 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the spatial attention in Spatio-Temporal Graph Convolutional Networks for skeleton-based human action recognition
Paper and Code
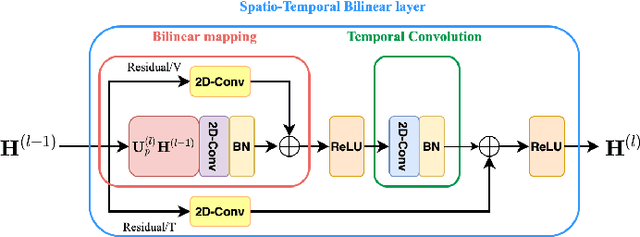
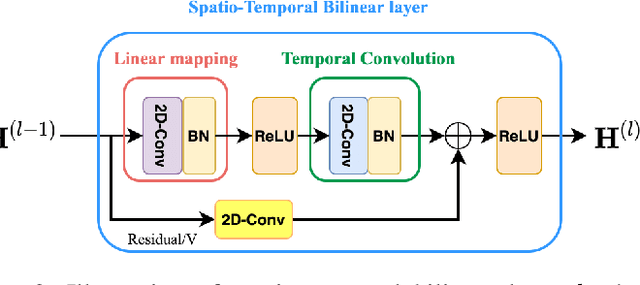
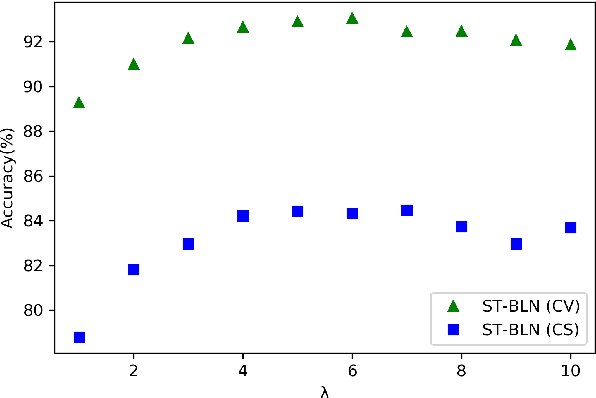
Nov 07, 2020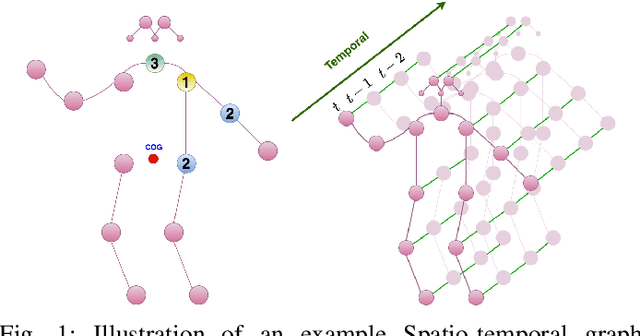
Graph convolutional networks (GCNs) achieved promising performance in skeleton-based human action recognition by modeling a sequence of skeletons as a spatio-temporal graph. Most of the recently proposed GCN-based methods improve the performance by learning the graph structure at each layer of the network using a spatial attention applied on a predefined graph Adjacency matrix that is optimized jointly with model's parameters in an end-to-end manner. In this paper, we analyze the spatial attention used in spatio-temporal GCN layers and propose a symmetric spatial attention for better reflecting the symmetric property of the relative positions of the human body joints when executing actions. We also highlight the connection of spatio-temporal GCN layers employing additive spatial attention to bilinear layers, and we propose the spatio-temporal bilinear network (ST-BLN) which does not require the use of predefined Adjacency matrices and allows for more flexible design of the model. Experimental results show that the three models lead to effectively the same performance. Moreover, by exploiting the flexibility provided by the proposed ST-BLN, one can increase the efficiency of the model.