 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Pruning Adapters
Nov 21, 2022We propose Structured Pruning Adapters (SPAs), a family of compressing, task-switching network adapters, that accelerate and specialize networks using tiny parameter sets. Specifically, we propose a channel- and a block-based SPA and evaluate them with a suite of pruning methods on both computer vision and natural language processing benchmarks. Compared to regular structured pruning with fine-tuning, our channel-SPA improves accuracy by 6.9% on average while using half the parameters at 90% pruned weights. Alternatively, it can learn adaptations with 17x fewer parameters at 70% pruning with 1.6% lower accuracy. Similarly, our block-SPA requires far fewer parameters than pruning with fine-tuning. Our experimental code and Python library of adapters are available at github.com/lukashedegaard/structured-pruning-adapters.
NTP : A Neural Network Topology Profiler
May 25, 2019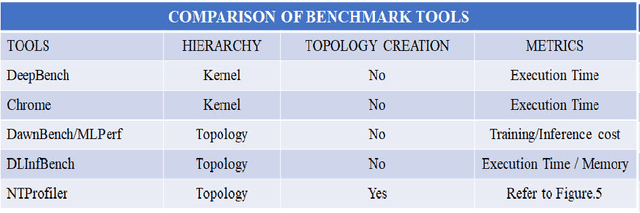
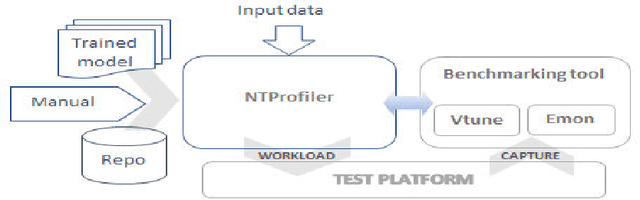
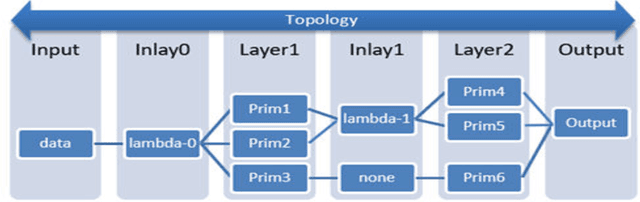
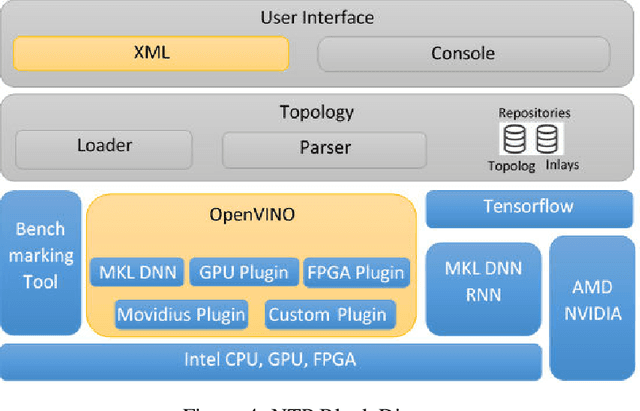
Performance of end-to-end neural networks on a given hardware platform is a function of its compute and memory signature, which in-turn, is governed by a wide range of parameters such as topology size, primitives used, framework used, batching strategy, latency requirements, precision etc. Current benchmarking tools suffer from limitations such as a) being either too granular like DeepBench [1] (or) b) mandate a working implementation that is either framework specific or hardware-architecture specific or both (or) c) provide only high level benchmark metrics. In this paper, we present NTP (Neural Net Topology Profiler), a sophisticated benchmarking framework, to effectively identify memory and compute signature of an end-to-end topology on multiple hardware architectures, without the need for an actual implementation. NTP is tightly integrated with hardware specific benchmarking tools to enable exhaustive data collection and analysis. Using NTP, a deep learning researcher can quickly establish baselines needed to understand performance of an end-to-end neural network topology and make high level architectural decisions. Further, integration of NTP with frameworks like Tensorflow, Pytorch, Intel OpenVINO etc. allows for performance comparison along several vectors like a) Comparison of different frameworks on a given hardware b) Comparison of different hardware using a given framework c) Comparison across different heterogeneous hardware configurations for given framework etc. These capabilities empower a researcher to effortlessly make architectural decisions needed for achieving optimized performance on any hardware platform. The paper documents the architectural approach of NTP and demonstrates the capabilities of the tool by benchmarking Mozilla DeepSpeech, a popular Speech Recognition topology.