 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Document Selection on Query-focused Text Analysis
Apr 13, 2026Analyses of document collections often require selecting what data to analyze, as not all documents are relevant to a particular research question and computational constraints preclude analyzing all documents, yet little work has examined effects of selection strategy choices. We systematically evaluate seven selection methods (from random selection to hybrid retrieval) on outputs from four text analyses methods (LDA, BERTopic, TopicGPT, HiCode) over two datasets with 26 open-ended queries. Our evaluation reveals practice guidance: semantic or hybrid retrieval offer strong go-to approaches that avoid the pitfalls of weaker selection strategies and the unnecessary compute overhead of more complicated ones. Overall, our evaluation framework establishes data selection as a methodological decision, rather than a practical necessity, inviting the development of new strategies.
Extracting Victim Counts from Text
Feb 23, 2023


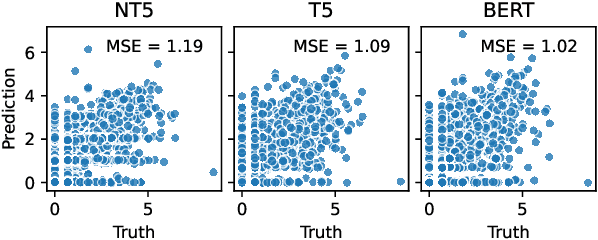
Decision-makers in the humanitarian sector rely on timely and exact information during crisis events. Knowing how many civilians were injured during an earthquake is vital to allocate aids properly. Information about such victim counts is often only available within full-text event descriptions from newspapers and other reports. Extracting numbers from text is challenging: numbers have different formats and may require numeric reasoning. This renders purely string matching-based approaches insufficient. As a consequence, fine-grained counts of injured, displaced, or abused victims beyond fatalities are often not extracted and remain unseen. We cast victim count extraction as a question answering (QA) task with a regression or classification objective. We compare regex, dependency parsing, semantic role labeling-based approaches, and advanced text-to-text models. Beyond model accuracy, we analyze extraction reliability and robustness which are key for this sensitive task. In particular, we discuss model calibration and investigate few-shot and out-of-distribution performance. Ultimately, we make a comprehensive recommendation on which model to select for different desiderata and data domains. Our work is among the first to apply numeracy-focused large language models in a real-world use case with a positive impact.
Towards Automatic Bias Detection in Knowledge Graphs
Sep 19, 2021
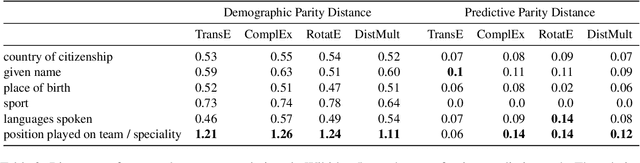


With the recent surge in social applications relying on knowledge graphs, the need for techniques to ensure fairness in KG based methods is becoming increasingly evident. Previous works have demonstrated that KGs are prone to various social biases, and have proposed multiple methods for debiasing them. However, in such studies, the focus has been on debiasing techniques, while the relations to be debiased are specified manually by the user. As manual specification is itself susceptible to human cognitive bias, there is a need for a system capable of quantifying and exposing biases, that can support more informed decisions on what to debias. To address this gap in the literature, we describe a framework for identifying biases present in knowledge graph embeddings, based on numerical bias metrics. We illustrate the framework with three different bias measures on the task of profession prediction, and it can be flexibly extended to further bias definitions and applications. The relations flagged as biased can then be handed to decision makers for judgement upon subsequent debiasing.