 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
What does it mean to solve the problem of discrimination in hiring? Social, technical and legal perspectives from the UK on automated hiring systems
Sep 28, 2019
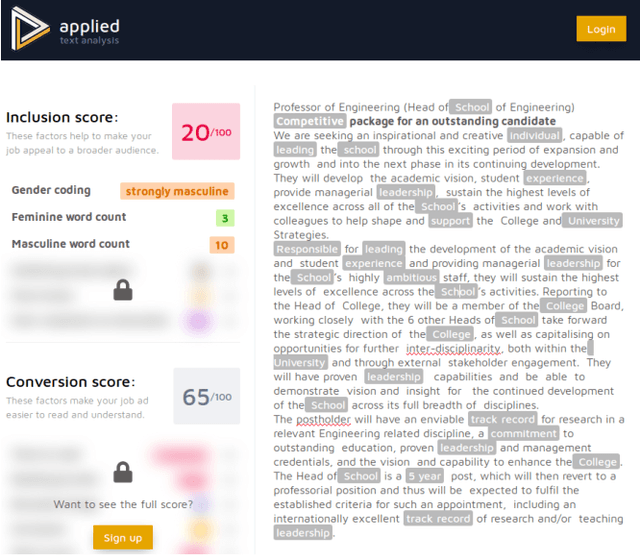
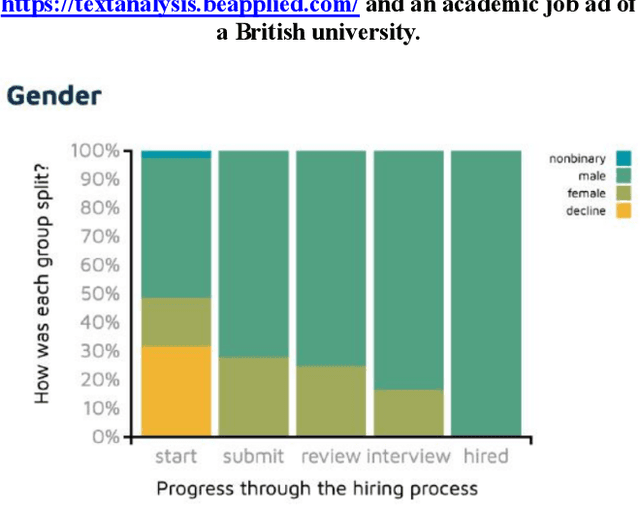
The ability to get and keep a job is a key aspect of participating in society and sustaining livelihoods. Yet the way decisions are made on who is eligible for jobs, and why, are rapidly changing with the advent and growth in uptake of automated hiring systems (AHSs) powered by data-driven tools. Key concerns about such AHSs include the lack of transparency and potential limitation of access to jobs for specific profiles. In relation to the latter, however, several of these AHSs claim to detect and mitigate discriminatory practices against protected groups and promote diversity and inclusion at work. Yet whilst these tools have a growing user-base around the world, such claims of bias mitigation are rarely scrutinised and evaluated, and when done so, have almost exclusively been from a US socio-legal perspective. In this paper, we introduce a perspective outside the US by critically examining how three prominent automated hiring systems (AHSs) in regular use in the UK, HireVue, Pymetrics and Applied, understand and attempt to mitigate bias and discrimination. Using publicly available documents, we describe how their tools are designed, validated and audited for bias, highlighting assumptions and limitations, before situating these in the socio-legal context of the UK. The UK has a very different legal background to the US in terms not only of hiring and equality law, but also in terms of data protection (DP) law. We argue that this might be important for addressing concerns about transparency and could mean a challenge to building bias mitigation into AHSs definitively capable of meeting EU legal standards. This is significant as these AHSs, especially those developed in the US, may obscure rather than improve systemic discrimination in the workplace.
Algorithms that Remember: Model Inversion Attacks and Data Protection Law
Oct 15, 2018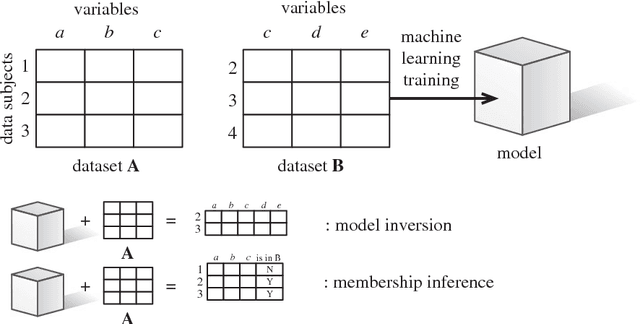
Many individuals are concerned about the governance of machine learning systems and the prevention of algorithmic harms. The EU's recent General Data Protection Regulation (GDPR) has been seen as a core tool for achieving better governance of this area. While the GDPR does apply to the use of models in some limited situations, most of its provisions relate to the governance of personal data, while models have traditionally been seen as intellectual property. We present recent work from the information security literature around `model inversion' and `membership inference' attacks, which indicate that the process of turning training data into machine learned systems is not one-way, and demonstrate how this could lead some models to be legally classified as personal data. Taking this as a probing experiment, we explore the different rights and obligations this would trigger and their utility, and posit future directions for algorithmic governance and regulation.
* 15 pages, 1 figure
Enslaving the Algorithm: From a "Right to an Explanation" to a "Right to Better Decisions"?
Jul 02, 2018As concerns about unfairness and discrimination in "black box" machine learning systems rise, a legal "right to an explanation" has emerged as a compellingly attractive approach for challenge and redress. We outline recent debates on the limited provisions in European data protection law, and introduce and analyze newer explanation rights in French administrative law and the draft modernized Council of Europe Convention 108. While individual rights can be useful, in privacy law they have historically unreasonably burdened the average data subject. "Meaningful information" about algorithmic logics is more technically possible than commonly thought, but this exacerbates a new "transparency fallacy"---an illusion of remedy rather than anything substantively helpful. While rights-based approaches deserve a firm place in the toolbox, other forms of governance, such as impact assessments, "soft law," judicial review, and model repositories deserve more attention, alongside catalyzing agencies acting for users to control algorithmic system design.
* 14 pages, 0 figures