 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-CEM: Bridging Performance and Intervenability in Concept-based Models
Apr 04, 2025



Concept-based eXplainable AI (C-XAI) is a rapidly growing research field that enhances AI model interpretability by leveraging intermediate, human-understandable concepts. This approach not only enhances model transparency but also enables human intervention, allowing users to interact with these concepts to refine and improve the model's performance. Concept Bottleneck Models (CBMs) explicitly predict concepts before making final decisions, enabling interventions to correct misclassified concepts. While CBMs remain effective in Out-Of-Distribution (OOD) settings with intervention, they struggle to match the performance of black-box models. Concept Embedding Models (CEMs) address this by learning concept embeddings from both concept predictions and input data, enhancing In-Distribution (ID) accuracy but reducing the effectiveness of interventions, especially in OOD scenarios. In this work, we propose the Variational Concept Embedding Model (V-CEM), which leverages variational inference to improve intervention responsiveness in CEMs. We evaluated our model on various textual and visual datasets in terms of ID performance, intervention responsiveness in both ID and OOD settings, and Concept Representation Cohesiveness (CRC), a metric we propose to assess the quality of the concept embedding representations. The results demonstrate that V-CEM retains CEM-level ID performance while achieving intervention effectiveness similar to CBM in OOD settings, effectively reducing the gap between interpretability (intervention) and generalization (performance).
Self-supervised Interpretable Concept-based Models for Text Classification
Jun 20, 2024



Despite their success, Large-Language Models (LLMs) still face criticism as their lack of interpretability limits their controllability and reliability. Traditional post-hoc interpretation methods, based on attention and gradient-based analysis, offer limited insight into the model's decision-making processes. In the image field, Concept-based models have emerged as explainable-by-design architectures, employing human-interpretable features as intermediate representations. However, these methods have not been yet adapted to textual data, mainly because they require expensive concept annotations, which are impractical for real-world text data. This paper addresses this challenge by proposing a self-supervised Interpretable Concept Embedding Models (ICEMs). We leverage the generalization abilities of LLMs to predict the concepts labels in a self-supervised way, while we deliver the final predictions with an interpretable function. The results of our experiments show that ICEMs can be trained in a self-supervised way achieving similar performance to fully supervised concept-based models and end-to-end black-box ones. Additionally, we show that our models are (i) interpretable, offering meaningful logical explanations for their predictions; (ii) interactable, allowing humans to modify intermediate predictions through concept interventions; and (iii) controllable, guiding the LLMs' decoding process to follow a required decision-making path.
Event-Based Eye Tracking. AIS 2024 Challenge Survey
Apr 17, 2024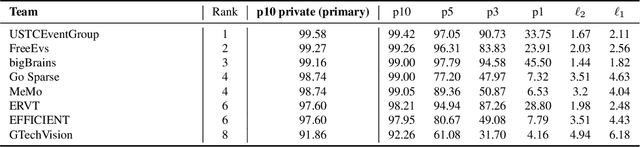
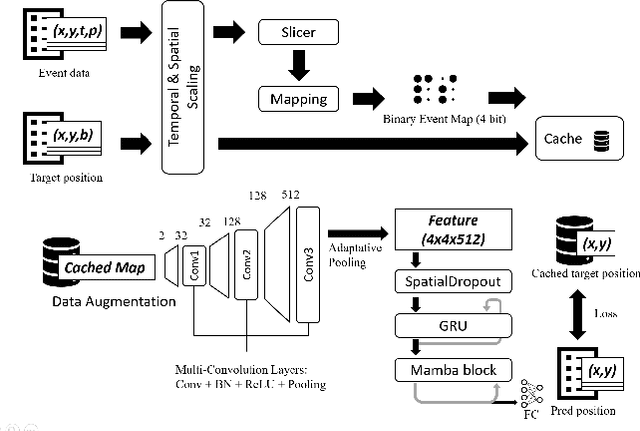
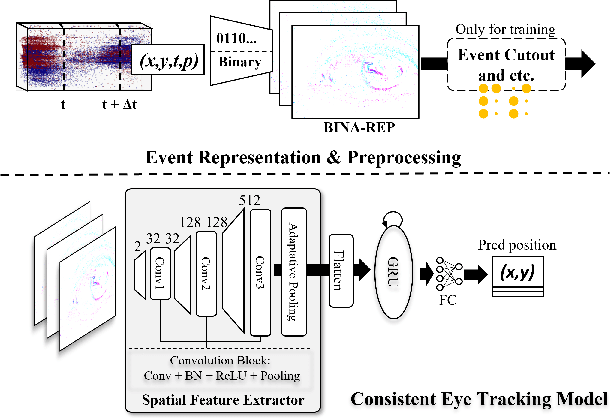

This survey reviews the AIS 2024 Event-Based Eye Tracking (EET) Challenge. The task of the challenge focuses on processing eye movement recorded with event cameras and predicting the pupil center of the eye. The challenge emphasizes efficient eye tracking with event cameras to achieve good task accuracy and efficiency trade-off. During the challenge period, 38 participants registered for the Kaggle competition, and 8 teams submitted a challenge factsheet. The novel and diverse methods from the submitted factsheets are reviewed and analyzed in this survey to advance future event-based eye tracking research.
Visual Navigation Using Sparse Optical Flow and Time-to-Transit
Nov 18, 2021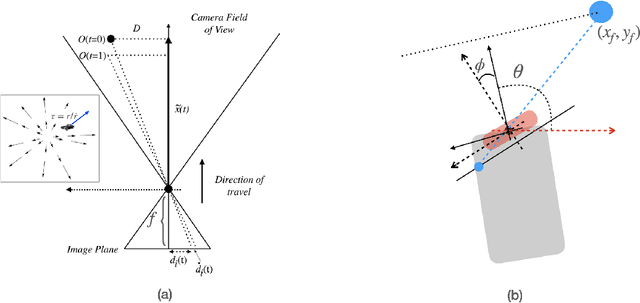
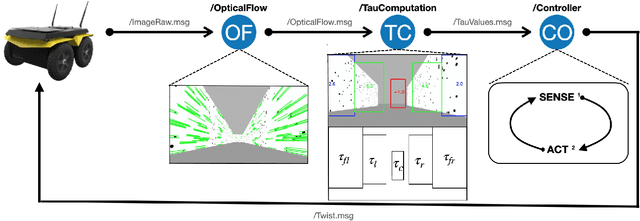
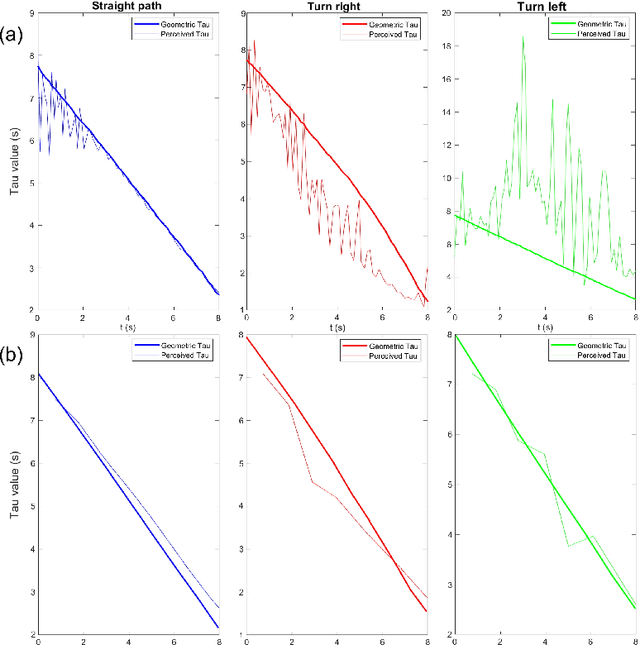
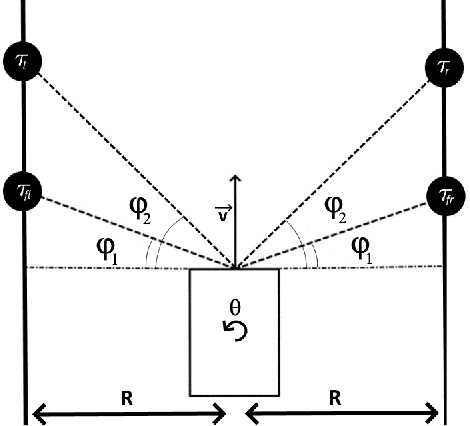
Drawing inspiration from biology, we describe the way in which visual sensing with a monocular camera can provide a reliable signal for navigation of mobile robots. The work takes inspiration from a classic paper by Lee and Reddish (Nature, 1981, https://doi.org/10.1038/293293a0) in which they outline a behavioral strategy pursued by diving sea birds based on a visual cue called time-to-contact. A closely related concept of time-to-transit, tau, is defined, and it is shown that idealized steering laws based on monocular camera perceptions of tau can reliably and robustly steer a mobile vehicle within a wide variety of spaces in which features perceived to lie on walls and other objects in the environment provide adequate visual cues. The contribution of the paper is two-fold. It provides a simple theory of robust vision-based steering control. It goes on to show how the theory guides the implementation of robust visual navigation using ROS-Gazebo simulations as well as deployment and experiments with a camera-equipped Jackal robot. As far as we know, the experiments described below are the first to demonstrate visual navigation based on tau.