 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRhoban Football Club: RoboCup Humanoid KidSize 2019 Champion Team Paper
Oct 25, 2019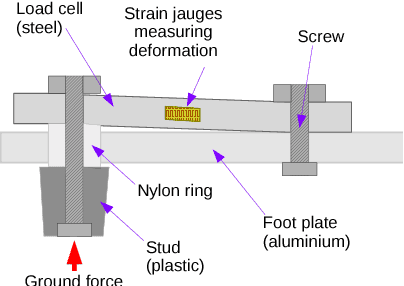


In 2019, Rhoban Football Club reached the first place of the KidSize soccer competition for the fourth time and performed the first in-game throw-in in the history of the Humanoid league. Building on our existing code-base, we improved some specific functionalities, introduced new behaviors and experimented with original methods for labeling videos. This paper presents and reviews our latest changes to both software and hardware, highlighting the lessons learned during RoboCup.
Depth-Based Visual Servoing Using Low-Accurate Arm
Dec 12, 2016



This paper proposes a visual-servoing method dedicated to grasping of daily-life objects. In order to obtain an affordable solution, we use a low-accurate robotic arm. Our method corrects errors by using an RGB-D sensor. It is based on SURF invariant features which allows us to perform object recognition at a high frame rate. We define regions of interest based on depth segmentation, and we use them to speed-up the recognition and to improve reliability. The system has been tested on a real-world scenario. In spite of the lack of accuracy of all the components and the uncontrolled environment, it grasps objects successfully on more than 95 percents of the trials.
Online Reinforcement Learning for Real-Time Exploration in Continuous State and Action Markov Decision Processes
Dec 12, 2016



This paper presents a new method to learn online policies in continuous state, continuous action, model-free Markov decision processes, with two properties that are crucial for practical applications. First, the policies are implementable with a very low computational cost: once the policy is computed, the action corresponding to a given state is obtained in logarithmic time with respect to the number of samples used. Second, our method is versatile: it does not rely on any a priori knowledge of the structure of optimal policies. We build upon the Fitted Q-iteration algorithm which represents the $Q$-value as the average of several regression trees. Our algorithm, the Fitted Policy Forest algorithm (FPF), computes a regression forest representing the Q-value and transforms it into a single tree representing the policy, while keeping control on the size of the policy using resampling and leaf merging. We introduce an adaptation of Multi-Resolution Exploration (MRE) which is particularly suited to FPF. We assess the performance of FPF on three classical benchmarks for reinforcement learning: the "Inverted Pendulum", the "Double Integrator" and "Car on the Hill" and show that FPF equals or outperforms other algorithms, although these algorithms rely on the use of particular representations of the policies, especially chosen in order to fit each of the three problems. Finally, we exhibit that the combination of FPF and MRE allows to find nearly optimal solutions in problems where $\epsilon$-greedy approaches would fail.