 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaNet: Real-time Lane Identification by Learning Road SurfaceCharacteristics from Accelerometer Data
Apr 06, 2020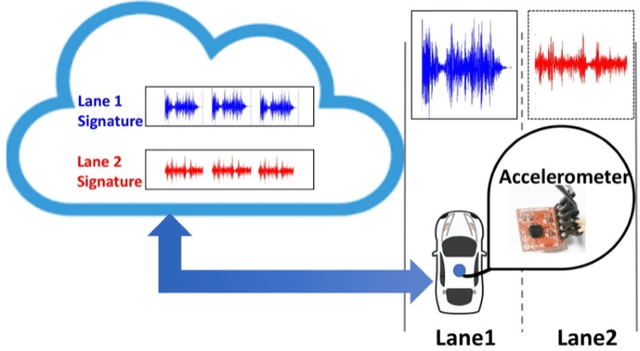
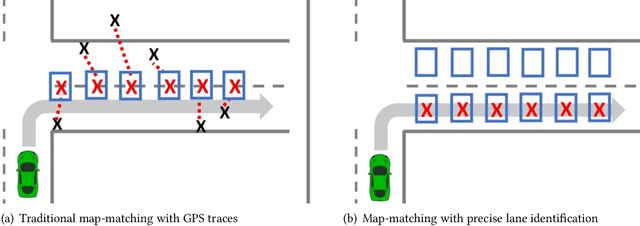
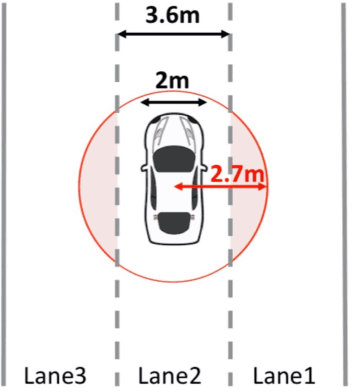
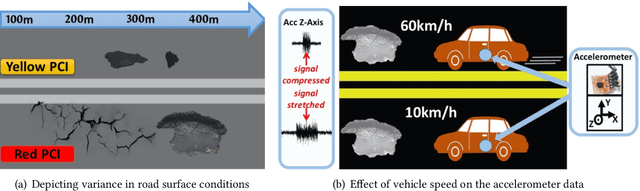
The resolution of GPS measurements, especially in urban areas, is insufficient for identifying a vehicle's lane. In this work, we develop a deep LSTM neural network model LaNet that determines the lane vehicles are on by periodically classifying accelerometer samples collected by vehicles as they drive in real time. Our key finding is that even adjacent patches of road surfaces contain characteristics that are sufficiently unique to differentiate between lanes, i.e., roads inherently exhibit differing bumps, cracks, potholes, and surface unevenness. Cars can capture this road surface information as they drive using inexpensive, easy-to-install accelerometers that increasingly come fitted in cars and can be accessed via the CAN-bus. We collect an aggregate of 60 km driving data and synthesize more based on this that capture factors such as variable driving speed, vehicle suspensions, and accelerometer noise. Our formulated LSTM-based deep learning model, LaNet, learns lane-specific sequences of road surface events (bumps, cracks etc.) and yields 100% lane classification accuracy with 200 meters of driving data, achieving over 90% with just 100 m (correspondingly to roughly one minute of driving). We design the LaNet model to be practical for use in real-time lane classification and show with extensive experiments that LaNet yields high classification accuracy even on smooth roads, on large multi-lane roads, and on drives with frequent lane changes. Since different road surfaces have different inherent characteristics or entropy, we excavate our neural network model and discover a mechanism to easily characterize the achievable classification accuracies in a road over various driving distances by training the model just once. We present LaNet as a low-cost, easily deployable and highly accurate way to achieve fine-grained lane identification.
Privacy Partitioning: Protecting User Data During the Deep Learning Inference Phase
Dec 07, 2018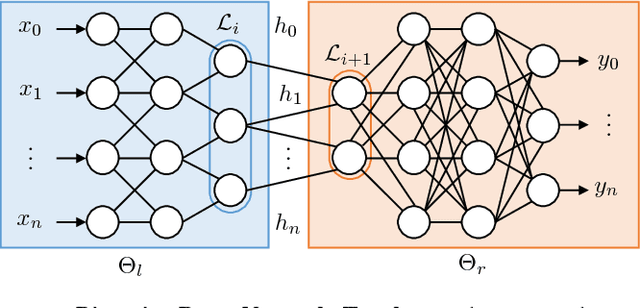
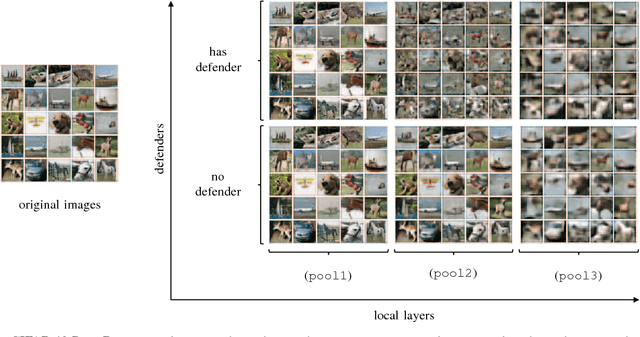
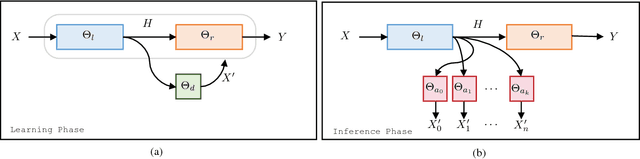

We present a practical method for protecting data during the inference phase of deep learning based on bipartite topology threat modeling and an interactive adversarial deep network construction. We term this approach \emph{Privacy Partitioning}. In the proposed framework, we split the machine learning models and deploy a few layers into users' local devices, and the rest of the layers into a remote server. We propose an approach to protect user's data during the inference phase, while still achieve good classification accuracy. We conduct an experimental evaluation of this approach on benchmark datasets of three computer vision tasks. The experimental results indicate that this approach can be used to significantly attenuate the capacity for an adversary with access to the state-of-the-art deep network's intermediate states to learn privacy-sensitive inputs to the network. For example, we demonstrate that our approach can prevent attackers from inferring the private attributes such as gender from the Face image dataset without sacrificing the classification accuracy of the original machine learning task such as Face Identification.