 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape and Style GAN-based Multispectral Data Augmentation for Crop/Weed Segmentation in Precision Farming
Jul 19, 2024
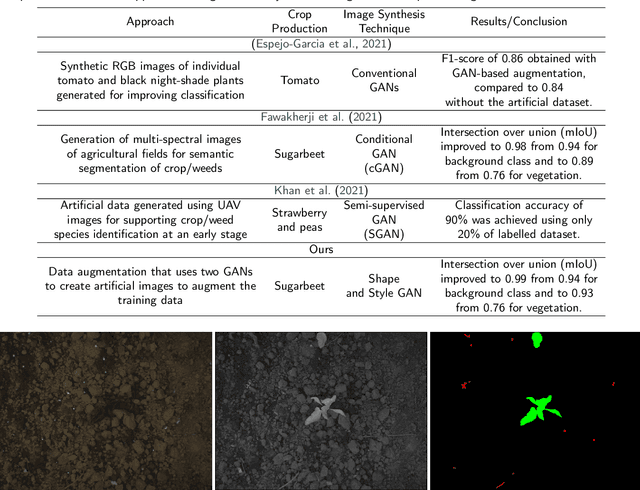
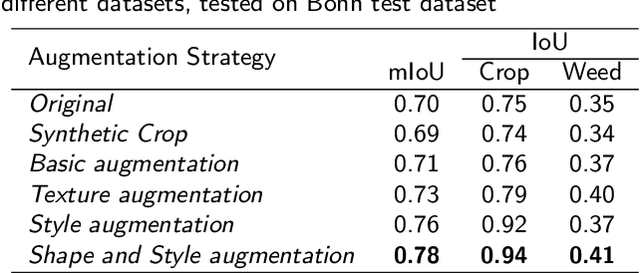
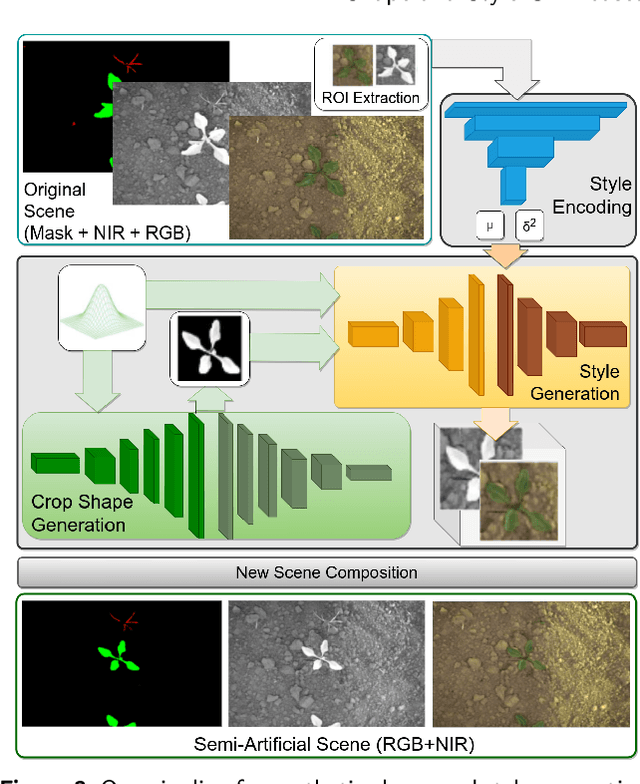
The use of deep learning methods for precision farming is gaining increasing interest. However, collecting training data in this application field is particularly challenging and costly due to the need of acquiring information during the different growing stages of the cultivation of interest. In this paper, we present a method for data augmentation that uses two GANs to create artificial images to augment the training data. To obtain a higher image quality, instead of re-creating the entire scene, we take original images and replace only the patches containing objects of interest with artificial ones containing new objects with different shapes and styles. In doing this, we take into account both the foreground (i.e., crop samples) and the background (i.e., the soil) of the patches. Quantitative experiments, conducted on publicly available datasets, demonstrate the effectiveness of the proposed approach. The source code and data discussed in this work are available as open source.
M18K: A Comprehensive RGB-D Dataset and Benchmark for Mushroom Detection and Instance Segmentation
Jul 15, 2024
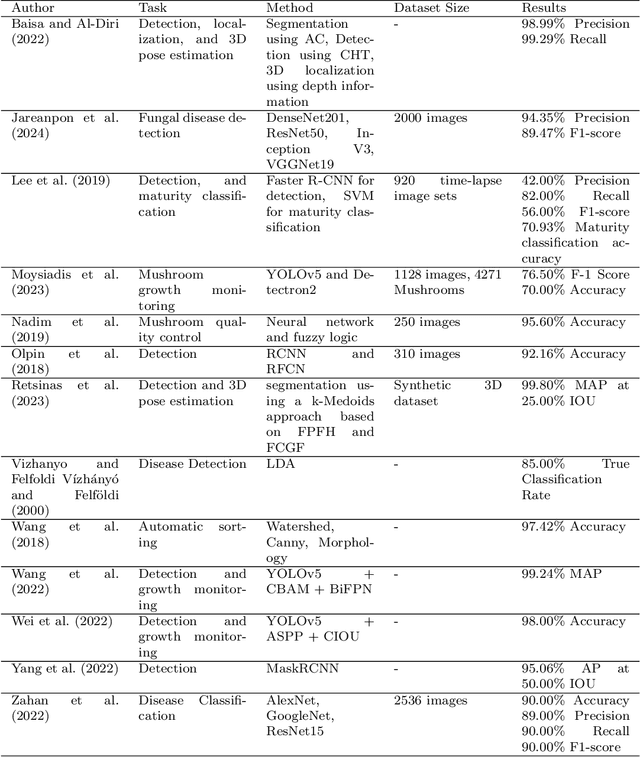
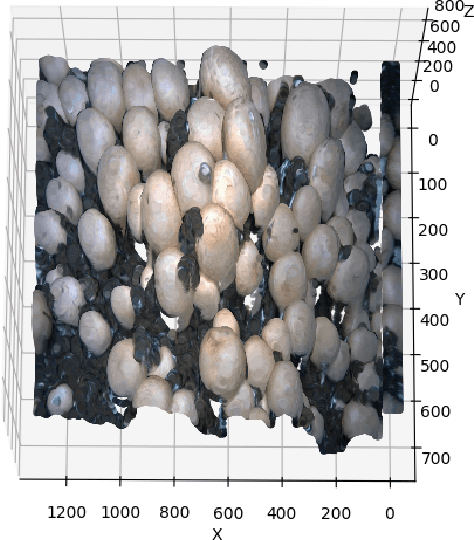
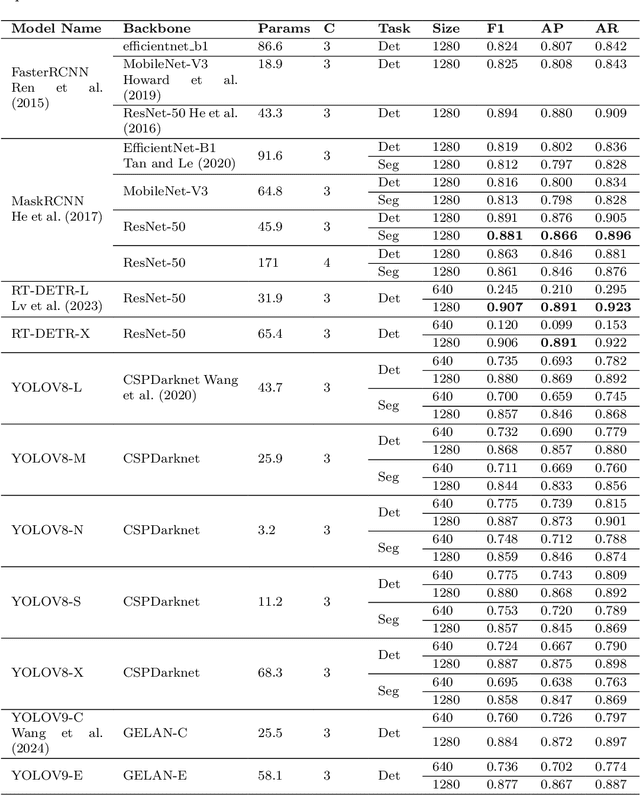
Automating agricultural processes holds significant promise for enhancing efficiency and sustainability in various farming practices. This paper contributes to the automation of agricultural processes by providing a dedicated mushroom detection dataset related to automated harvesting, growth monitoring, and quality control of the button mushroom produced using Agaricus Bisporus fungus. With over 18,000 mushroom instances in 423 RGB-D image pairs taken with an Intel RealSense D405 camera, it fills the gap in mushroom-specific datasets and serves as a benchmark for detection and instance segmentation algorithms in smart mushroom agriculture. The dataset, featuring realistic growth environment scenarios with comprehensive annotations, is assessed using advanced detection and instance segmentation algorithms. The paper details the dataset's characteristics, evaluates algorithmic performance, and for broader applicability, we have made all resources publicly available including images, codes, and trained models via our GitHub repository https://github.com/abdollahzakeri/m18k
TextAug: Test time Text Augmentation for Multimodal Person Re-identification
Dec 04, 2023



Multimodal Person Reidentification is gaining popularity in the research community due to its effectiveness compared to counter-part unimodal frameworks. However, the bottleneck for multimodal deep learning is the need for a large volume of multimodal training examples. Data augmentation techniques such as cropping, flipping, rotation, etc. are often employed in the image domain to improve the generalization of deep learning models. Augmenting in other modalities than images, such as text, is challenging and requires significant computational resources and external data sources. In this study, we investigate the effectiveness of two computer vision data augmentation techniques: cutout and cutmix, for text augmentation in multi-modal person re-identification. Our approach merges these two augmentation strategies into one strategy called CutMixOut which involves randomly removing words or sub-phrases from a sentence (Cutout) and blending parts of two or more sentences to create diverse examples (CutMix) with a certain probability assigned to each operation. This augmentation was implemented at inference time without any prior training. Our results demonstrate that the proposed technique is simple and effective in improving the performance on multiple multimodal person re-identification benchmarks.
Weakly and Semi-Supervised Detection, Segmentation and Tracking of Table Grapes with Limited and Noisy Data
Aug 27, 2022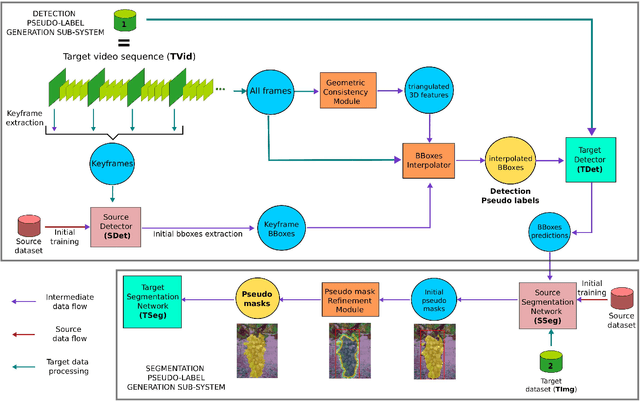

Detection, segmentation and tracking of fruits and vegetables are three fundamental tasks for precision agriculture, enabling robotic harvesting and yield estimation applications. However, modern algorithms are data hungry and it is not always possible to gather enough data to apply the best performing supervised approaches. Since data collection is an expensive and cumbersome task, the enabling technologies for using computer vision in agriculture are often out of reach for small businesses. Following previous work in this context, where we proposed an initial weakly supervised solution to reduce the data needed to get state-of-the-art detection and segmentation in precision agriculture applications, here we improve that system and explore the problem of tracking fruits in orchards. We present the case of vineyards of table grapes in southern Lazio (Italy) since grapes are a difficult fruit to segment due to occlusion, color and general illumination conditions. We consider the case when there is some initial labelled data that could work as source data (e.g. wine grape data), but it is considerably different from the target data (e.g. table grape data). To improve detection and segmentation on the target data, we propose to train the segmentation algorithm with a weak bounding box label, while for tracking we leverage 3D Structure from Motion algorithms to generate new labels from already labelled samples. Finally, the two systems are combined in a full semi-supervised approach. Comparisons with SotA supervised solutions show how our methods are able to train new models that achieve high performances with few labelled images and with very simple labelling.
Multi-Spectral Image Synthesis for Crop/Weed Segmentation in Precision Farming
Sep 12, 2020
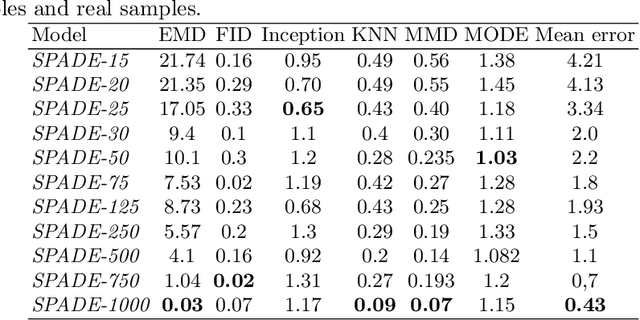
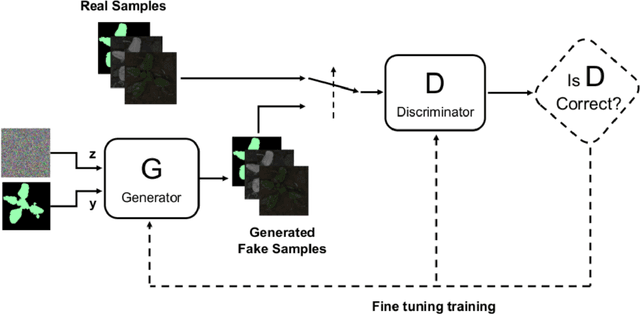
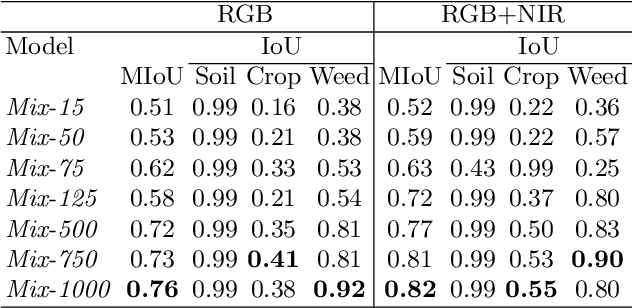
An effective perception system is a fundamental component for farming robots, as it enables them to properly perceive the surrounding environment and to carry out targeted operations. The most recent approaches make use of state-of-the-art machine learning techniques to learn an effective model for the target task. However, those methods need a large amount of labelled data for training. A recent approach to deal with this issue is data augmentation through Generative Adversarial Networks (GANs), where entire synthetic scenes are added to the training data, thus enlarging and diversifying their informative content. In this work, we propose an alternative solution with respect to the common data augmentation techniques, applying it to the fundamental problem of crop/weed segmentation in precision farming. Starting from real images, we create semi-artificial samples by replacing the most relevant object classes (i.e., crop and weeds) with their synthesized counterparts. To do that, we employ a conditional GAN (cGAN), where the generative model is trained by conditioning the shape of the generated object. Moreover, in addition to RGB data, we take into account also near-infrared (NIR) information, generating four channel multi-spectral synthetic images. Quantitative experiments, carried out on three publicly available datasets, show that (i) our model is capable of generating realistic multi-spectral images of plants and (ii) the usage of such synthetic images in the training process improves the segmentation performance of state-of-the-art semantic segmentation Convolutional Networks.