 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemology gives a Future to Complementarity in Human-AI Interactions
Jan 14, 2026Human-AI complementarity is the claim that a human supported by an AI system can outperform either alone in a decision-making process. Since its introduction in the human-AI interaction literature, it has gained traction by generalizing the reliance paradigm and by offering a more practical alternative to the contested construct of 'trust in AI.' Yet complementarity faces key theoretical challenges: it lacks precise theoretical anchoring, it is formalized just as a post hoc indicator of relative predictive accuracy, it remains silent about other desiderata of human-AI interactions and it abstracts away from the magnitude-cost profile of its performance gain. As a result, complementarity is difficult to obtain in empirical settings. In this work, we leverage epistemology to address these challenges by reframing complementarity within the discourse on justificatory AI. Drawing on computational reliabilism, we argue that historical instances of complementarity function as evidence that a given human-AI interaction is a reliable epistemic process for a given predictive task. Together with other reliability indicators assessing the alignment of the human-AI team with the epistemic standards and socio-technical practices, complementarity contributes to the degree of reliability of human-AI teams when generating predictions. This supports the practical reasoning of those affected by these outputs -- patients, managers, regulators, and others. In summary, our approach suggests that the role and value of complementarity lies not in providing a relative measure of predictive accuracy, but in helping calibrate decision-making to the reliability of AI-supported processes that increasingly shape everyday life.
A Scoping Review of the Ethical Perspectives on Anthropomorphising Large Language Model-Based Conversational Agents
Jan 14, 2026Anthropomorphisation -- the phenomenon whereby non-human entities are ascribed human-like qualities -- has become increasingly salient with the rise of large language model (LLM)-based conversational agents (CAs). Unlike earlier chatbots, LLM-based CAs routinely generate interactional and linguistic cues, such as first-person self-reference, epistemic and affective expressions that empirical work shows can increase engagement. On the other hand, anthropomorphisation raises ethical concerns, including deception, overreliance, and exploitative relationship framing, while some authors argue that anthropomorphic interaction may support autonomy, well-being, and inclusion. Despite increasing interest in the phenomenon, literature remains fragmented across domains and varies substantially in how it defines, operationalizes, and normatively evaluates anthropomorphisation. This scoping review maps ethically oriented work on anthropomorphising LLM-based CAs across five databases and three preprint repositories. We synthesize (1) conceptual foundations, (2) ethical challenges and opportunities, and (3) methodological approaches. We find convergence on attribution-based definitions but substantial divergence in operationalization, a predominantly risk-forward normative framing, and limited empirical work that links observed interaction effects to actionable governance guidance. We conclude with a research agenda and design/governance recommendations for ethically deploying anthropomorphic cues in LLM-based conversational agents.
Why AI Safety Requires Uncertainty, Incomplete Preferences, and Non-Archimedean Utilities
Dec 29, 2025How can we ensure that AI systems are aligned with human values and remain safe? We can study this problem through the frameworks of the AI assistance and the AI shutdown games. The AI assistance problem concerns designing an AI agent that helps a human to maximise their utility function(s). However, only the human knows these function(s); the AI assistant must learn them. The shutdown problem instead concerns designing AI agents that: shut down when a shutdown button is pressed; neither try to prevent nor cause the pressing of the shutdown button; and otherwise accomplish their task competently. In this paper, we show that addressing these challenges requires AI agents that can reason under uncertainty and handle both incomplete and non-Archimedean preferences.
Machine Learning and Theory Ladenness -- A Phenomenological Account
Sep 17, 2024In recent years, the dissemination of machine learning (ML) methodologies in scientific research has prompted discussions on theory ladenness. More specifically, the issue of theory ladenness has remerged as questions about whether and how ML models (MLMs) and ML modelling strategies are impacted by the domain theory of the scientific field in which ML is used and implemented (e.g., physics, chemistry, biology, etc). On the one hand, some have argued that there is no difference between traditional (pre ML) and ML assisted science. In both cases, theory plays an essential and unavoidable role in the analysis of phenomena and the construction and use of models. Others have argued instead that ML methodologies and models are theory independent and, in some cases, even theory free. In this article, we argue that both positions are overly simplistic and do not advance our understanding of the interplay between ML methods and domain theories. Specifically, we provide an analysis of theory ladenness in ML assisted science. Our analysis reveals that, while the construction of MLMs can be relatively independent of domain theory, the practical implementation and interpretation of these models within a given specific domain still relies on fundamental theoretical assumptions and background knowledge.
Addressing Social Misattributions of Large Language Models: An HCXAI-based Approach
Mar 26, 2024Human-centered explainable AI (HCXAI) advocates for the integration of social aspects into AI explanations. Central to the HCXAI discourse is the Social Transparency (ST) framework, which aims to make the socio-organizational context of AI systems accessible to their users. In this work, we suggest extending the ST framework to address the risks of social misattributions in Large Language Models (LLMs), particularly in sensitive areas like mental health. In fact LLMs, which are remarkably capable of simulating roles and personas, may lead to mismatches between designers' intentions and users' perceptions of social attributes, risking to promote emotional manipulation and dangerous behaviors, cases of epistemic injustice, and unwarranted trust. To address these issues, we propose enhancing the ST framework with a fifth 'W-question' to clarify the specific social attributions assigned to LLMs by its designers and users. This addition aims to bridge the gap between LLM capabilities and user perceptions, promoting the ethically responsible development and use of LLM-based technology.
Belief Revision in Sentential Decision Diagrams
Jan 20, 2022Belief revision is the task of modifying a knowledge base when new information becomes available, while also respecting a number of desirable properties. Classical belief revision schemes have been already specialised to \emph{binary decision diagrams} (BDDs), the classical formalism to compactly represent propositional knowledge. These results also apply to \emph{ordered} BDDs (OBDDs), a special class of BDDs, designed to guarantee canonicity. Yet, those revisions cannot be applied to \emph{sentential decision diagrams} (SDDs), a typically more compact but still canonical class of Boolean circuits, which generalizes OBDDs, while not being a subclass of BDDs. Here we fill this gap by deriving a general revision algorithm for SDDs based on a syntactic characterisation of Dalal revision. A specialised procedure for DNFs is also presented. Preliminary experiments performed with randomly generated knowledge bases show the advantages of directly perform revision within SDD formalism.
Structural Learning of Probabilistic Sentential Decision Diagrams under Partial Closed-World Assumption
Jul 26, 2021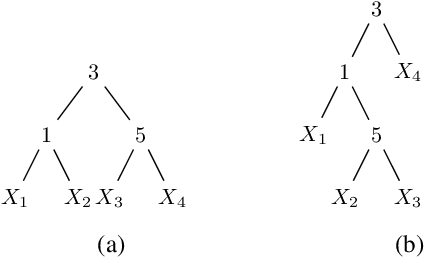
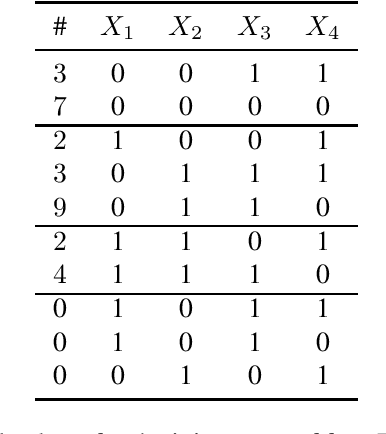
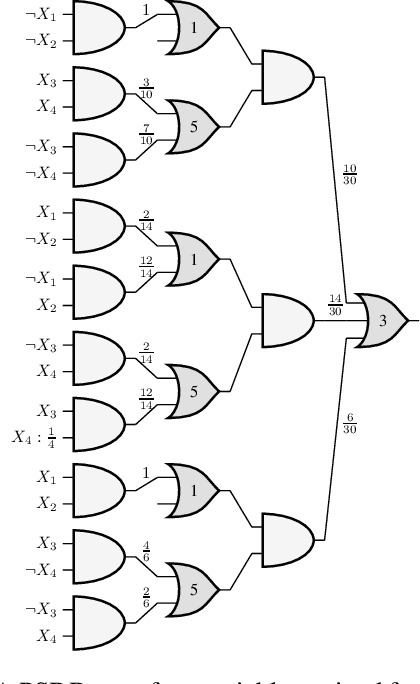
Probabilistic sentential decision diagrams are a class of structured-decomposable probabilistic circuits especially designed to embed logical constraints. To adapt the classical LearnSPN scheme to learn the structure of these models, we propose a new scheme based on a partial closed-world assumption: data implicitly provide the logical base of the circuit. Sum nodes are thus learned by recursively clustering batches in the initial data base, while the partitioning of the variables obeys a given input vtree. Preliminary experiments show that the proposed approach might properly fit training data, and generalize well to test data, provided that these remain consistent with the underlying logical base, that is a relaxation of the training data base.
Tractable Inference in Credal Sentential Decision Diagrams
Aug 19, 2020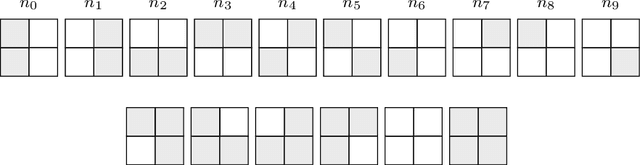
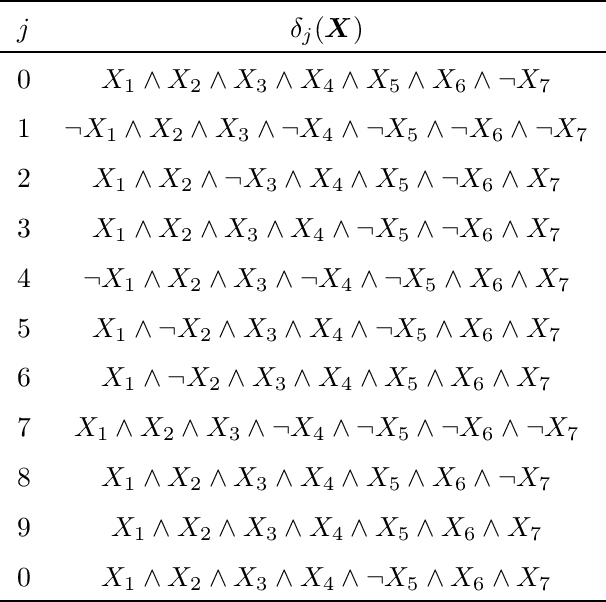
Probabilistic sentential decision diagrams are logic circuits where the inputs of disjunctive gates are annotated by probability values. They allow for a compact representation of joint probability mass functions defined over sets of Boolean variables, that are also consistent with the logical constraints defined by the circuit. The probabilities in such a model are usually learned from a set of observations. This leads to overconfident and prior-dependent inferences when data are scarce, unreliable or conflicting. In this work, we develop the credal sentential decision diagrams, a generalisation of their probabilistic counterpart that allows for replacing the local probabilities with (so-called credal) sets of mass functions. These models induce a joint credal set over the set of Boolean variables, that sharply assigns probability zero to states inconsistent with the logical constraints. Three inference algorithms are derived for these models, these allow to compute: (i) the lower and upper probabilities of an observation for an arbitrary number of variables; (ii) the lower and upper conditional probabilities for the state of a single variable given an observation; (iii) whether or not all the probabilistic sentential decision diagrams compatible with the credal specification have the same most probable explanation of a given set of variables given an observation of the other variables. These inferences are tractable, as all the three algorithms, based on bottom-up traversal with local linear programming tasks on the disjunctive gates, can be solved in polynomial time with respect to the circuit size. For a first empirical validation, we consider a simple application based on noisy seven-segment display images. The credal models are observed to properly distinguish between easy and hard-to-detect instances and outperform other generative models not able to cope with logical constraints.