 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Autotuned Communication-Efficient Secure Aggregation
Paper and Code
Nov 30, 2019
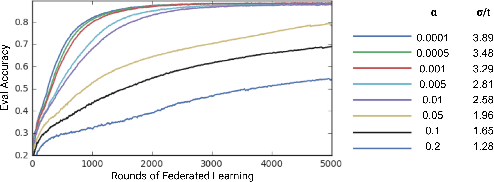
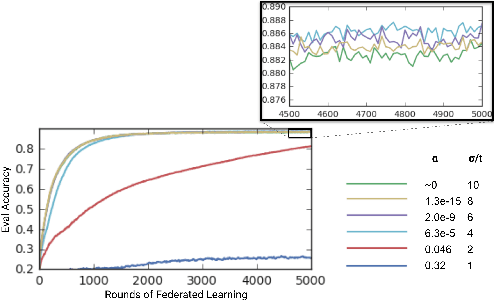
Federated Learning enables mobile devices to collaboratively learn a shared inference model while keeping all the training data on a user's device, decoupling the ability to do machine learning from the need to store the data in the cloud. Existing work on federated learning with limited communication demonstrates how random rotation can enable users' model updates to be quantized much more efficiently, reducing the communication cost between users and the server. Meanwhile, secure aggregation enables the server to learn an aggregate of at least a threshold number of device's model contributions without observing any individual device's contribution in unaggregated form. In this paper, we highlight some of the challenges of setting the parameters for secure aggregation to achieve communication efficiency, especially in the context of the aggressively quantized inputs enabled by random rotation. We then develop a recipe for auto-tuning communication-efficient secure aggregation, based on specific properties of random rotation and secure aggregation -- namely, the predictable distribution of vector entries post-rotation and the modular wrapping inherent in secure aggregation. We present both theoretical results and initial experiments.