 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModerating Model Marketplaces: Platform Governance Puzzles for AI Intermediaries
Nov 21, 2023



The AI development community is increasingly making use of hosting intermediaries such as Hugging Face provide easy access to user-uploaded models and training data. These model marketplaces lower technical deployment barriers for hundreds of thousands of users, yet can be used in numerous potentially harmful and illegal ways. In this article, we explain ways in which AI systems, which can both `contain' content and be open-ended tools, present one of the trickiest platform governance challenges seen to date. We provide case studies of several incidents across three illustrative platforms -- Hugging Face, GitHub and Civitai -- to examine how model marketplaces moderate models. Building on this analysis, we outline important (and yet nevertheless limited) practices that industry has been developing to respond to moderation demands: licensing, access and use restrictions, automated content moderation, and open policy development. While the policy challenge at hand is a considerable one, we conclude with some ideas as to how platforms could better mobilize resources to act as a careful, fair, and proportionate regulatory access point.
Understanding accountability in algorithmic supply chains
Apr 28, 2023
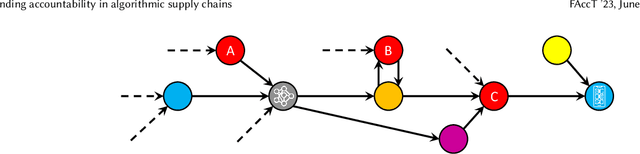
Academic and policy proposals on algorithmic accountability often seek to understand algorithmic systems in their socio-technical context, recognising that they are produced by 'many hands'. Increasingly, however, algorithmic systems are also produced, deployed, and used within a supply chain comprising multiple actors tied together by flows of data between them. In such cases, it is the working together of an algorithmic supply chain of different actors who contribute to the production, deployment, use, and functionality that drives systems and produces particular outcomes. We argue that algorithmic accountability discussions must consider supply chains and the difficult implications they raise for the governance and accountability of algorithmic systems. In doing so, we explore algorithmic supply chains, locating them in their broader technical and political economic context and identifying some key features that should be understood in future work on algorithmic governance and accountability (particularly regarding general purpose AI services). To highlight ways forward and areas warranting attention, we further discuss some implications raised by supply chains: challenges for allocating accountability stemming from distributed responsibility for systems between actors, limited visibility due to the accountability horizon, service models of use and liability, and cross-border supply chains and regulatory arbitrage
Demystifying the Draft EU Artificial Intelligence Act
Jul 20, 2021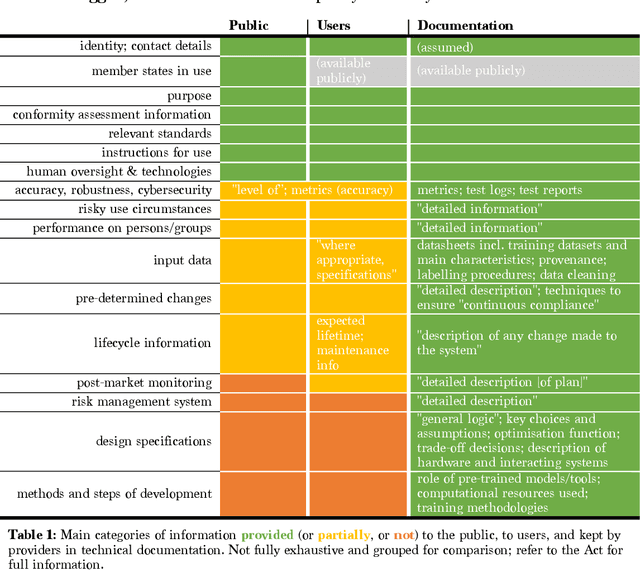
In April 2021, the European Commission proposed a Regulation on Artificial Intelligence, known as the AI Act. We present an overview of the Act and analyse its implications, drawing on scholarship ranging from the study of contemporary AI practices to the structure of EU product safety regimes over the last four decades. Aspects of the AI Act, such as different rules for different risk-levels of AI, make sense. But we also find that some provisions of the Draft AI Act have surprising legal implications, whilst others may be largely ineffective at achieving their stated goals. Several overarching aspects, including the enforcement regime and the risks of maximum harmonisation pre-empting legitimate national AI policy, engender significant concern. These issues should be addressed as a priority in the legislative process.
* 16 pages, 1 table
Logics and practices of transparency and opacity in real-world applications of public sector machine learning
Nov 05, 2018Machine learning systems are increasingly used to support public sector decision-making across a variety of sectors. Given concerns around accountability in these domains, and amidst accusations of intentional or unintentional bias, there have been increased calls for transparency of these technologies. Few, however, have considered how logics and practices concerning transparency have been understood by those involved in the machine learning systems already being piloted and deployed in public bodies today. This short paper distils insights about transparency on the ground from interviews with 27 such actors, largely public servants and relevant contractors, across 5 OECD countries. Considering transparency and opacity in relation to trust and buy-in, better decision-making, and the avoidance of gaming, it seeks to provide useful insights for those hoping to develop socio-technical approaches to transparency that might be useful to practitioners on-the-ground. An extended, archival version of this paper is available as Veale M., Van Kleek M., & Binns R. (2018). `Fairness and accountability design needs for algorithmic support in high-stakes public sector decision-making' Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems (CHI'18), http://doi.org/10.1145/3173574.3174014.
Algorithms that Remember: Model Inversion Attacks and Data Protection Law
Oct 15, 2018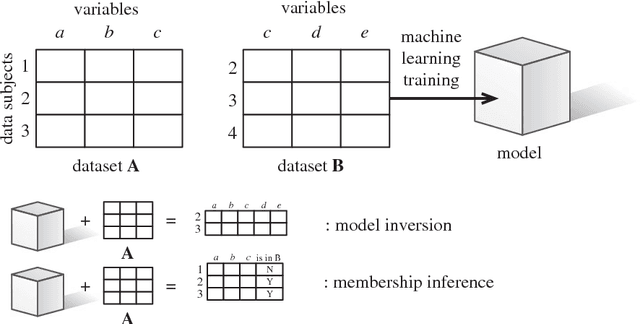
Many individuals are concerned about the governance of machine learning systems and the prevention of algorithmic harms. The EU's recent General Data Protection Regulation (GDPR) has been seen as a core tool for achieving better governance of this area. While the GDPR does apply to the use of models in some limited situations, most of its provisions relate to the governance of personal data, while models have traditionally been seen as intellectual property. We present recent work from the information security literature around `model inversion' and `membership inference' attacks, which indicate that the process of turning training data into machine learned systems is not one-way, and demonstrate how this could lead some models to be legally classified as personal data. Taking this as a probing experiment, we explore the different rights and obligations this would trigger and their utility, and posit future directions for algorithmic governance and regulation.
* 15 pages, 1 figure
Enslaving the Algorithm: From a "Right to an Explanation" to a "Right to Better Decisions"?
Jul 02, 2018As concerns about unfairness and discrimination in "black box" machine learning systems rise, a legal "right to an explanation" has emerged as a compellingly attractive approach for challenge and redress. We outline recent debates on the limited provisions in European data protection law, and introduce and analyze newer explanation rights in French administrative law and the draft modernized Council of Europe Convention 108. While individual rights can be useful, in privacy law they have historically unreasonably burdened the average data subject. "Meaningful information" about algorithmic logics is more technically possible than commonly thought, but this exacerbates a new "transparency fallacy"---an illusion of remedy rather than anything substantively helpful. While rights-based approaches deserve a firm place in the toolbox, other forms of governance, such as impact assessments, "soft law," judicial review, and model repositories deserve more attention, alongside catalyzing agencies acting for users to control algorithmic system design.
* 14 pages, 0 figures
Blind Justice: Fairness with Encrypted Sensitive Attributes
Jun 08, 2018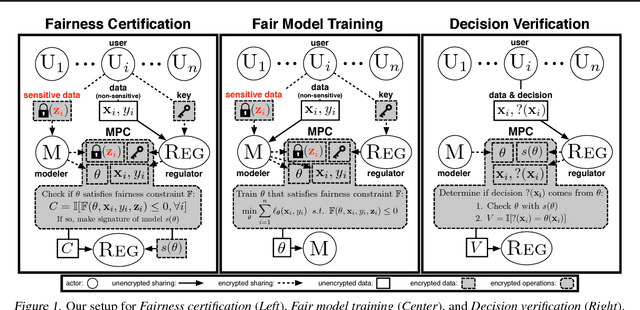
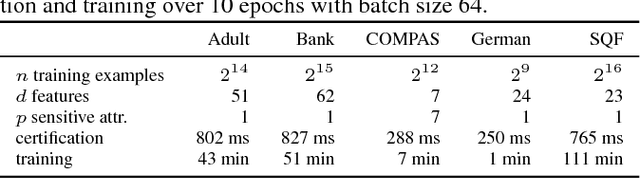
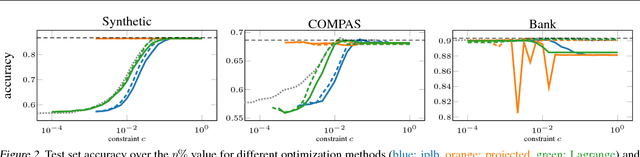
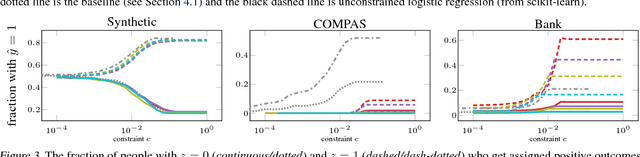
Recent work has explored how to train machine learning models which do not discriminate against any subgroup of the population as determined by sensitive attributes such as gender or race. To avoid disparate treatment, sensitive attributes should not be considered. On the other hand, in order to avoid disparate impact, sensitive attributes must be examined, e.g., in order to learn a fair model, or to check if a given model is fair. We introduce methods from secure multi-party computation which allow us to avoid both. By encrypting sensitive attributes, we show how an outcome-based fair model may be learned, checked, or have its outputs verified and held to account, without users revealing their sensitive attributes.
* published at ICML 2018
Some HCI Priorities for GDPR-Compliant Machine Learning
Mar 16, 2018In this short paper, we consider the roles of HCI in enabling the better governance of consequential machine learning systems using the rights and obligations laid out in the recent 2016 EU General Data Protection Regulation (GDPR)---a law which involves heavy interaction with people and systems. Focussing on those areas that relate to algorithmic systems in society, we propose roles for HCI in legal contexts in relation to fairness, bias and discrimination; data protection by design; data protection impact assessments; transparency and explanations; the mitigation and understanding of automation bias; and the communication of envisaged consequences of processing.
Fairness and Accountability Design Needs for Algorithmic Support in High-Stakes Public Sector Decision-Making
Feb 03, 2018Calls for heightened consideration of fairness and accountability in algorithmically-informed public decisions---like taxation, justice, and child protection---are now commonplace. How might designers support such human values? We interviewed 27 public sector machine learning practitioners across 5 OECD countries regarding challenges understanding and imbuing public values into their work. The results suggest a disconnect between organisational and institutional realities, constraints and needs, and those addressed by current research into usable, transparent and 'discrimination-aware' machine learning---absences likely to undermine practical initiatives unless addressed. We see design opportunities in this disconnect, such as in supporting the tracking of concept drift in secondary data sources, and in building usable transparency tools to identify risks and incorporate domain knowledge, aimed both at managers and at the 'street-level bureaucrats' on the frontlines of public service. We conclude by outlining ethical challenges and future directions for collaboration in these high-stakes applications.
* 14 pages, 0 figures, ACM Conference on Human Factors in Computing Systems (CHI'18), April 21--26, Montreal, Canada
Like trainer, like bot? Inheritance of bias in algorithmic content moderation
Jul 05, 2017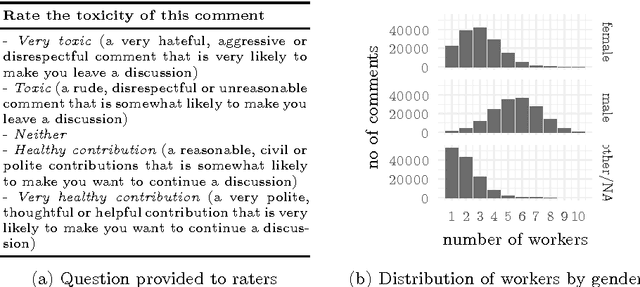
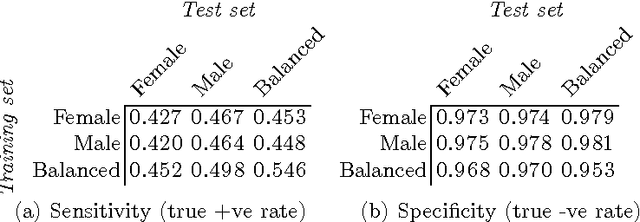
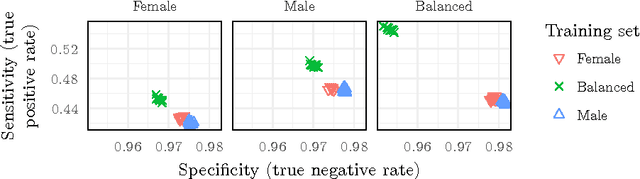
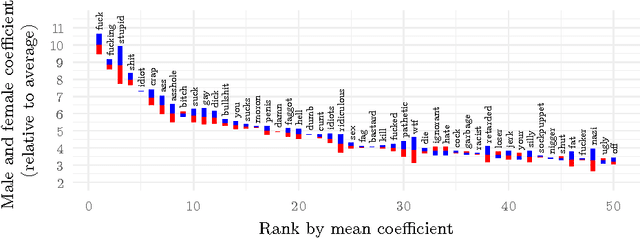
The internet has become a central medium through which `networked publics' express their opinions and engage in debate. Offensive comments and personal attacks can inhibit participation in these spaces. Automated content moderation aims to overcome this problem using machine learning classifiers trained on large corpora of texts manually annotated for offence. While such systems could help encourage more civil debate, they must navigate inherently normatively contestable boundaries, and are subject to the idiosyncratic norms of the human raters who provide the training data. An important objective for platforms implementing such measures might be to ensure that they are not unduly biased towards or against particular norms of offence. This paper provides some exploratory methods by which the normative biases of algorithmic content moderation systems can be measured, by way of a case study using an existing dataset of comments labelled for offence. We train classifiers on comments labelled by different demographic subsets (men and women) to understand how differences in conceptions of offence between these groups might affect the performance of the resulting models on various test sets. We conclude by discussing some of the ethical choices facing the implementers of algorithmic moderation systems, given various desired levels of diversity of viewpoints amongst discussion participants.