 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Large Language Models for Training-free Video Anomaly Detection
Apr 01, 2024


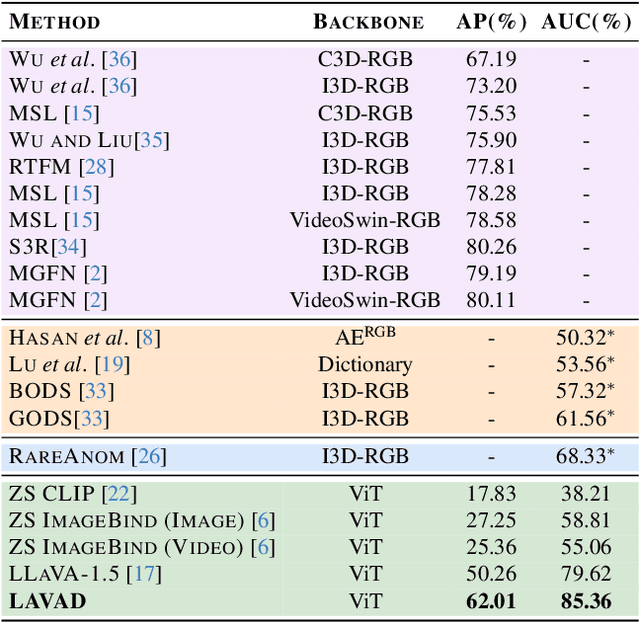
Video anomaly detection (VAD) aims to temporally locate abnormal events in a video. Existing works mostly rely on training deep models to learn the distribution of normality with either video-level supervision, one-class supervision, or in an unsupervised setting. Training-based methods are prone to be domain-specific, thus being costly for practical deployment as any domain change will involve data collection and model training. In this paper, we radically depart from previous efforts and propose LAnguage-based VAD (LAVAD), a method tackling VAD in a novel, training-free paradigm, exploiting the capabilities of pre-trained large language models (LLMs) and existing vision-language models (VLMs). We leverage VLM-based captioning models to generate textual descriptions for each frame of any test video. With the textual scene description, we then devise a prompting mechanism to unlock the capability of LLMs in terms of temporal aggregation and anomaly score estimation, turning LLMs into an effective video anomaly detector. We further leverage modality-aligned VLMs and propose effective techniques based on cross-modal similarity for cleaning noisy captions and refining the LLM-based anomaly scores. We evaluate LAVAD on two large datasets featuring real-world surveillance scenarios (UCF-Crime and XD-Violence), showing that it outperforms both unsupervised and one-class methods without requiring any training or data collection.
Delving into CLIP latent space for Video Anomaly Recognition
Oct 04, 2023



We tackle the complex problem of detecting and recognising anomalies in surveillance videos at the frame level, utilising only video-level supervision. We introduce the novel method AnomalyCLIP, the first to combine Large Language and Vision (LLV) models, such as CLIP, with multiple instance learning for joint video anomaly detection and classification. Our approach specifically involves manipulating the latent CLIP feature space to identify the normal event subspace, which in turn allows us to effectively learn text-driven directions for abnormal events. When anomalous frames are projected onto these directions, they exhibit a large feature magnitude if they belong to a particular class. We also introduce a computationally efficient Transformer architecture to model short- and long-term temporal dependencies between frames, ultimately producing the final anomaly score and class prediction probabilities. We compare AnomalyCLIP against state-of-the-art methods considering three major anomaly detection benchmarks, i.e. ShanghaiTech, UCF-Crime, and XD-Violence, and empirically show that it outperforms baselines in recognising video anomalies.
Audio-Visual Dataset and Method for Anomaly Detection in Traffic Videos
May 24, 2023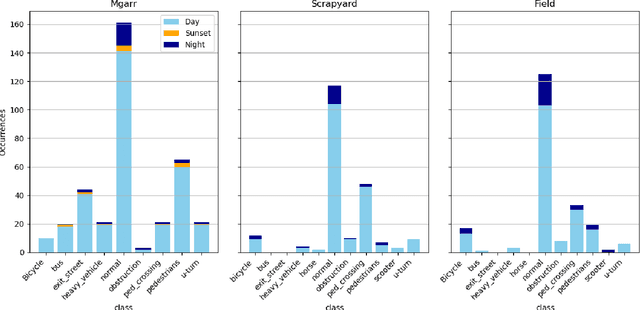
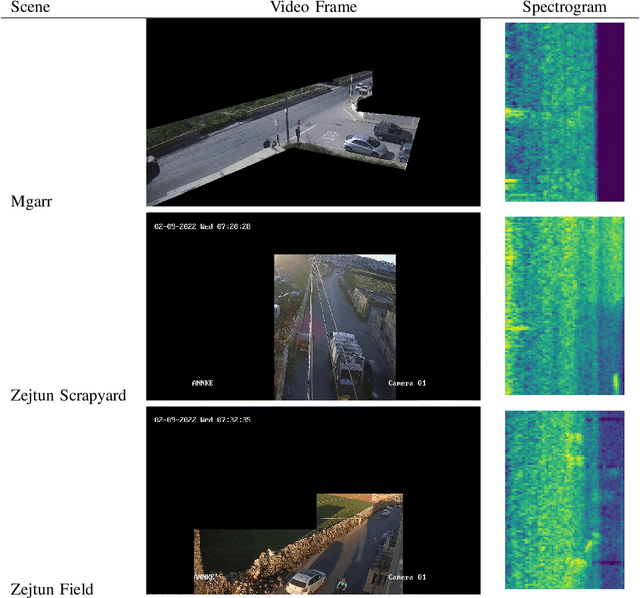

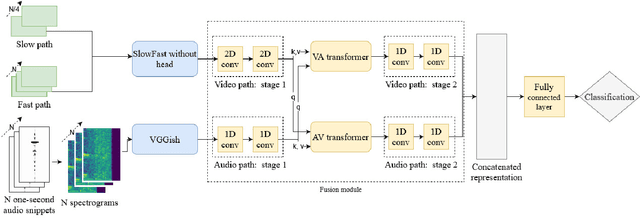
We introduce the first audio-visual dataset for traffic anomaly detection taken from real-world scenes, called MAVAD, with a diverse range of weather and illumination conditions. In addition, we propose a novel method named AVACA that combines visual and audio features extracted from video sequences by means of cross-attention to detect anomalies. We demonstrate that the addition of audio improves the performance of AVACA by up to 5.2%. We also evaluate the impact of image anonymization, showing only a minor decrease in performance averaging at 1.7%.
Graph-based Generative Face Anonymisation with Pose Preservation
Dec 10, 2021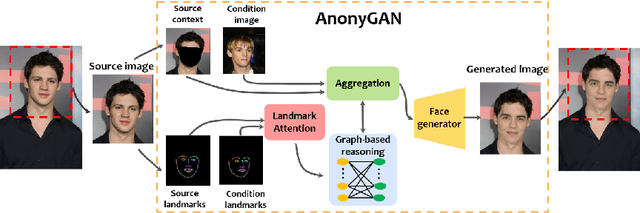
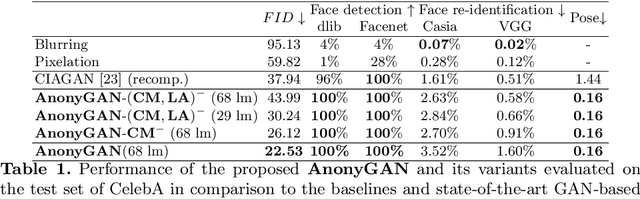
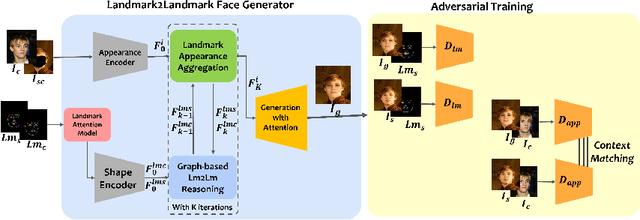
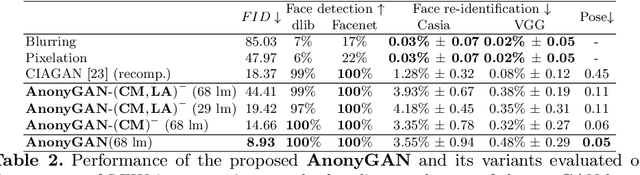
We propose AnonyGAN, a GAN-based solution for face anonymisation which replaces the visual information corresponding to a source identity with a condition identity provided as any single image. With the goal to maintain the geometric attributes of the source face, i.e., the facial pose and expression, and to promote more natural face generation, we propose to exploit a Bipartite Graph to explicitly model the relations between the facial landmarks of the source identity and the ones of the condition identity through a deep model. We further propose a landmark attention model to relax the manual selection of facial landmarks, allowing the network to weight the landmarks for the best visual naturalness and pose preservation. Finally, to facilitate the appearance learning, we propose a hybrid training strategy to address the challenge caused by the lack of direct pixel-level supervision. We evaluate our method and its variants on two public datasets, CelebA and LFW, in terms of visual naturalness, facial pose preservation and of its impacts on face detection and re-identification. We prove that AnonyGAN significantly outperforms the state-of-the-art methods in terms of visual naturalness, face detection and pose preservation.