 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Attention-Augmented Graph Convolutional Network for Efficient Skeleton-Based Human Action Recognition
Paper and Code
Nov 03, 2020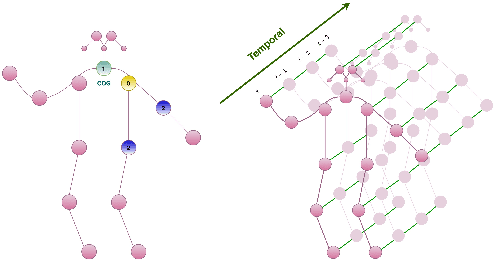
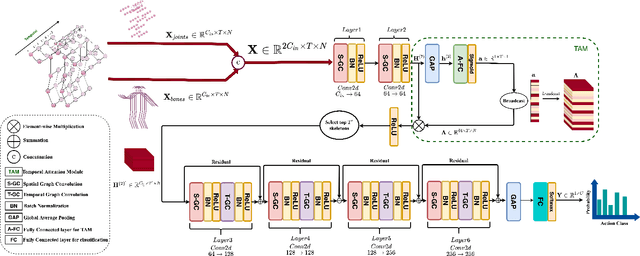
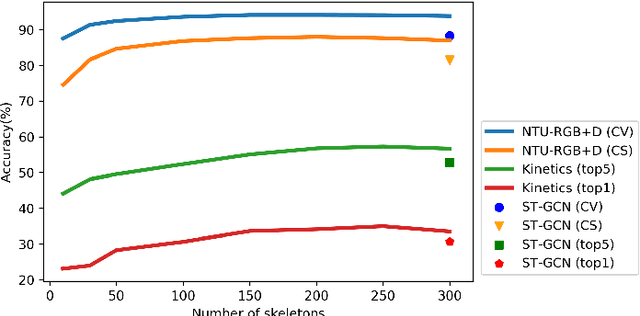
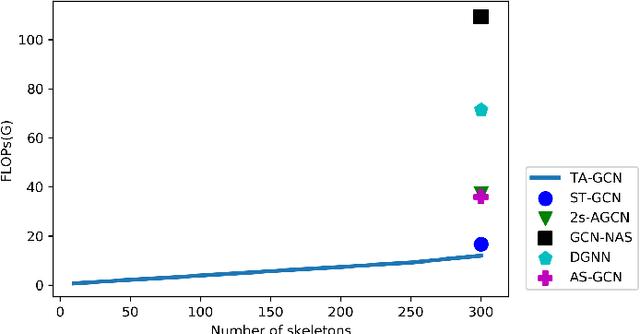
Graph convolutional networks (GCNs) have been very successful in modeling non-Euclidean data structures, like sequences of body skeletons forming actions modeled as spatio-temporal graphs. Most GCN-based action recognition methods use deep feed-forward networks with high computational complexity to process all skeletons in an action. This leads to a high number of floating point operations (ranging from 16G to 100G FLOPs) to process a single sample, making their adoption in restricted computation application scenarios infeasible. In this paper, we propose a temporal attention module (TAM) for increasing the efficiency in skeleton-based action recognition by selecting the most informative skeletons of an action at the early layers of the network. We incorporate the TAM in a light-weight GCN topology to further reduce the overall number of computations. Experimental results on two benchmark datasets show that the proposed method outperforms with a large margin the baseline GCN-based method while having 2.9 times less number of computations. Moreover, it performs on par with the state-of-the-art with up to 9.6 times less number of computations.