 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental learning for audio classification with Hebbian Deep Neural Networks
Apr 20, 2026The ability of humans for lifelong learning is an inspiration for deep learning methods and in particular for continual learning. In this work, we apply Hebbian learning, a biologically inspired learning process, to sound classification. We propose a kernel plasticity approach that selectively modulates network kernels during incremental learning, acting on selected kernels to learn new information and on others to retain previous knowledge. Using the ESC-50 dataset, the proposed method achieves 76.3% overall accuracy over five incremental steps, outperforming a baseline without kernel plasticity (68.7%) and demonstrating significantly greater stability across tasks.
Federated Concept-Based Models: Interpretable models with distributed supervision
Feb 04, 2026Concept-based models (CMs) enhance interpretability in deep learning by grounding predictions in human-understandable concepts. However, concept annotations are expensive to obtain and rarely available at scale within a single data source. Federated learning (FL) could alleviate this limitation by enabling cross-institutional training that leverages concept annotations distributed across multiple data owners. Yet, FL lacks interpretable modeling paradigms. Integrating CMs with FL is non-trivial: CMs assume a fixed concept space and a predefined model architecture, whereas real-world FL is heterogeneous and non-stationary, with institutions joining over time and bringing new supervision. In this work, we propose Federated Concept-based Models (F-CMs), a new methodology for deploying CMs in evolving FL settings. F-CMs aggregate concept-level information across institutions and efficiently adapt the model architecture in response to changes in the available concept supervision, while preserving institutional privacy. Empirically, F-CMs preserve the accuracy and intervention effectiveness of training settings with full concept supervision, while outperforming non-adaptive federated baselines. Notably, F-CMs enable interpretable inference on concepts not available to a given institution, a key novelty with respect to existing approaches.
Mixture of Concept Bottleneck Experts
Feb 02, 2026Concept Bottleneck Models (CBMs) promote interpretability by grounding predictions in human-understandable concepts. However, existing CBMs typically fix their task predictor to a single linear or Boolean expression, limiting both predictive accuracy and adaptability to diverse user needs. We propose Mixture of Concept Bottleneck Experts (M-CBEs), a framework that generalizes existing CBMs along two dimensions: the number of experts and the functional form of each expert, exposing an underexplored region of the design space. We investigate this region by instantiating two novel models: Linear M-CBE, which learns a finite set of linear expressions, and Symbolic M-CBE, which leverages symbolic regression to discover expert functions from data under user-specified operator vocabularies. Empirical evaluation demonstrates that varying the mixture size and functional form provides a robust framework for navigating the accuracy-interpretability trade-off, adapting to different user and task needs.
V-CEM: Bridging Performance and Intervenability in Concept-based Models
Apr 04, 2025



Concept-based eXplainable AI (C-XAI) is a rapidly growing research field that enhances AI model interpretability by leveraging intermediate, human-understandable concepts. This approach not only enhances model transparency but also enables human intervention, allowing users to interact with these concepts to refine and improve the model's performance. Concept Bottleneck Models (CBMs) explicitly predict concepts before making final decisions, enabling interventions to correct misclassified concepts. While CBMs remain effective in Out-Of-Distribution (OOD) settings with intervention, they struggle to match the performance of black-box models. Concept Embedding Models (CEMs) address this by learning concept embeddings from both concept predictions and input data, enhancing In-Distribution (ID) accuracy but reducing the effectiveness of interventions, especially in OOD scenarios. In this work, we propose the Variational Concept Embedding Model (V-CEM), which leverages variational inference to improve intervention responsiveness in CEMs. We evaluated our model on various textual and visual datasets in terms of ID performance, intervention responsiveness in both ID and OOD settings, and Concept Representation Cohesiveness (CRC), a metric we propose to assess the quality of the concept embedding representations. The results demonstrate that V-CEM retains CEM-level ID performance while achieving intervention effectiveness similar to CBM in OOD settings, effectively reducing the gap between interpretability (intervention) and generalization (performance).
Causally Reliable Concept Bottleneck Models
Mar 06, 2025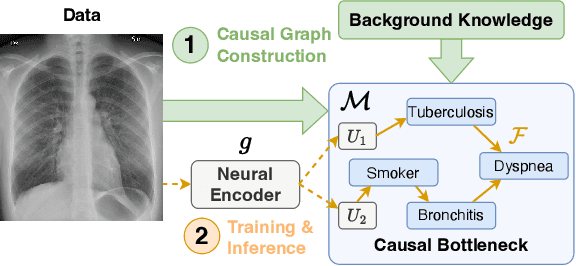



Concept-based models are an emerging paradigm in deep learning that constrains the inference process to operate through human-interpretable concepts, facilitating explainability and human interaction. However, these architectures, on par with popular opaque neural models, fail to account for the true causal mechanisms underlying the target phenomena represented in the data. This hampers their ability to support causal reasoning tasks, limits out-of-distribution generalization, and hinders the implementation of fairness constraints. To overcome these issues, we propose \emph{Causally reliable Concept Bottleneck Models} (C$^2$BMs), a class of concept-based architectures that enforce reasoning through a bottleneck of concepts structured according to a model of the real-world causal mechanisms. We also introduce a pipeline to automatically learn this structure from observational data and \emph{unstructured} background knowledge (e.g., scientific literature). Experimental evidence suggest that C$^2$BM are more interpretable, causally reliable, and improve responsiveness to interventions w.r.t. standard opaque and concept-based models, while maintaining their accuracy.
Neural Interpretable Reasoning
Feb 17, 2025

We formalize a novel modeling framework for achieving interpretability in deep learning, anchored in the principle of inference equivariance. While the direct verification of interpretability scales exponentially with the number of variables of the system, we show that this complexity can be mitigated by treating interpretability as a Markovian property and employing neural re-parametrization techniques. Building on these insights, we propose a new modeling paradigm -- neural generation and interpretable execution -- that enables scalable verification of equivariance. This paradigm provides a general approach for designing Neural Interpretable Reasoners that are not only expressive but also transparent.
Self-supervised Interpretable Concept-based Models for Text Classification
Jun 20, 2024



Despite their success, Large-Language Models (LLMs) still face criticism as their lack of interpretability limits their controllability and reliability. Traditional post-hoc interpretation methods, based on attention and gradient-based analysis, offer limited insight into the model's decision-making processes. In the image field, Concept-based models have emerged as explainable-by-design architectures, employing human-interpretable features as intermediate representations. However, these methods have not been yet adapted to textual data, mainly because they require expensive concept annotations, which are impractical for real-world text data. This paper addresses this challenge by proposing a self-supervised Interpretable Concept Embedding Models (ICEMs). We leverage the generalization abilities of LLMs to predict the concepts labels in a self-supervised way, while we deliver the final predictions with an interpretable function. The results of our experiments show that ICEMs can be trained in a self-supervised way achieving similar performance to fully supervised concept-based models and end-to-end black-box ones. Additionally, we show that our models are (i) interpretable, offering meaningful logical explanations for their predictions; (ii) interactable, allowing humans to modify intermediate predictions through concept interventions; and (iii) controllable, guiding the LLMs' decoding process to follow a required decision-making path.