 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability in Deep Time Series Models Demands Semantic Alignment
Feb 02, 2026Deep time series models continue to improve predictive performance, yet their deployment remains limited by their black-box nature. In response, existing interpretability approaches in the field keep focusing on explaining the internal model computations, without addressing whether they align or not with how a human would reason about the studied phenomenon. Instead, we state interpretability in deep time series models should pursue semantic alignment: predictions should be expressed in terms of variables that are meaningful to the end user, mediated by spatial and temporal mechanisms that admit user-dependent constraints. In this paper, we formalize this requirement and require that, once established, semantic alignment must be preserved under temporal evolution: a constraint with no analog in static settings. Provided with this definition, we outline a blueprint for semantically aligned deep time series models, identify properties that support trust, and discuss implications for model design.
Actionable Interpretability Must Be Defined in Terms of Symmetries
Jan 19, 2026This paper argues that interpretability research in Artificial Intelligence is fundamentally ill-posed as existing definitions of interpretability are not *actionable*: they fail to provide formal principles from which concrete modelling and inferential rules can be derived. We posit that for a definition of interpretability to be actionable, it must be given in terms of *symmetries*. We hypothesise that four symmetries suffice to (i) motivate core interpretability properties, (ii) characterize the class of interpretable models, and (iii) derive a unified formulation of interpretable inference (e.g., alignment, interventions, and counterfactuals) as a form of Bayesian inversion.
Towards explainable decision support using hybrid neural models for logistic terminal automation
Sep 10, 2025The integration of Deep Learning (DL) in System Dynamics (SD) modeling for transportation logistics offers significant advantages in scalability and predictive accuracy. However, these gains are often offset by the loss of explainability and causal reliability $-$ key requirements in critical decision-making systems. This paper presents a novel framework for interpretable-by-design neural system dynamics modeling that synergizes DL with techniques from Concept-Based Interpretability, Mechanistic Interpretability, and Causal Machine Learning. The proposed hybrid approach enables the construction of neural network models that operate on semantically meaningful and actionable variables, while retaining the causal grounding and transparency typical of traditional SD models. The framework is conceived to be applied to real-world case-studies from the EU-funded project AutoMoTIF, focusing on data-driven decision support, automation, and optimization of multimodal logistic terminals. We aim at showing how neuro-symbolic methods can bridge the gap between black-box predictive models and the need for critical decision support in complex dynamical environments within cyber-physical systems enabled by the industrial Internet-of-Things.
Causally Reliable Concept Bottleneck Models
Mar 06, 2025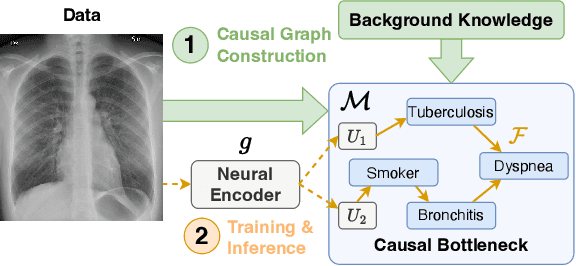



Concept-based models are an emerging paradigm in deep learning that constrains the inference process to operate through human-interpretable concepts, facilitating explainability and human interaction. However, these architectures, on par with popular opaque neural models, fail to account for the true causal mechanisms underlying the target phenomena represented in the data. This hampers their ability to support causal reasoning tasks, limits out-of-distribution generalization, and hinders the implementation of fairness constraints. To overcome these issues, we propose \emph{Causally reliable Concept Bottleneck Models} (C$^2$BMs), a class of concept-based architectures that enforce reasoning through a bottleneck of concepts structured according to a model of the real-world causal mechanisms. We also introduce a pipeline to automatically learn this structure from observational data and \emph{unstructured} background knowledge (e.g., scientific literature). Experimental evidence suggest that C$^2$BM are more interpretable, causally reliable, and improve responsiveness to interventions w.r.t. standard opaque and concept-based models, while maintaining their accuracy.
Machine Learning and Theory Ladenness -- A Phenomenological Account
Sep 17, 2024In recent years, the dissemination of machine learning (ML) methodologies in scientific research has prompted discussions on theory ladenness. More specifically, the issue of theory ladenness has remerged as questions about whether and how ML models (MLMs) and ML modelling strategies are impacted by the domain theory of the scientific field in which ML is used and implemented (e.g., physics, chemistry, biology, etc). On the one hand, some have argued that there is no difference between traditional (pre ML) and ML assisted science. In both cases, theory plays an essential and unavoidable role in the analysis of phenomena and the construction and use of models. Others have argued instead that ML methodologies and models are theory independent and, in some cases, even theory free. In this article, we argue that both positions are overly simplistic and do not advance our understanding of the interplay between ML methods and domain theories. Specifically, we provide an analysis of theory ladenness in ML assisted science. Our analysis reveals that, while the construction of MLMs can be relatively independent of domain theory, the practical implementation and interpretation of these models within a given specific domain still relies on fundamental theoretical assumptions and background knowledge.
Causal Concept Embedding Models: Beyond Causal Opacity in Deep Learning
May 28, 2024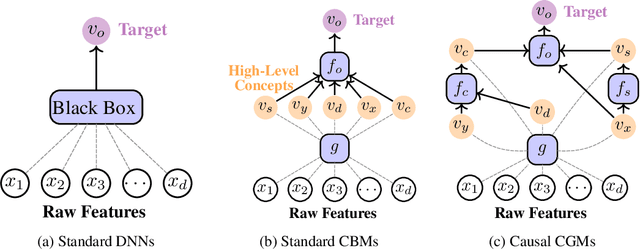



Causal opacity denotes the difficulty in understanding the "hidden" causal structure underlying a deep neural network's (DNN) reasoning. This leads to the inability to rely on and verify state-of-the-art DNN-based systems especially in high-stakes scenarios. For this reason, causal opacity represents a key open challenge at the intersection of deep learning, interpretability, and causality. This work addresses this gap by introducing Causal Concept Embedding Models (Causal CEMs), a class of interpretable models whose decision-making process is causally transparent by design. The results of our experiments show that Causal CEMs can: (i) match the generalization performance of causally-opaque models, (ii) support the analysis of interventional and counterfactual scenarios, thereby improving the model's causal interpretability and supporting the effective verification of its reliability and fairness, and (iii) enable human-in-the-loop corrections to mispredicted intermediate reasoning steps, boosting not just downstream accuracy after corrections but also accuracy of the explanation provided for a specific instance.
Addressing Social Misattributions of Large Language Models: An HCXAI-based Approach
Mar 26, 2024Human-centered explainable AI (HCXAI) advocates for the integration of social aspects into AI explanations. Central to the HCXAI discourse is the Social Transparency (ST) framework, which aims to make the socio-organizational context of AI systems accessible to their users. In this work, we suggest extending the ST framework to address the risks of social misattributions in Large Language Models (LLMs), particularly in sensitive areas like mental health. In fact LLMs, which are remarkably capable of simulating roles and personas, may lead to mismatches between designers' intentions and users' perceptions of social attributes, risking to promote emotional manipulation and dangerous behaviors, cases of epistemic injustice, and unwarranted trust. To address these issues, we propose enhancing the ST framework with a fifth 'W-question' to clarify the specific social attributions assigned to LLMs by its designers and users. This addition aims to bridge the gap between LLM capabilities and user perceptions, promoting the ethically responsible development and use of LLM-based technology.