 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal K-Similarity Constraint for Federated Learning with Label Noise
Nov 09, 2025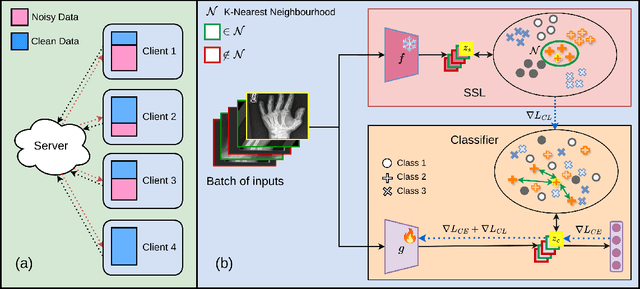

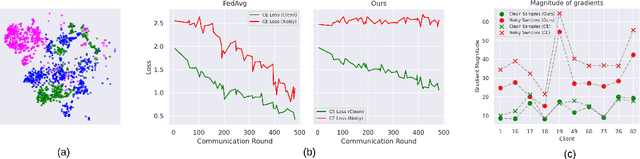
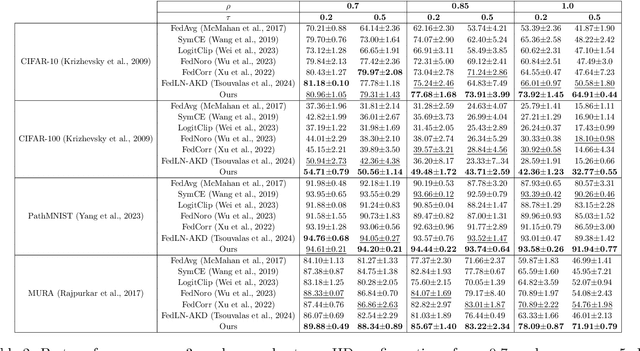
Federated learning on clients with noisy labels is a challenging problem, as such clients can infiltrate the global model, impacting the overall generalizability of the system. Existing methods proposed to handle noisy clients assume that a sufficient number of clients with clean labels are available, which can be leveraged to learn a robust global model while dampening the impact of noisy clients. This assumption fails when a high number of heterogeneous clients contain noisy labels, making the existing approaches ineffective. In such scenarios, it is important to locally regularize the clients before communication with the global model, to ensure the global model isn't corrupted by noisy clients. While pre-trained self-supervised models can be effective for local regularization, existing centralized approaches relying on pretrained initialization are impractical in a federated setting due to the potentially large size of these models, which increases communication costs. In that line, we propose a regularization objective for client models that decouples the pre-trained and classification models by enforcing similarity between close data points within the client. We leverage the representation space of a self-supervised pretrained model to evaluate the closeness among examples. This regularization, when applied with the standard objective function for the downstream task in standard noisy federated settings, significantly improves performance, outperforming existing state-of-the-art federated methods in multiple computer vision and medical image classification benchmarks. Unlike other techniques that rely on self-supervised pretrained initialization, our method does not require the pretrained model and classifier backbone to share the same architecture, making it architecture-agnostic.
HAMLOCK: HArdware-Model LOgically Combined attacK
Oct 22, 2025The growing use of third-party hardware accelerators (e.g., FPGAs, ASICs) for deep neural networks (DNNs) introduces new security vulnerabilities. Conventional model-level backdoor attacks, which only poison a model's weights to misclassify inputs with a specific trigger, are often detectable because the entire attack logic is embedded within the model (i.e., software), creating a traceable layer-by-layer activation path. This paper introduces the HArdware-Model Logically Combined Attack (HAMLOCK), a far stealthier threat that distributes the attack logic across the hardware-software boundary. The software (model) is now only minimally altered by tuning the activations of few neurons to produce uniquely high activation values when a trigger is present. A malicious hardware Trojan detects those unique activations by monitoring the corresponding neurons' most significant bit or the 8-bit exponents and triggers another hardware Trojan to directly manipulate the final output logits for misclassification. This decoupled design is highly stealthy, as the model itself contains no complete backdoor activation path as in conventional attacks and hence, appears fully benign. Empirically, across benchmarks like MNIST, CIFAR10, GTSRB, and ImageNet, HAMLOCK achieves a near-perfect attack success rate with a negligible clean accuracy drop. More importantly, HAMLOCK circumvents the state-of-the-art model-level defenses without any adaptive optimization. The hardware Trojan is also undetectable, incurring area and power overheads as low as 0.01%, which is easily masked by process and environmental noise. Our findings expose a critical vulnerability at the hardware-software interface, demanding new cross-layer defenses against this emerging threat.
Surgical Vision World Model
Mar 03, 2025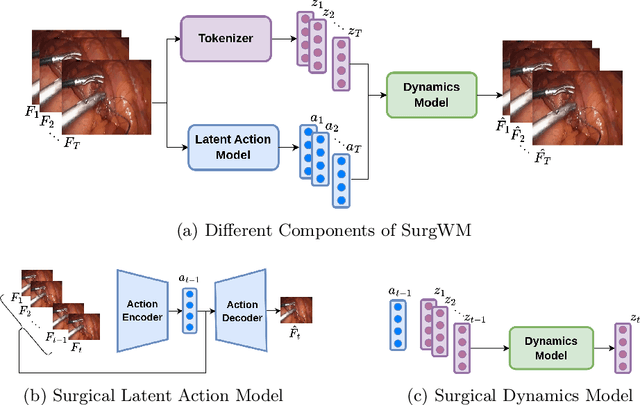
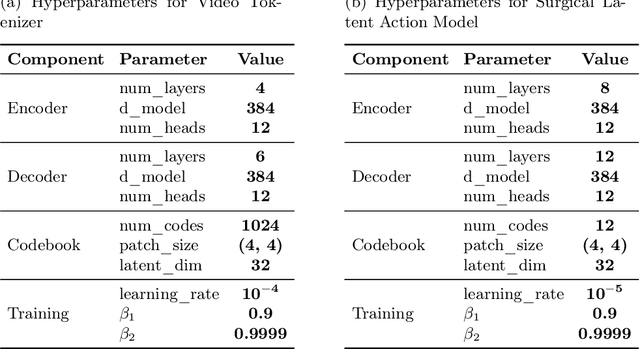
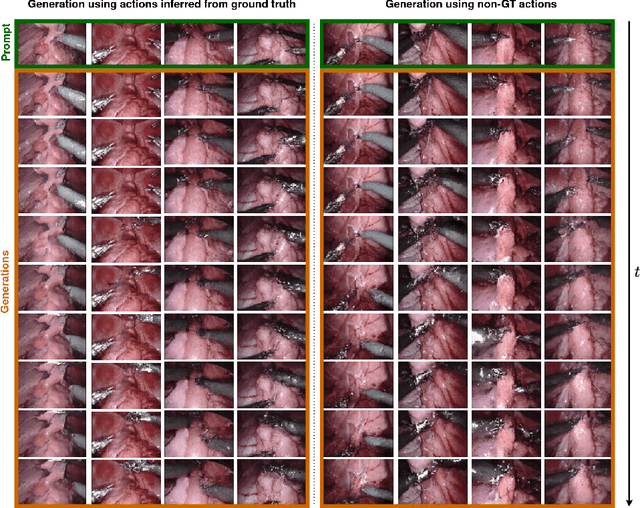
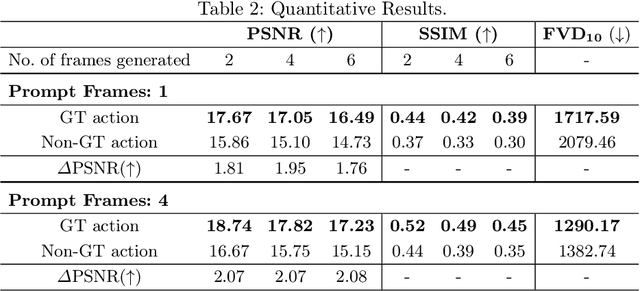
Realistic and interactive surgical simulation has the potential to facilitate crucial applications, such as medical professional training and autonomous surgical agent training. In the natural visual domain, world models have enabled action-controlled data generation, demonstrating the potential to train autonomous agents in interactive simulated environments when large-scale real data acquisition is infeasible. However, such works in the surgical domain have been limited to simplified computer simulations, and lack realism. Furthermore, existing literature in world models has predominantly dealt with action-labeled data, limiting their applicability to real-world surgical data, where obtaining action annotation is prohibitively expensive. Inspired by the recent success of Genie in leveraging unlabeled video game data to infer latent actions and enable action-controlled data generation, we propose the first surgical vision world model. The proposed model can generate action-controllable surgical data and the architecture design is verified with extensive experiments on the unlabeled SurgToolLoc-2022 dataset. Codes and implementation details are available at https://github.com/bhattarailab/Surgical-Vision-World-Model
CAR-MFL: Cross-Modal Augmentation by Retrieval for Multimodal Federated Learning with Missing Modalities
Jul 11, 2024Multimodal AI has demonstrated superior performance over unimodal approaches by leveraging diverse data sources for more comprehensive analysis. However, applying this effectiveness in healthcare is challenging due to the limited availability of public datasets. Federated learning presents an exciting solution, allowing the use of extensive databases from hospitals and health centers without centralizing sensitive data, thus maintaining privacy and security. Yet, research in multimodal federated learning, particularly in scenarios with missing modalities a common issue in healthcare datasets remains scarce, highlighting a critical area for future exploration. Toward this, we propose a novel method for multimodal federated learning with missing modalities. Our contribution lies in a novel cross-modal data augmentation by retrieval, leveraging the small publicly available dataset to fill the missing modalities in the clients. Our method learns the parameters in a federated manner, ensuring privacy protection and improving performance in multiple challenging multimodal benchmarks in the medical domain, surpassing several competitive baselines. Code Available: https://github.com/bhattarailab/CAR-MFL
Investigating the Robustness of Vision Transformers against Label Noise in Medical Image Classification
Feb 26, 2024Label noise in medical image classification datasets significantly hampers the training of supervised deep learning methods, undermining their generalizability. The test performance of a model tends to decrease as the label noise rate increases. Over recent years, several methods have been proposed to mitigate the impact of label noise in medical image classification and enhance the robustness of the model. Predominantly, these works have employed CNN-based architectures as the backbone of their classifiers for feature extraction. However, in recent years, Vision Transformer (ViT)-based backbones have replaced CNNs, demonstrating improved performance and a greater ability to learn more generalizable features, especially when the dataset is large. Nevertheless, no prior work has rigorously investigated how transformer-based backbones handle the impact of label noise in medical image classification. In this paper, we investigate the architectural robustness of ViT against label noise and compare it to that of CNNs. We use two medical image classification datasets -- COVID-DU-Ex, and NCT-CRC-HE-100K -- both corrupted by injecting label noise at various rates. Additionally, we show that pretraining is crucial for ensuring ViT's improved robustness against label noise in supervised training.
Investigation of Federated Learning Algorithms for Retinal Optical Coherence Tomography Image Classification with Statistical Heterogeneity
Feb 15, 2024Purpose: We apply federated learning to train an OCT image classifier simulating a realistic scenario with multiple clients and statistical heterogeneous data distribution where data in the clients lack samples of some categories entirely. Methods: We investigate the effectiveness of FedAvg and FedProx to train an OCT image classification model in a decentralized fashion, addressing privacy concerns associated with centralizing data. We partitioned a publicly available OCT dataset across multiple clients under IID and Non-IID settings and conducted local training on the subsets for each client. We evaluated two federated learning methods, FedAvg and FedProx for these settings. Results: Our experiments on the dataset suggest that under IID settings, both methods perform on par with training on a central data pool. However, the performance of both algorithms declines as we increase the statistical heterogeneity across the client data, while FedProx consistently performs better than FedAvg in the increased heterogeneity settings. Conclusion: Despite the effectiveness of federated learning in the utilization of private data across multiple medical institutions, the large number of clients and heterogeneous distribution of labels deteriorate the performance of both algorithms. Notably, FedProx appears to be more robust to the increased heterogeneity.
Medical Vision Language Pretraining: A survey
Dec 11, 2023Medical Vision Language Pretraining (VLP) has recently emerged as a promising solution to the scarcity of labeled data in the medical domain. By leveraging paired/unpaired vision and text datasets through self-supervised learning, models can be trained to acquire vast knowledge and learn robust feature representations. Such pretrained models have the potential to enhance multiple downstream medical tasks simultaneously, reducing the dependency on labeled data. However, despite recent progress and its potential, there is no such comprehensive survey paper that has explored the various aspects and advancements in medical VLP. In this paper, we specifically review existing works through the lens of different pretraining objectives, architectures, downstream evaluation tasks, and datasets utilized for pretraining and downstream tasks. Subsequently, we delve into current challenges in medical VLP, discussing existing and potential solutions, and conclude by highlighting future directions. To the best of our knowledge, this is the first survey focused on medical VLP.