 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlangvolution: A Causal Analysis of Semantic Change and Frequency Dynamics in Slang
Mar 09, 2022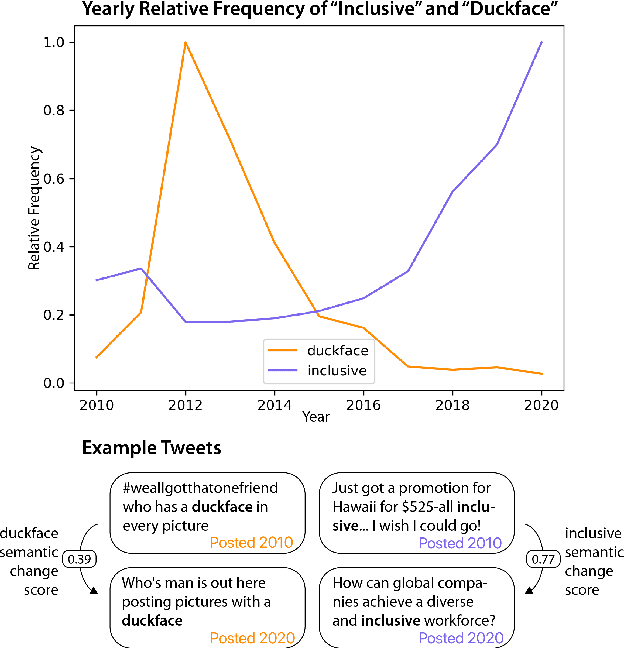

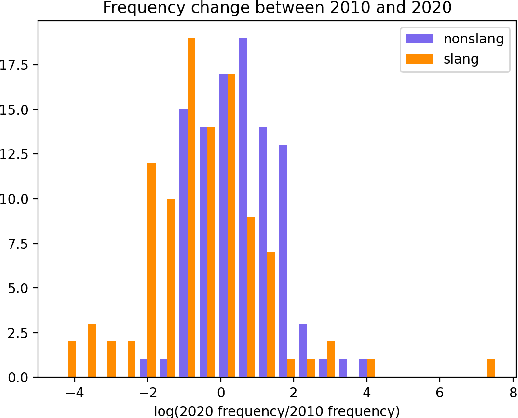
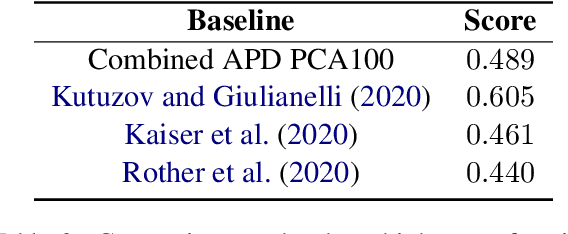
Languages are continuously undergoing changes, and the mechanisms that underlie these changes are still a matter of debate. In this work, we approach language evolution through the lens of causality in order to model not only how various distributional factors associate with language change, but how they causally affect it. In particular, we study slang, which is an informal language that is typically restricted to a specific group or social setting. We analyze the semantic change and frequency shift of slang words and compare them to those of standard, nonslang words. With causal discovery and causal inference techniques, we measure the effect that word type (slang/nonslang) has on both semantic change and frequency shift, as well as its relationship to frequency, polysemy and part of speech. Our analysis provides some new insights in the study of semantic change, e.g., we show that slang words undergo less semantic change but tend to have larger frequency shifts over time.
Towards Automatic Bias Detection in Knowledge Graphs
Sep 19, 2021
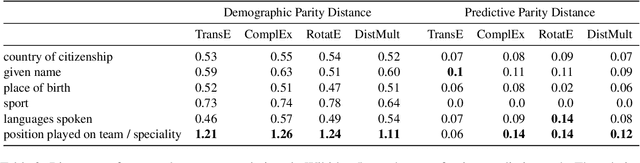


With the recent surge in social applications relying on knowledge graphs, the need for techniques to ensure fairness in KG based methods is becoming increasingly evident. Previous works have demonstrated that KGs are prone to various social biases, and have proposed multiple methods for debiasing them. However, in such studies, the focus has been on debiasing techniques, while the relations to be debiased are specified manually by the user. As manual specification is itself susceptible to human cognitive bias, there is a need for a system capable of quantifying and exposing biases, that can support more informed decisions on what to debias. To address this gap in the literature, we describe a framework for identifying biases present in knowledge graph embeddings, based on numerical bias metrics. We illustrate the framework with three different bias measures on the task of profession prediction, and it can be flexibly extended to further bias definitions and applications. The relations flagged as biased can then be handed to decision makers for judgement upon subsequent debiasing.
Recovering Barabási-Albert Parameters of Graphs through Disentanglement
May 04, 2021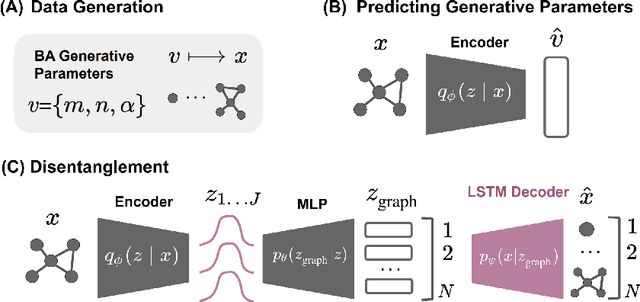


Classical graph modeling approaches such as Erd\H{o}s R\'{e}nyi (ER) random graphs or Barab\'asi-Albert (BA) graphs, here referred to as stylized models, aim to reproduce properties of real-world graphs in an interpretable way. While useful, graph generation with stylized models requires domain knowledge and iterative trial and error simulation. Previous work by Stoehr et al. (2019) addresses these issues by learning the generation process from graph data, using a disentanglement-focused deep autoencoding framework, more specifically, a $\beta$-Variational Autoencoder ($\beta$-VAE). While they successfully recover the generative parameters of ER graphs through the model's latent variables, their model performs badly on sequentially generated graphs such as BA graphs, due to their oversimplified decoder. We focus on recovering the generative parameters of BA graphs by replacing their $\beta$-VAE decoder with a sequential one. We first learn the generative BA parameters in a supervised fashion using a Graph Neural Network (GNN) and a Random Forest Regressor, by minimizing the squared loss between the true generative parameters and the latent variables. Next, we train a $\beta$-VAE model, combining the GNN encoder from the first stage with an LSTM-based decoder with a customized loss.
Point of Care Image Analysis for COVID-19
Nov 10, 2020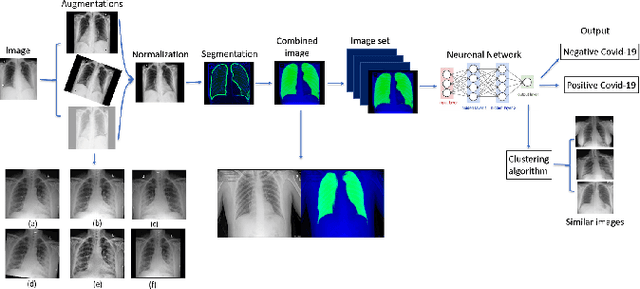

Early detection of COVID-19 is key in containing the pandemic. Disease detection and evaluation based on imaging is fast and cheap and therefore plays an important role in COVID-19 handling. COVID-19 is easier to detect in chest CT, however, it is expensive, non-portable, and difficult to disinfect, making it unfit as a point-of-care (POC) modality. On the other hand, chest X-ray (CXR) and lung ultrasound (LUS) are widely used, yet, COVID-19 findings in these modalities are not always very clear. Here we train deep neural networks to significantly enhance the capability to detect, grade and monitor COVID-19 patients using CXRs and LUS. Collaborating with several hospitals in Israel we collect a large dataset of CXRs and use this dataset to train a neural network obtaining above 90% detection rate for COVID-19. In addition, in collaboration with ULTRa (Ultrasound Laboratory Trento, Italy) and hospitals in Italy we obtained POC ultrasound data with annotations of the severity of disease and trained a deep network for automatic severity grading.
COVID-19 Classification of X-ray Images Using Deep Neural Networks
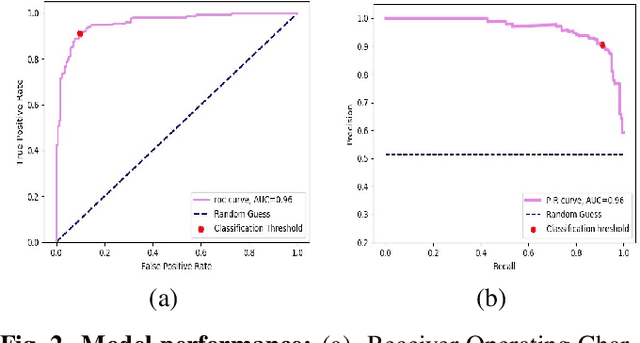
Oct 07, 2020In the midst of the coronavirus disease 2019 (COVID-19) outbreak, chest X-ray (CXR) imaging is playing an important role in the diagnosis and monitoring of patients with COVID-19. Machine learning solutions have been shown to be useful for X-ray analysis and classification in a range of medical contexts. The purpose of this study is to create and evaluate a machine learning model for diagnosis of COVID-19, and to provide a tool for searching for similar patients according to their X-ray scans. In this retrospective study, a classifier was built using a pre-trained deep learning model (ReNet50) and enhanced by data augmentation and lung segmentation to detect COVID-19 in frontal CXR images collected between January 2018 and July 2020 in four hospitals in Israel. A nearest-neighbors algorithm was implemented based on the network results that identifies the images most similar to a given image. The model was evaluated using accuracy, sensitivity, area under the curve (AUC) of receiver operating characteristic (ROC) curve and of the precision-recall (P-R) curve. The dataset sourced for this study includes 2362 CXRs, balanced for positive and negative COVID-19, from 1384 patients (63 +/- 18 years, 552 men). Our model achieved 89.7% (314/350) accuracy and 87.1% (156/179) sensitivity in classification of COVID-19 on a test dataset comprising 15% (350 of 2326) of the original data, with AUC of ROC 0.95 and AUC of the P-R curve 0.94. For each image we retrieve images with the most similar DNN-based image embeddings; these can be used to compare with previous cases.