 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Reasoning in Ambiguous Contexts
Jun 13, 2025We study the ability of language models to reason about appropriate information disclosure - a central aspect of the evolving field of agentic privacy. Whereas previous works have focused on evaluating a model's ability to align with human decisions, we examine the role of ambiguity and missing context on model performance when making information-sharing decisions. We identify context ambiguity as a crucial barrier for high performance in privacy assessments. By designing Camber, a framework for context disambiguation, we show that model-generated decision rationales can reveal ambiguities and that systematically disambiguating context based on these rationales leads to significant accuracy improvements (up to 13.3\% in precision and up to 22.3\% in recall) as well as reductions in prompt sensitivity. Overall, our results indicate that approaches for context disambiguation are a promising way forward to enhance agentic privacy reasoning.
Air Gap: Protecting Privacy-Conscious Conversational Agents
May 08, 2024



The growing use of large language model (LLM)-based conversational agents to manage sensitive user data raises significant privacy concerns. While these agents excel at understanding and acting on context, this capability can be exploited by malicious actors. We introduce a novel threat model where adversarial third-party apps manipulate the context of interaction to trick LLM-based agents into revealing private information not relevant to the task at hand. Grounded in the framework of contextual integrity, we introduce AirGapAgent, a privacy-conscious agent designed to prevent unintended data leakage by restricting the agent's access to only the data necessary for a specific task. Extensive experiments using Gemini, GPT, and Mistral models as agents validate our approach's effectiveness in mitigating this form of context hijacking while maintaining core agent functionality. For example, we show that a single-query context hijacking attack on a Gemini Ultra agent reduces its ability to protect user data from 94% to 45%, while an AirGapAgent achieves 97% protection, rendering the same attack ineffective.
Confidential Federated Computations
Apr 16, 2024Federated Learning and Analytics (FLA) have seen widespread adoption by technology platforms for processing sensitive on-device data. However, basic FLA systems have privacy limitations: they do not necessarily require anonymization mechanisms like differential privacy (DP), and provide limited protections against a potentially malicious service provider. Adding DP to a basic FLA system currently requires either adding excessive noise to each device's updates, or assuming an honest service provider that correctly implements the mechanism and only uses the privatized outputs. Secure multiparty computation (SMPC) -based oblivious aggregations can limit the service provider's access to individual user updates and improve DP tradeoffs, but the tradeoffs are still suboptimal, and they suffer from scalability challenges and susceptibility to Sybil attacks. This paper introduces a novel system architecture that leverages trusted execution environments (TEEs) and open-sourcing to both ensure confidentiality of server-side computations and provide externally verifiable privacy properties, bolstering the robustness and trustworthiness of private federated computations.
ViFiT: Reconstructing Vision Trajectories from IMU and Wi-Fi Fine Time Measurements
Oct 04, 2023Tracking subjects in videos is one of the most widely used functions in camera-based IoT applications such as security surveillance, smart city traffic safety enhancement, vehicle to pedestrian communication and so on. In the computer vision domain, tracking is usually achieved by first detecting subjects with bounding boxes, then associating detected bounding boxes across video frames. For many IoT systems, images captured by cameras are usually sent over the network to be processed at a different site that has more powerful computing resources than edge devices. However, sending entire frames through the network causes significant bandwidth consumption that may exceed the system bandwidth constraints. To tackle this problem, we propose ViFiT, a transformer-based model that reconstructs vision bounding box trajectories from phone data (IMU and Fine Time Measurements). It leverages a transformer ability of better modeling long-term time series data. ViFiT is evaluated on Vi-Fi Dataset, a large-scale multimodal dataset in 5 diverse real world scenes, including indoor and outdoor environments. To fill the gap of proper metrics of jointly capturing the system characteristics of both tracking quality and video bandwidth reduction, we propose a novel evaluation framework dubbed Minimum Required Frames (MRF) and Minimum Required Frames Ratio (MRFR). ViFiT achieves an MRFR of 0.65 that outperforms the state-of-the-art approach for cross-modal reconstruction in LSTM Encoder-Decoder architecture X-Translator of 0.98, resulting in a high frame reduction rate as 97.76%.
ViFi-Loc: Multi-modal Pedestrian Localization using GAN with Camera-Phone Correspondences
Nov 22, 2022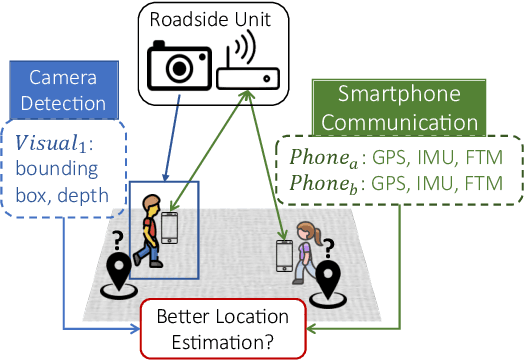
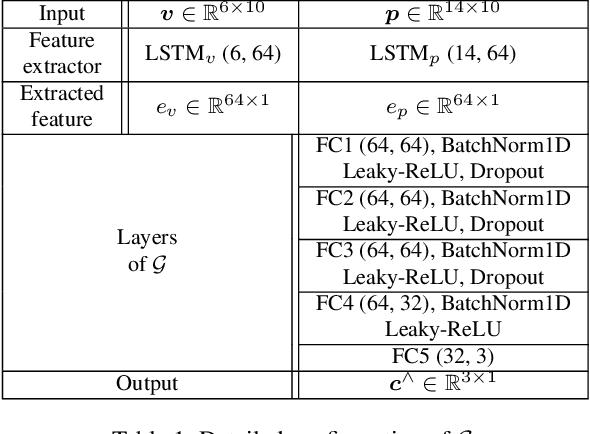
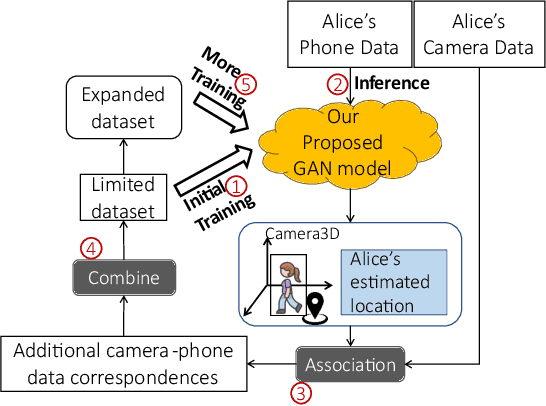

In Smart City and Vehicle-to-Everything (V2X) systems, acquiring pedestrians' accurate locations is crucial to traffic safety. Current systems adopt cameras and wireless sensors to detect and estimate people's locations via sensor fusion. Standard fusion algorithms, however, become inapplicable when multi-modal data is not associated. For example, pedestrians are out of the camera field of view, or data from camera modality is missing. To address this challenge and produce more accurate location estimations for pedestrians, we propose a Generative Adversarial Network (GAN) architecture. During training, it learns the underlying linkage between pedestrians' camera-phone data correspondences. During inference, it generates refined position estimations based only on pedestrians' phone data that consists of GPS, IMU and FTM. Results show that our GAN produces 3D coordinates at 1 to 2 meter localization error across 5 different outdoor scenes. We further show that the proposed model supports self-learning. The generated coordinates can be associated with pedestrian's bounding box coordinates to obtain additional camera-phone data correspondences. This allows automatic data collection during inference. After fine-tuning on the expanded dataset, localization accuracy is improved by up to 26%.
ViFiCon: Vision and Wireless Association Via Self-Supervised Contrastive Learning
Oct 11, 2022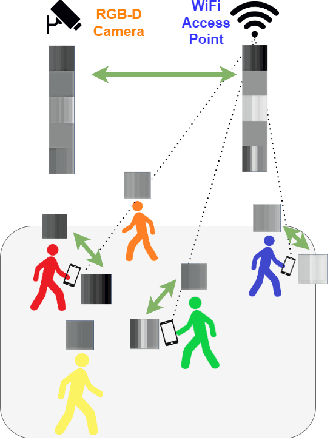

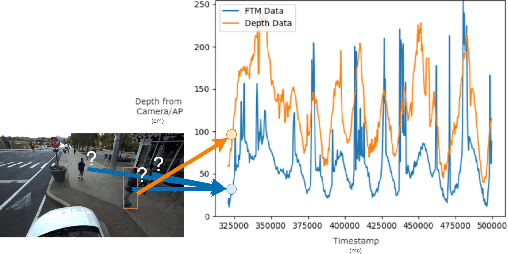

We introduce ViFiCon, a self-supervised contrastive learning scheme which uses synchronized information across vision and wireless modalities to perform cross-modal association. Specifically, the system uses pedestrian data collected from RGB-D camera footage as well as WiFi Fine Time Measurements (FTM) from a user's smartphone device. We represent the temporal sequence by stacking multi-person depth data spatially within a banded image. Depth data from RGB-D (vision domain) is inherently linked with an observable pedestrian, but FTM data (wireless domain) is associated only to a smartphone on the network. To formulate the cross-modal association problem as self-supervised, the network learns a scene-wide synchronization of the two modalities as a pretext task, and then uses that learned representation for the downstream task of associating individual bounding boxes to specific smartphones, i.e. associating vision and wireless information. We use a pre-trained region proposal model on the camera footage and then feed the extrapolated bounding box information into a dual-branch convolutional neural network along with the FTM data. We show that compared to fully supervised SoTA models, ViFiCon achieves high performance vision-to-wireless association, finding which bounding box corresponds to which smartphone device, without hand-labeled association examples for training data.
Histogram Estimation under User-level Privacy with Heterogeneous Data
Jun 07, 2022

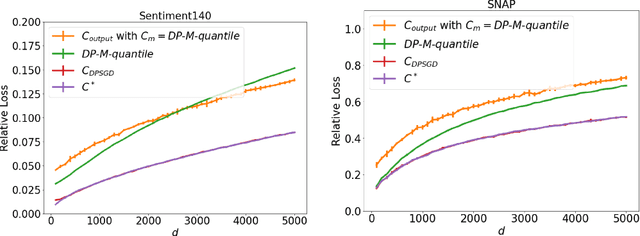
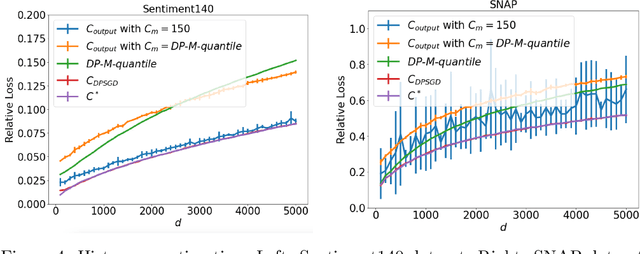
We study the problem of histogram estimation under user-level differential privacy, where the goal is to preserve the privacy of all entries of any single user. While there is abundant literature on this classical problem under the item-level privacy setup where each user contributes only one data point, little has been known for the user-level counterpart. We consider the heterogeneous scenario where both the quantity and distribution of data can be different for each user. We propose an algorithm based on a clipping strategy that almost achieves a two-approximation with respect to the best clipping threshold in hindsight. This result holds without any distribution assumptions on the data. We also prove that the clipping bias can be significantly reduced when the counts are from non-i.i.d. Poisson distributions and show empirically that our debiasing method provides improvements even without such constraints. Experiments on both real and synthetic datasets verify our theoretical findings and demonstrate the effectiveness of our algorithms.
Towards Sparse Federated Analytics: Location Heatmaps under Distributed Differential Privacy with Secure Aggregation
Nov 03, 2021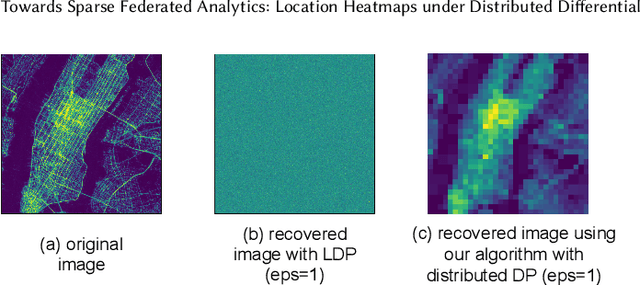
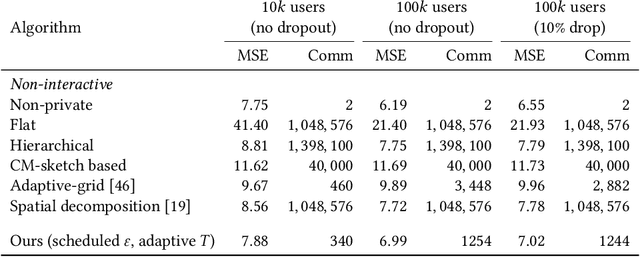
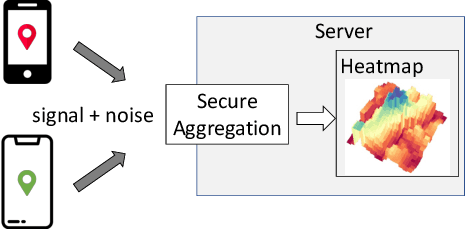

We design a scalable algorithm to privately generate location heatmaps over decentralized data from millions of user devices. It aims to ensure differential privacy before data becomes visible to a service provider while maintaining high data accuracy and minimizing resource consumption on users' devices. To achieve this, we revisit the distributed differential privacy concept based on recent results in the secure multiparty computation field and design a scalable and adaptive distributed differential privacy approach for location analytics. Evaluation on public location datasets shows that this approach successfully generates metropolitan-scale heatmaps from millions of user samples with a worst-case client communication overhead that is significantly smaller than existing state-of-the-art private protocols of similar accuracy.
LaNet: Real-time Lane Identification by Learning Road SurfaceCharacteristics from Accelerometer Data
Apr 06, 2020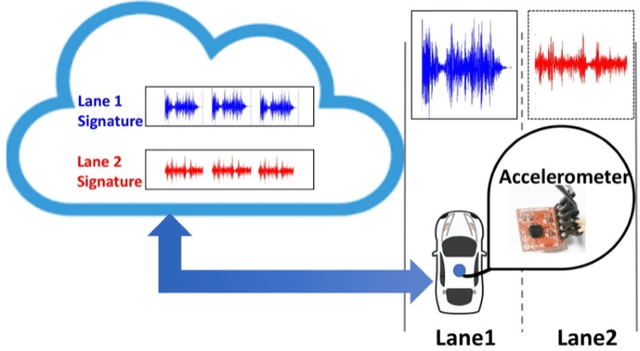
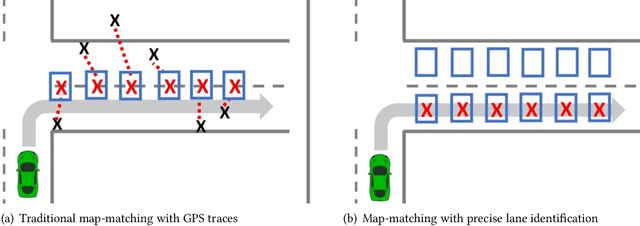
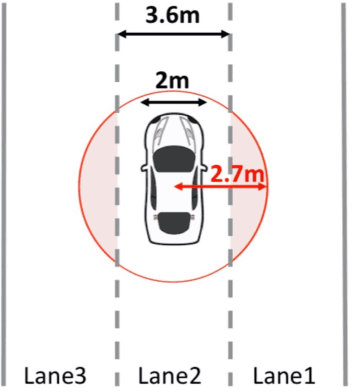
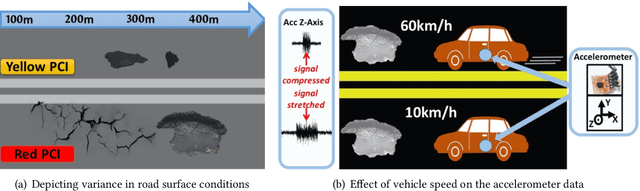
The resolution of GPS measurements, especially in urban areas, is insufficient for identifying a vehicle's lane. In this work, we develop a deep LSTM neural network model LaNet that determines the lane vehicles are on by periodically classifying accelerometer samples collected by vehicles as they drive in real time. Our key finding is that even adjacent patches of road surfaces contain characteristics that are sufficiently unique to differentiate between lanes, i.e., roads inherently exhibit differing bumps, cracks, potholes, and surface unevenness. Cars can capture this road surface information as they drive using inexpensive, easy-to-install accelerometers that increasingly come fitted in cars and can be accessed via the CAN-bus. We collect an aggregate of 60 km driving data and synthesize more based on this that capture factors such as variable driving speed, vehicle suspensions, and accelerometer noise. Our formulated LSTM-based deep learning model, LaNet, learns lane-specific sequences of road surface events (bumps, cracks etc.) and yields 100% lane classification accuracy with 200 meters of driving data, achieving over 90% with just 100 m (correspondingly to roughly one minute of driving). We design the LaNet model to be practical for use in real-time lane classification and show with extensive experiments that LaNet yields high classification accuracy even on smooth roads, on large multi-lane roads, and on drives with frequent lane changes. Since different road surfaces have different inherent characteristics or entropy, we excavate our neural network model and discover a mechanism to easily characterize the achievable classification accuracies in a road over various driving distances by training the model just once. We present LaNet as a low-cost, easily deployable and highly accurate way to achieve fine-grained lane identification.
Advances and Open Problems in Federated Learning
Dec 10, 2019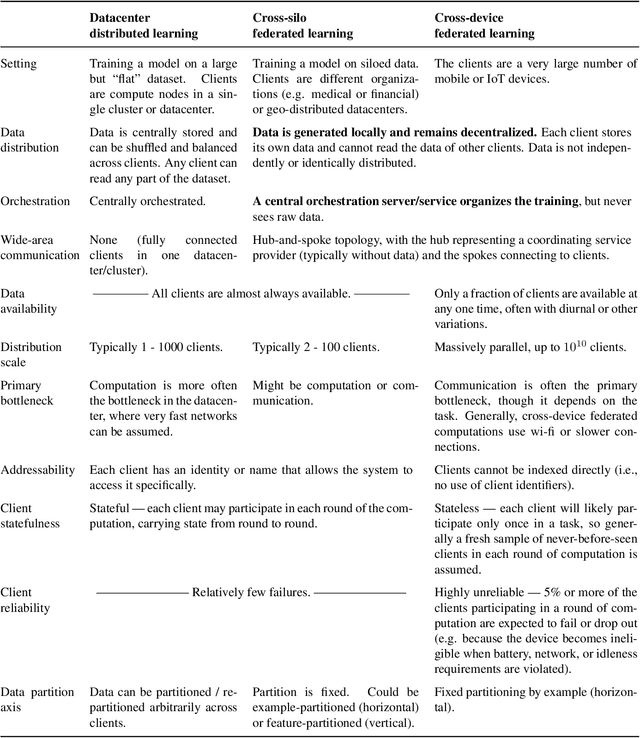
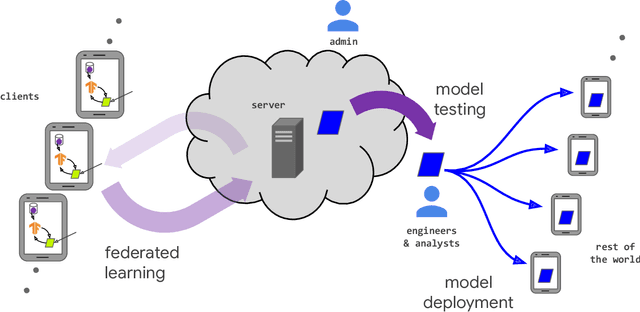
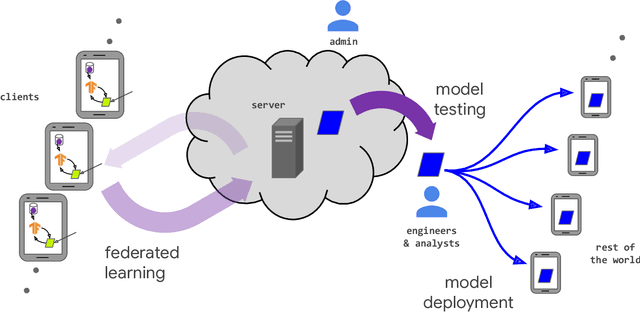

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.