 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Disease Progression Models That Capture Health Disparities
Dec 20, 2024
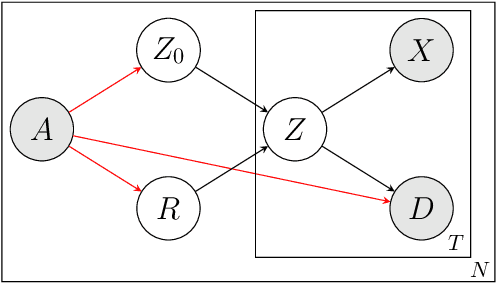
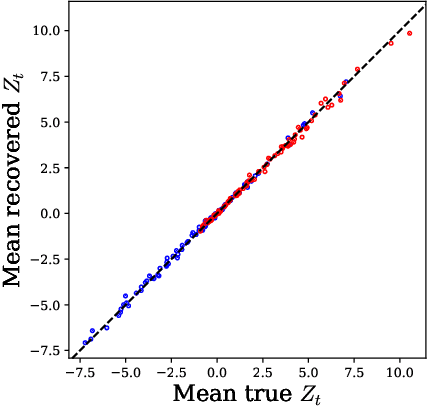
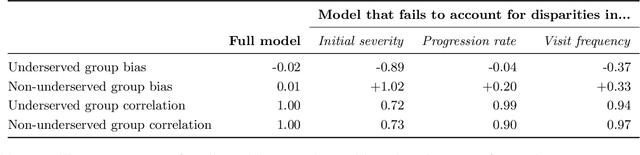
Disease progression models are widely used to inform the diagnosis and treatment of many progressive diseases. However, a significant limitation of existing models is that they do not account for health disparities that can bias the observed data. To address this, we develop an interpretable Bayesian disease progression model that captures three key health disparities: certain patient populations may (1) start receiving care only when their disease is more severe, (2) experience faster disease progression even while receiving care, or (3) receive follow-up care less frequently conditional on disease severity. We show theoretically and empirically that failing to account for disparities produces biased estimates of severity (underestimating severity for disadvantaged groups, for example). On a dataset of heart failure patients, we show that our model can identify groups that face each type of health disparity, and that accounting for these disparities meaningfully shifts which patients are considered high-risk.
Towards Sparse Federated Analytics: Location Heatmaps under Distributed Differential Privacy with Secure Aggregation
Nov 03, 2021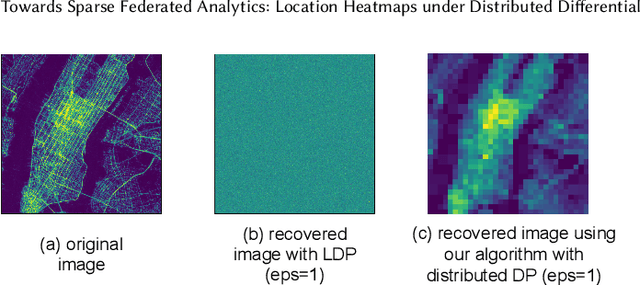
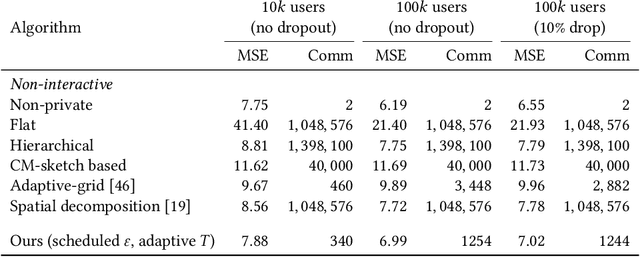
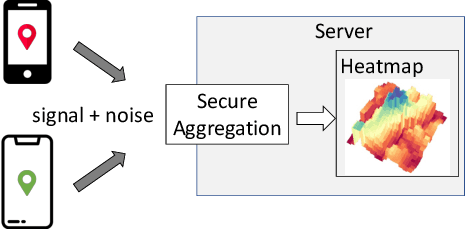

We design a scalable algorithm to privately generate location heatmaps over decentralized data from millions of user devices. It aims to ensure differential privacy before data becomes visible to a service provider while maintaining high data accuracy and minimizing resource consumption on users' devices. To achieve this, we revisit the distributed differential privacy concept based on recent results in the secure multiparty computation field and design a scalable and adaptive distributed differential privacy approach for location analytics. Evaluation on public location datasets shows that this approach successfully generates metropolitan-scale heatmaps from millions of user samples with a worst-case client communication overhead that is significantly smaller than existing state-of-the-art private protocols of similar accuracy.
Decentralized Policy-Based Private Analytics
Mar 14, 2020

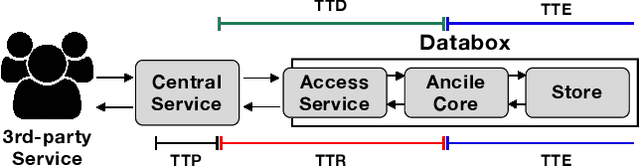
We are increasingly surrounded by applications, connected devices, services, and smart environments which require fine-grained access to various personal data. The inherent complexities of our personal and professional policies and preferences in interactions with these analytics services raise important challenges in privacy. Moreover, due to sensitivity of the data and regulatory and technical barriers, it is not always feasible to do these policy negotiations in a centralized manner. In this paper we present PoliBox, a decentralized, edge-based framework for policy-based personal data analytics. PoliBox brings together a number of existing established components to provide privacy-preserving analytics within a distributed setting. We evaluate our framework using a popular exemplar of private analytics, Federated Learning, and demonstrate that for varying model sizes and use cases, PoliBox is able to perform accurate model training and inference within very reasonable resource and time budgets.
Creative Procedural-Knowledge Extraction From Web Design Tutorials
Apr 18, 2019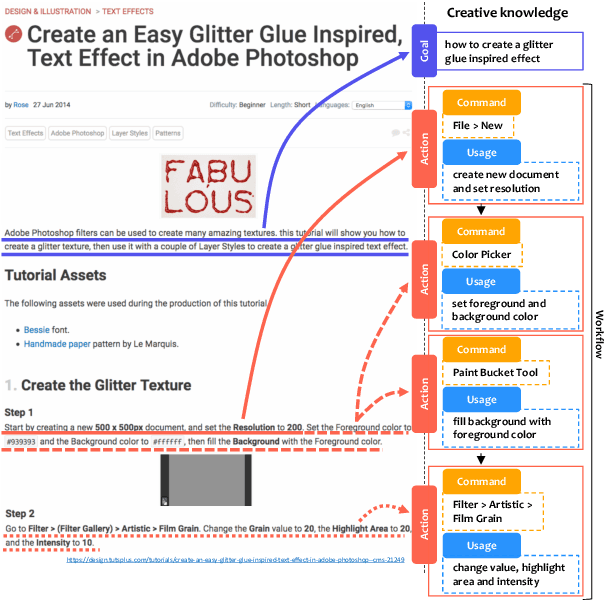

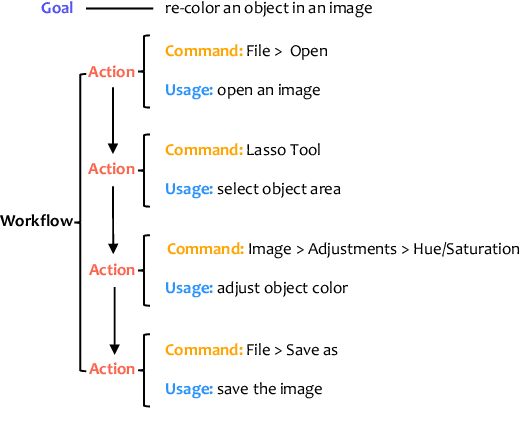
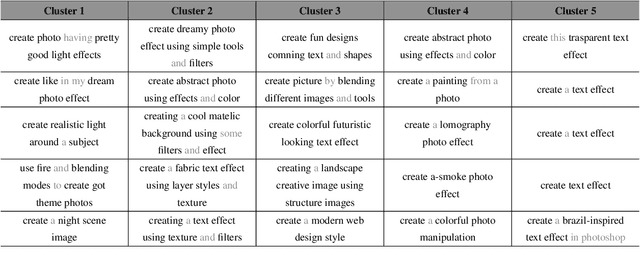
Complex design tasks often require performing diverse actions in a specific order. To (semi-)autonomously accomplish these tasks, applications need to understand and learn a wide range of design procedures, i.e., Creative Procedural-Knowledge (CPK). Prior knowledge base construction and mining have not typically addressed the creative fields, such as design and arts. In this paper, we formalize an ontology of CPK using five components: goal, workflow, action, command and usage; and extract components' values from online design tutorials. We scraped 19.6K tutorial-related webpages and built a web application for professional designers to identify and summarize CPK components. The annotated dataset consists of 819 unique commands, 47,491 actions, and 2,022 workflows and goals. Based on this dataset, we propose a general CPK extraction pipeline and demonstrate that existing text classification and sequence-to-sequence models are limited in identifying, predicting and summarizing complex operations described in heterogeneous styles. Through quantitative and qualitative error analysis, we discuss CPK extraction challenges that need to be addressed by future research.
Augmenting Gastrointestinal Health: A Deep Learning Approach to Human Stool Recognition and Characterization in Macroscopic Images
Mar 25, 2019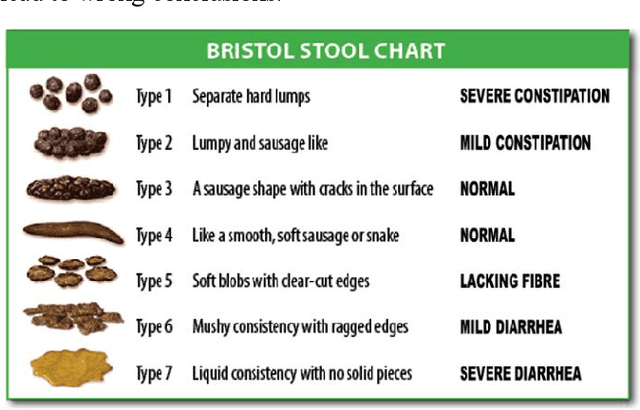


Purpose - Functional bowel diseases, including irritable bowel syndrome, chronic constipation, and chronic diarrhea, are some of the most common diseases seen in clinical practice. Many patients describe a range of triggers for altered bowel consistency and symptoms. However, characterization of the relationship between symptom triggers using bowel diaries is hampered by poor compliance and lack of objective stool consistency measurements. We sought to develop a stool detection and tracking system using computer vision and deep convolutional neural networks (CNN) that could be used by patients, providers, and researchers in the assessment of chronic gastrointestinal (GI) disease.
How To Backdoor Federated Learning
Oct 01, 2018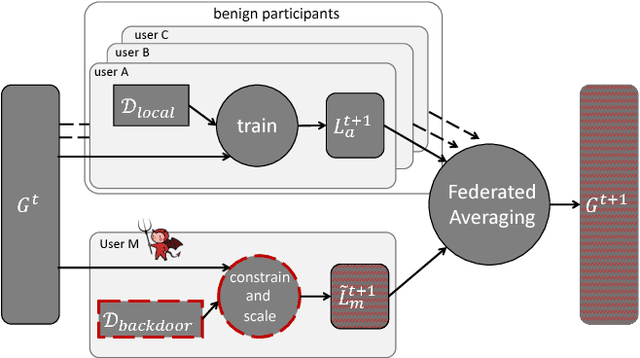
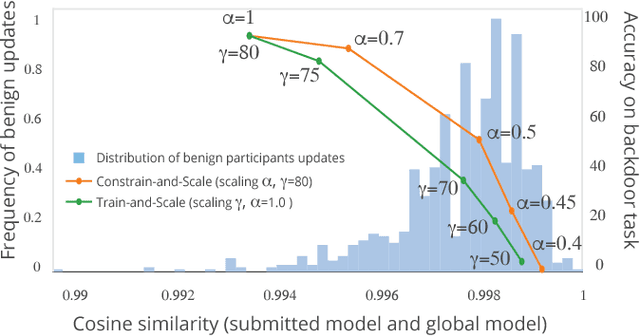
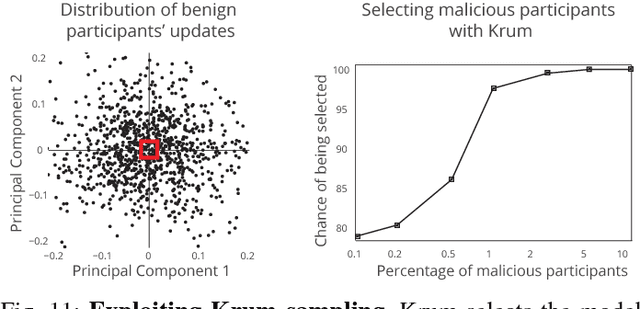
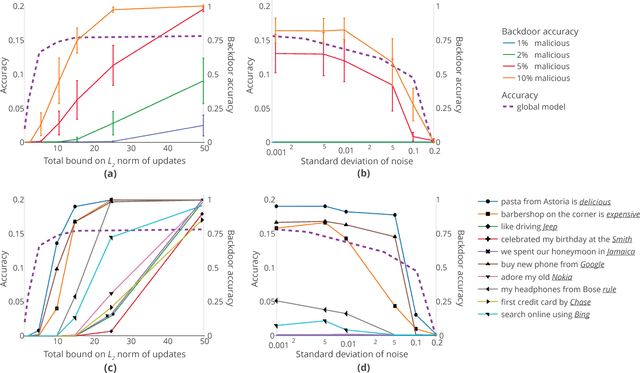
Federated learning enables thousands of participants to construct a deep learning model without sharing their private training data with each other. For example, multiple smartphones can jointly train a next-word predictor for keyboards without revealing what individual users type. We demonstrate that any participant in federated learning can introduce hidden backdoor functionality into the joint global model, e.g., to ensure that an image classifier assigns an attacker-chosen label to images with certain features, or that a word predictor completes certain sentences with an attacker-chosen word. We design and evaluate a new model-poisoning methodology based on model replacement. An attacker selected in a single round of federated learning can cause the global model to immediately reach 100% accuracy on the backdoor task. We evaluate the attack under different assumptions for the standard federated-learning tasks and show that it greatly outperforms data poisoning. Our generic constrain-and-scale technique also evades anomaly detection-based defenses by incorporating the evasion into the attacker's loss function during training.
Yum-me: A Personalized Nutrient-based Meal Recommender System
Apr 30, 2017
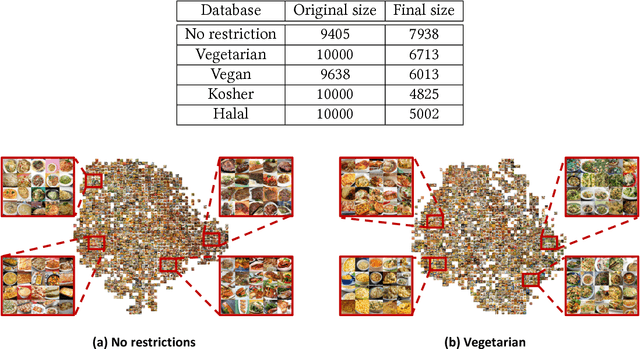
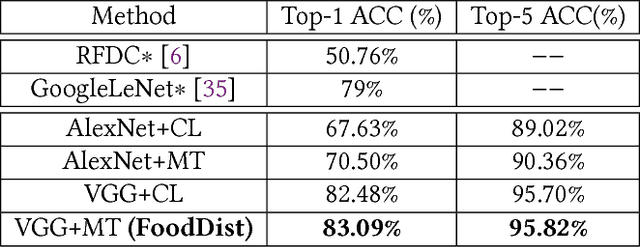
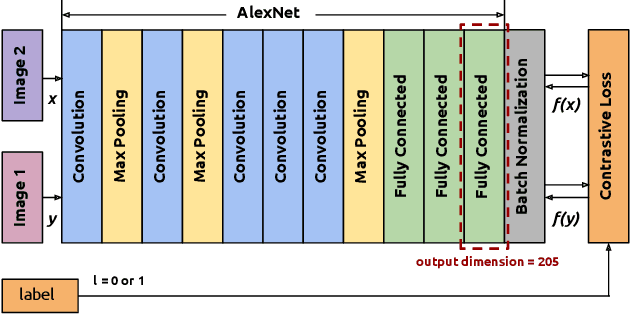
Nutrient-based meal recommendations have the potential to help individuals prevent or manage conditions such as diabetes and obesity. However, learning people's food preferences and making recommendations that simultaneously appeal to their palate and satisfy nutritional expectations are challenging. Existing approaches either only learn high-level preferences or require a prolonged learning period. We propose Yum-me, a personalized nutrient-based meal recommender system designed to meet individuals' nutritional expectations, dietary restrictions, and fine-grained food preferences. Yum-me enables a simple and accurate food preference profiling procedure via a visual quiz-based user interface, and projects the learned profile into the domain of nutritionally appropriate food options to find ones that will appeal to the user. We present the design and implementation of Yum-me, and further describe and evaluate two innovative contributions. The first contriution is an open source state-of-the-art food image analysis model, named FoodDist. We demonstrate FoodDist's superior performance through careful benchmarking and discuss its applicability across a wide array of dietary applications. The second contribution is a novel online learning framework that learns food preference from item-wise and pairwise image comparisons. We evaluate the framework in a field study of 227 anonymous users and demonstrate that it outperforms other baselines by a significant margin. We further conducted an end-to-end validation of the feasibility and effectiveness of Yum-me through a 60-person user study, in which Yum-me improves the recommendation acceptance rate by 42.63%.
Beyond Classification: Latent User Interests Profiling from Visual Contents Analysis
Dec 21, 2015


User preference profiling is an important task in modern online social networks (OSN). With the proliferation of image-centric social platforms, such as Pinterest, visual contents have become one of the most informative data streams for understanding user preferences. Traditional approaches usually treat visual content analysis as a general classification problem where one or more labels are assigned to each image. Although such an approach simplifies the process of image analysis, it misses the rich context and visual cues that play an important role in people's perception of images. In this paper, we explore the possibilities of learning a user's latent visual preferences directly from image contents. We propose a distance metric learning method based on Deep Convolutional Neural Networks (CNN) to directly extract similarity information from visual contents and use the derived distance metric to mine individual users' fine-grained visual preferences. Through our preliminary experiments using data from 5,790 Pinterest users, we show that even for the images within the same category, each user possesses distinct and individually-identifiable visual preferences that are consistent over their lifetime. Our results underscore the untapped potential of finer-grained visual preference profiling in understanding users' preferences.