transfer strategies and architectural modifications for inference acceleration, and perform experiments on the NTU RGB+D 60, NTU RGB+D 120, and Kinetics Skeleton 400 datasets. Retaining similar predictive accuracy, we observe up to 109x reduction in time complexity, on-hardware accelerations of 26x, and reductions in maximum allocated memory of 52% during online inference.
Progressive Spatio-Temporal Bilinear Network with Monte Carlo Dropout for Landmark-based Facial Expression Recognition with Uncertainty Estimation
Jun 08, 2021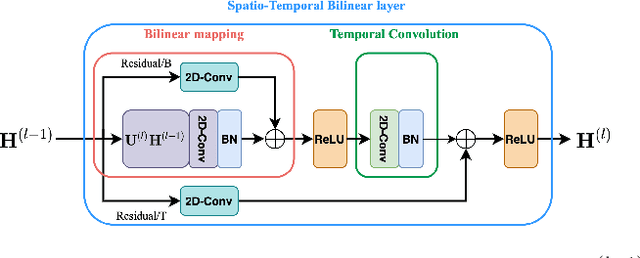
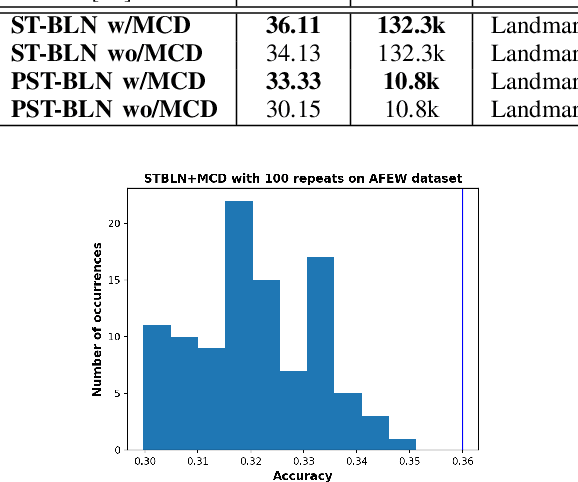

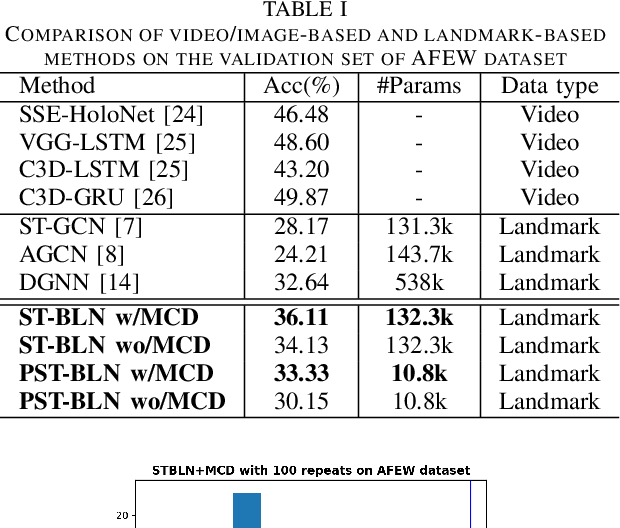
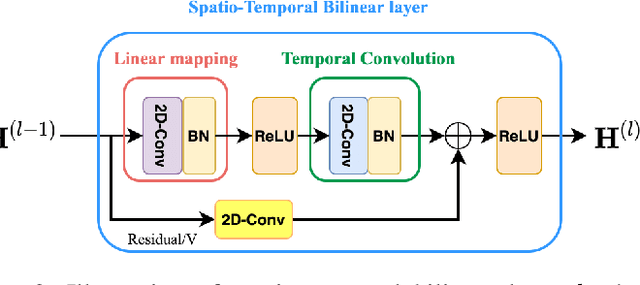
Deep neural networks have been widely used for feature learning in facial expression recognition systems. However, small datasets and large intra-class variability can lead to overfitting. In this paper, we propose a method which learns an optimized compact network topology for real-time facial expression recognition utilizing localized facial landmark features. Our method employs a spatio-temporal bilinear layer as backbone to capture the motion of facial landmarks during the execution of a facial expression effectively. Besides, it takes advantage of Monte Carlo Dropout to capture the model's uncertainty which is of great importance to analyze and treat uncertain cases. The performance of our method is evaluated on three widely used datasets and it is comparable to that of video-based state-of-the-art methods while it has much less complexity.
Progressive Spatio-Temporal Graph Convolutional Network for Skeleton-Based Human Action Recognition
Nov 11, 2020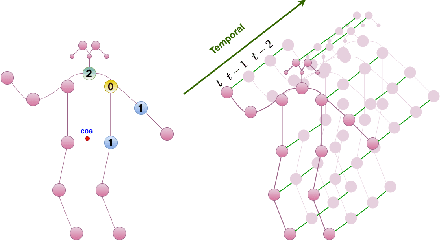

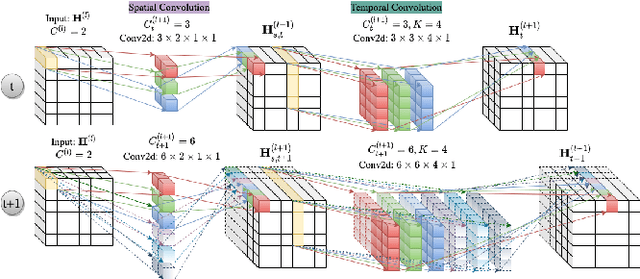
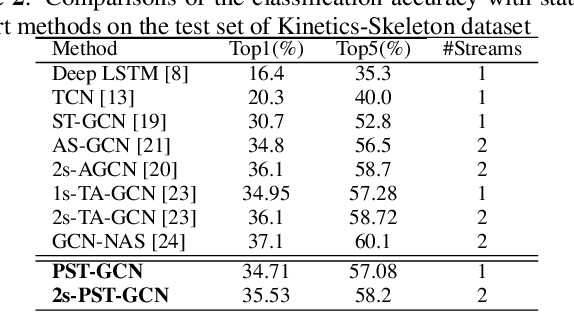
Graph convolutional networks (GCNs) have been very successful in skeleton-based human action recognition where the sequence of skeletons is modeled as a graph. However, most of the GCN-based methods in this area train a deep feed-forward network with a fixed topology that leads to high computational complexity and restricts their application in low computation scenarios. In this paper, we propose a method to automatically find a compact and problem-specific topology for spatio-temporal graph convolutional networks in a progressive manner. Experimental results on two widely used datasets for skeleton-based human action recognition indicate that the proposed method has competitive or even better classification performance compared to the state-of-the-art methods with much lower computational complexity.
On the spatial attention in Spatio-Temporal Graph Convolutional Networks for skeleton-based human action recognition
Nov 07, 2020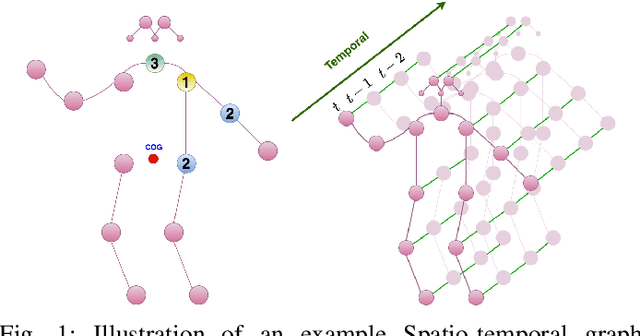
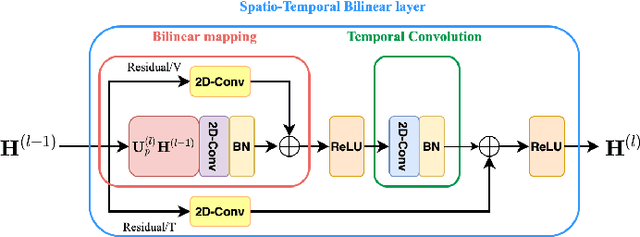
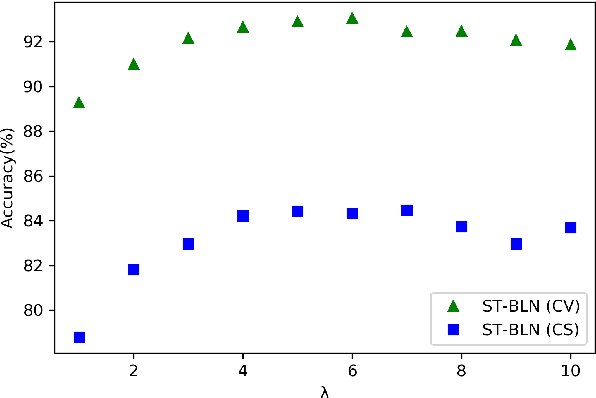
Graph convolutional networks (GCNs) achieved promising performance in skeleton-based human action recognition by modeling a sequence of skeletons as a spatio-temporal graph. Most of the recently proposed GCN-based methods improve the performance by learning the graph structure at each layer of the network using a spatial attention applied on a predefined graph Adjacency matrix that is optimized jointly with model's parameters in an end-to-end manner. In this paper, we analyze the spatial attention used in spatio-temporal GCN layers and propose a symmetric spatial attention for better reflecting the symmetric property of the relative positions of the human body joints when executing actions. We also highlight the connection of spatio-temporal GCN layers employing additive spatial attention to bilinear layers, and we propose the spatio-temporal bilinear network (ST-BLN) which does not require the use of predefined Adjacency matrices and allows for more flexible design of the model. Experimental results show that the three models lead to effectively the same performance. Moreover, by exploiting the flexibility provided by the proposed ST-BLN, one can increase the efficiency of the model.
Temporal Attention-Augmented Graph Convolutional Network for Efficient Skeleton-Based Human Action Recognition
Nov 03, 2020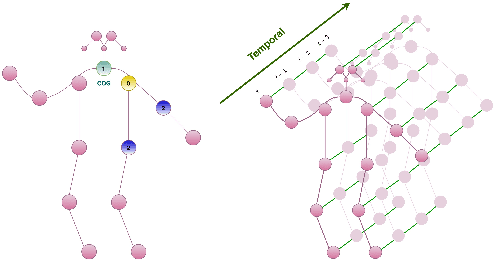
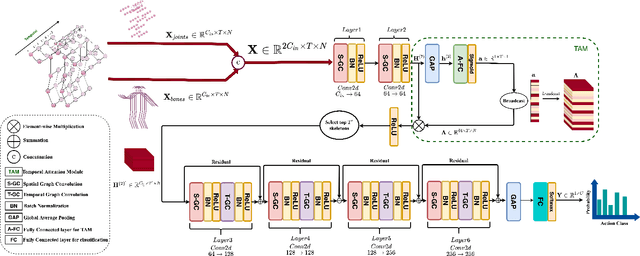
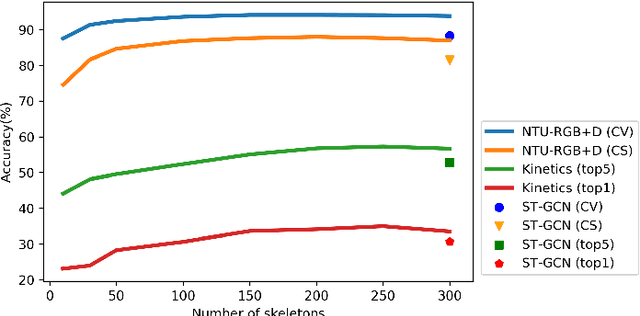
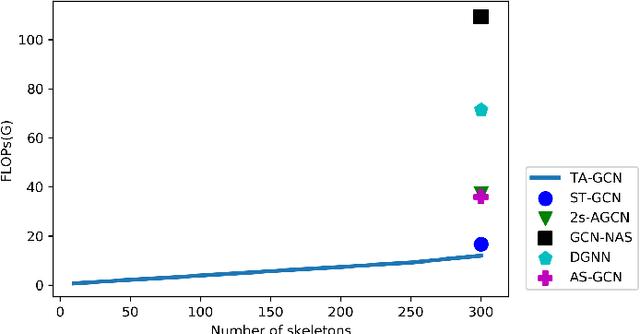
Graph convolutional networks (GCNs) have been very successful in modeling non-Euclidean data structures, like sequences of body skeletons forming actions modeled as spatio-temporal graphs. Most GCN-based action recognition methods use deep feed-forward networks with high computational complexity to process all skeletons in an action. This leads to a high number of floating point operations (ranging from 16G to 100G FLOPs) to process a single sample, making their adoption in restricted computation application scenarios infeasible. In this paper, we propose a temporal attention module (TAM) for increasing the efficiency in skeleton-based action recognition by selecting the most informative skeletons of an action at the early layers of the network. We incorporate the TAM in a light-weight GCN topology to further reduce the overall number of computations. Experimental results on two benchmark datasets show that the proposed method outperforms with a large margin the baseline GCN-based method while having 2.9 times less number of computations. Moreover, it performs on par with the state-of-the-art with up to 9.6 times less number of computations.
Progressive Graph Convolutional Networks for Semi-Supervised Node Classification
Mar 27, 2020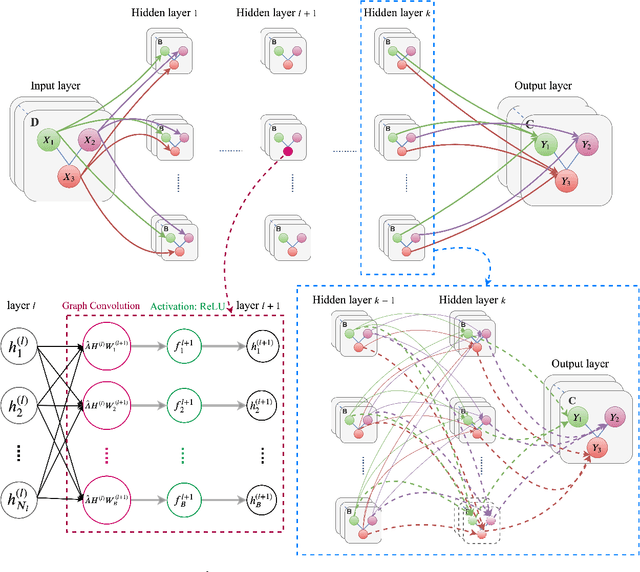

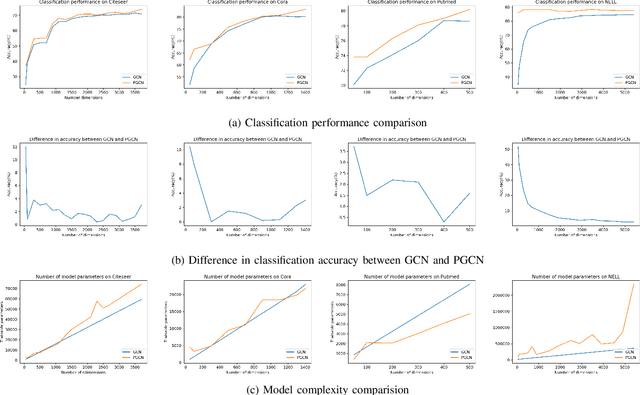
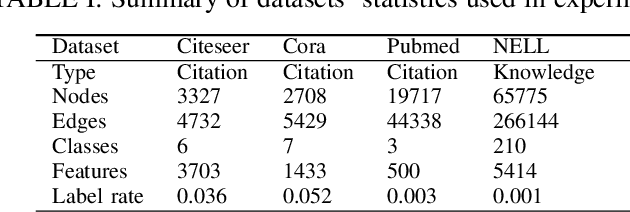
Graph convolutional networks have been successful in addressing graph-based tasks such as semi-supervised node classification. Existing methods use a network structure defined by the user based on experimentation with fixed number of layers and employ a layer-wise propagation rule to obtain the node embeddings. Designing an automatic process to define a problem-dependant architecture for graph convolutional networks can greatly help to reduce the computational complexity of the training process. In this paper, we propose a method to automatically build compact and task-specific graph convolutional networks. Experimental results on widely used publicly available datasets indicate that the proposed method outperforms the related graph-based learning algorithms in terms of classification performance and network compactness.