 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Efficacy of Cut-and-Paste Data Augmentation in Semantic Segmentation for Satellite Imagery
Apr 08, 2024



Satellite imagery is crucial for tasks like environmental monitoring and urban planning. Typically, it relies on semantic segmentation or Land Use Land Cover (LULC) classification to categorize each pixel. Despite the advancements brought about by Deep Neural Networks (DNNs), their performance in segmentation tasks is hindered by challenges such as limited availability of labeled data, class imbalance and the inherent variability and complexity of satellite images. In order to mitigate those issues, our study explores the effectiveness of a Cut-and-Paste augmentation technique for semantic segmentation in satellite images. We adapt this augmentation, which usually requires labeled instances, to the case of semantic segmentation. By leveraging the connected components in the semantic segmentation labels, we extract instances that are then randomly pasted during training. Using the DynamicEarthNet dataset and a U-Net model for evaluation, we found that this augmentation significantly enhances the mIoU score on the test set from 37.9 to 44.1. This finding highlights the potential of the Cut-and-Paste augmentation to improve the generalization capabilities of semantic segmentation models in satellite imagery.
AgriSORT: A Simple Online Real-time Tracking-by-Detection framework for robotics in precision agriculture
Sep 28, 2023
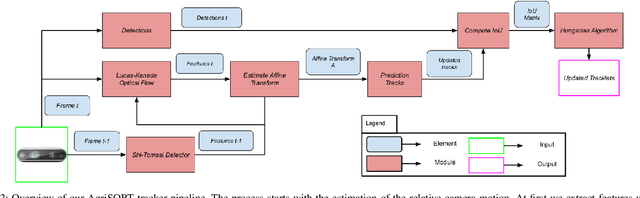


The problem of multi-object tracking (MOT) consists in detecting and tracking all the objects in a video sequence while keeping a unique identifier for each object. It is a challenging and fundamental problem for robotics. In precision agriculture the challenge of achieving a satisfactory solution is amplified by extreme camera motion, sudden illumination changes, and strong occlusions. Most modern trackers rely on the appearance of objects rather than motion for association, which can be ineffective when most targets are static objects with the same appearance, as in the agricultural case. To this end, on the trail of SORT [5], we propose AgriSORT, a simple, online, real-time tracking-by-detection pipeline for precision agriculture based only on motion information that allows for accurate and fast propagation of tracks between frames. The main focuses of AgriSORT are efficiency, flexibility, minimal dependencies, and ease of deployment on robotic platforms. We test the proposed pipeline on a novel MOT benchmark specifically tailored for the agricultural context, based on video sequences taken in a table grape vineyard, particularly challenging due to strong self-similarity and density of the instances. Both the code and the dataset are available for future comparisons.
Weakly and Semi-Supervised Detection, Segmentation and Tracking of Table Grapes with Limited and Noisy Data
Aug 27, 2022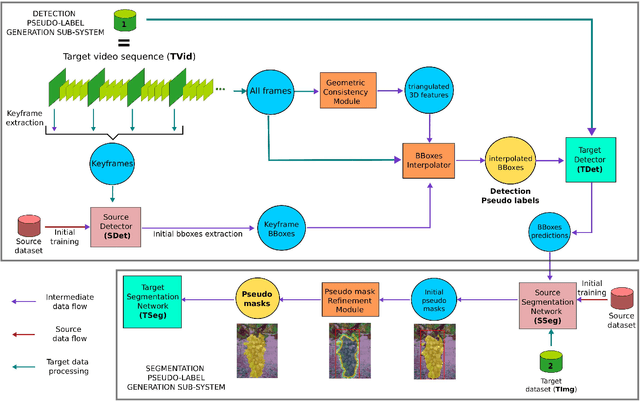

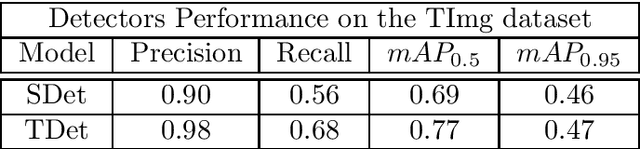
Detection, segmentation and tracking of fruits and vegetables are three fundamental tasks for precision agriculture, enabling robotic harvesting and yield estimation applications. However, modern algorithms are data hungry and it is not always possible to gather enough data to apply the best performing supervised approaches. Since data collection is an expensive and cumbersome task, the enabling technologies for using computer vision in agriculture are often out of reach for small businesses. Following previous work in this context, where we proposed an initial weakly supervised solution to reduce the data needed to get state-of-the-art detection and segmentation in precision agriculture applications, here we improve that system and explore the problem of tracking fruits in orchards. We present the case of vineyards of table grapes in southern Lazio (Italy) since grapes are a difficult fruit to segment due to occlusion, color and general illumination conditions. We consider the case when there is some initial labelled data that could work as source data (e.g. wine grape data), but it is considerably different from the target data (e.g. table grape data). To improve detection and segmentation on the target data, we propose to train the segmentation algorithm with a weak bounding box label, while for tracking we leverage 3D Structure from Motion algorithms to generate new labels from already labelled samples. Finally, the two systems are combined in a full semi-supervised approach. Comparisons with SotA supervised solutions show how our methods are able to train new models that achieve high performances with few labelled images and with very simple labelling.
The Role of the Input in Natural Language Video Description
Feb 09, 2021
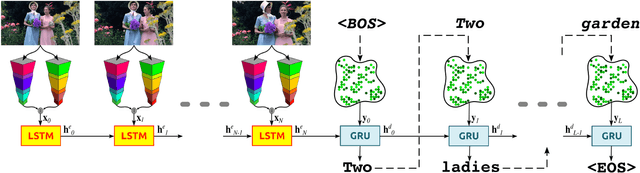


Natural Language Video Description (NLVD) has recently received strong interest in the Computer Vision, Natural Language Processing (NLP), Multimedia, and Autonomous Robotics communities. The State-of-the-Art (SotA) approaches obtained remarkable results when tested on the benchmark datasets. However, those approaches poorly generalize to new datasets. In addition, none of the existing works focus on the processing of the input to the NLVD systems, which is both visual and textual. In this work, it is presented an extensive study dealing with the role of the visual input, evaluated with respect to the overall NLP performance. This is achieved performing data augmentation of the visual component, applying common transformations to model camera distortions, noise, lighting, and camera positioning, that are typical in real-world operative scenarios. A t-SNE based analysis is proposed to evaluate the effects of the considered transformations on the overall visual data distribution. For this study, it is considered the English subset of Microsoft Research Video Description (MSVD) dataset, which is used commonly for NLVD. It was observed that this dataset contains a relevant amount of syntactic and semantic errors. These errors have been amended manually, and the new version of the dataset (called MSVD-v2) is used in the experimentation. The MSVD-v2 dataset is released to help to gain insight into the NLVD problem.
* In IEEE Transactions on Multimedia
Towards Monocular Digital Elevation Model (DEM) Estimation by Convolutional Neural Networks - Application on Synthetic Aperture Radar Images
Mar 14, 2018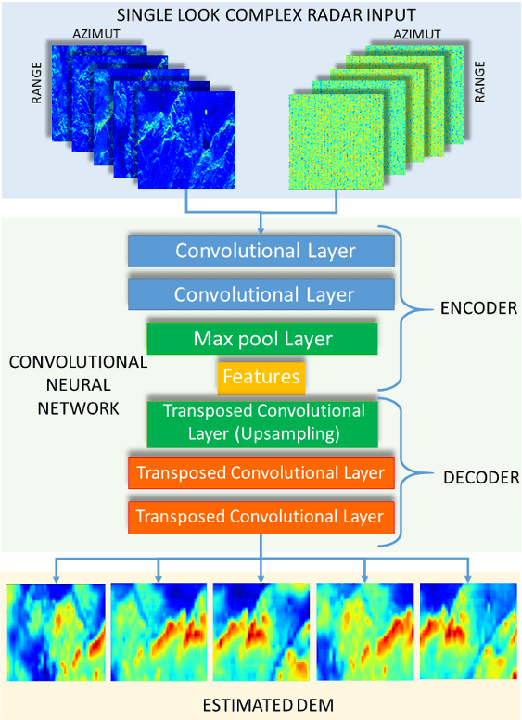
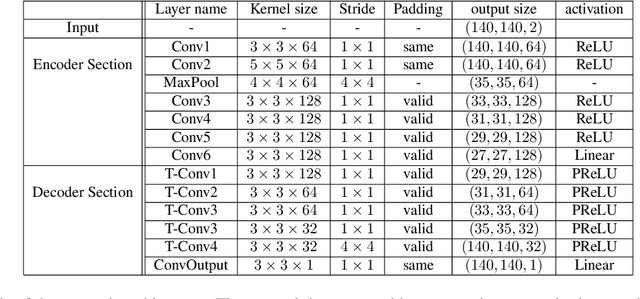
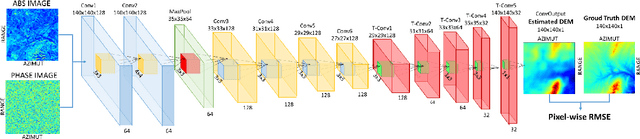

Synthetic aperture radar (SAR) interferometry (InSAR) is performed using repeat-pass geometry. InSAR technique is used to estimate the topographic reconstruction of the earth surface. The main problem of the range-Doppler focusing technique is the nature of the two-dimensional SAR result, affected by the layover indetermination. In order to resolve this problem, a minimum of two sensor acquisitions, separated by a baseline and extended in the cross-slant-range, are needed. However, given its multi-temporal nature, these techniques are vulnerable to atmosphere and Earth environment parameters variation in addition to physical platform instabilities. Furthermore, either two radars are needed or an interferometric cycle is required (that spans from days to weeks), which makes real time DEM estimation impossible. In this work, the authors propose a novel experimental alternative to the InSAR method that uses single-pass acquisitions, using a data driven approach implemented by Deep Neural Networks. We propose a fully Convolutional Neural Network (CNN) Encoder-Decoder architecture, training it on radar images in order to estimate DEMs from single pass image acquisitions. Our results on a set of Sentinel images show that this method is able to learn to some extent the statistical properties of the DEM. The results of this exploratory analysis are encouraging and open the way to the solution of single-pass DEM estimation problem with data driven approaches.
J-MOD$^{2}$: Joint Monocular Obstacle Detection and Depth Estimation
Dec 13, 2017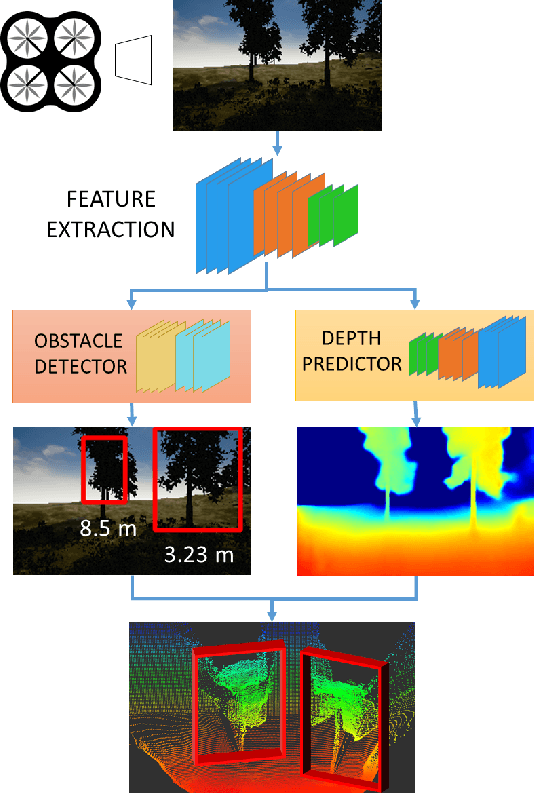
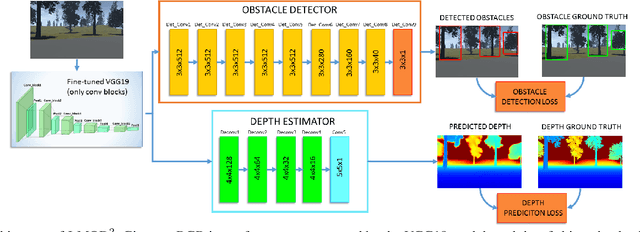
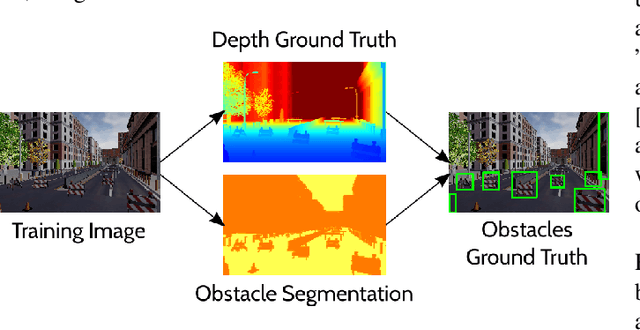
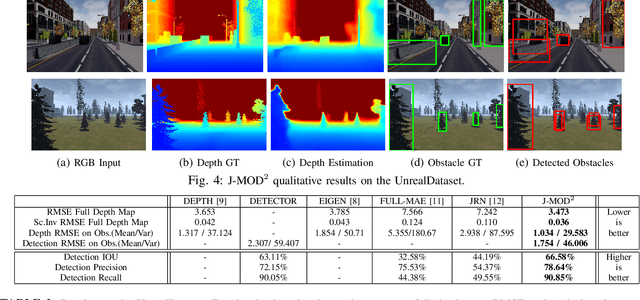
In this work, we propose an end-to-end deep architecture that jointly learns to detect obstacles and estimate their depth for MAV flight applications. Most of the existing approaches either rely on Visual SLAM systems or on depth estimation models to build 3D maps and detect obstacles. However, for the task of avoiding obstacles this level of complexity is not required. Recent works have proposed multi task architectures to both perform scene understanding and depth estimation. We follow their track and propose a specific architecture to jointly estimate depth and obstacles, without the need to compute a global map, but maintaining compatibility with a global SLAM system if needed. The network architecture is devised to exploit the joint information of the obstacle detection task, that produces more reliable bounding boxes, with the depth estimation one, increasing the robustness of both to scenario changes. We call this architecture J-MOD$^{2}$. We test the effectiveness of our approach with experiments on sequences with different appearance and focal lengths and compare it to SotA multi task methods that jointly perform semantic segmentation and depth estimation. In addition, we show the integration in a full system using a set of simulated navigation experiments where a MAV explores an unknown scenario and plans safe trajectories by using our detection model.
LS-VO: Learning Dense Optical Subspace for Robust Visual Odometry Estimation
Dec 12, 2017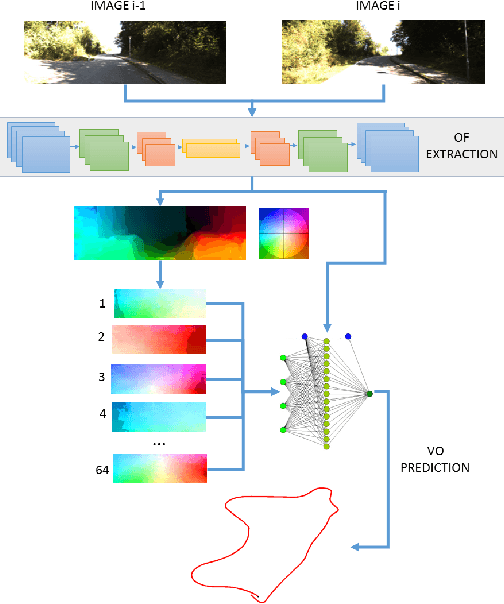
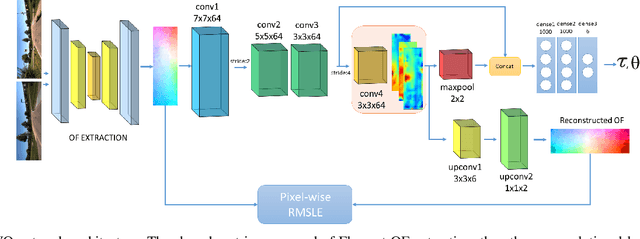


This work proposes a novel deep network architecture to solve the camera Ego-Motion estimation problem. A motion estimation network generally learns features similar to Optical Flow (OF) fields starting from sequences of images. This OF can be described by a lower dimensional latent space. Previous research has shown how to find linear approximations of this space. We propose to use an Auto-Encoder network to find a non-linear representation of the OF manifold. In addition, we propose to learn the latent space jointly with the estimation task, so that the learned OF features become a more robust description of the OF input. We call this novel architecture LS-VO. The experiments show that LS-VO achieves a considerable increase in performances in respect to baselines, while the number of parameters of the estimation network only slightly increases.
Fast Robust Monocular Depth Estimation for Obstacle Detection with Fully Convolutional Networks
Jul 21, 2016
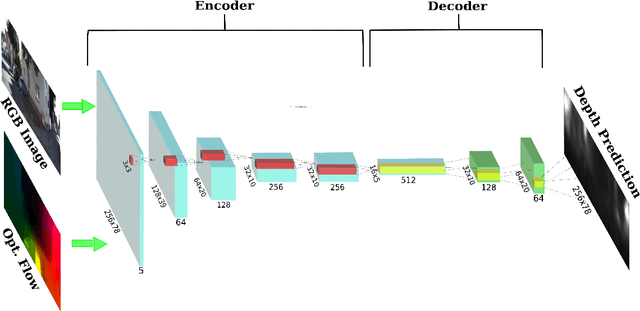


Obstacle Detection is a central problem for any robotic system, and critical for autonomous systems that travel at high speeds in unpredictable environment. This is often achieved through scene depth estimation, by various means. When fast motion is considered, the detection range must be longer enough to allow for safe avoidance and path planning. Current solutions often make assumption on the motion of the vehicle that limit their applicability, or work at very limited ranges due to intrinsic constraints. We propose a novel appearance-based Object Detection system that is able to detect obstacles at very long range and at a very high speed (~300Hz), without making assumptions on the type of motion. We achieve these results using a Deep Neural Network approach trained on real and synthetic images and trading some depth accuracy for fast, robust and consistent operation. We show how photo-realistic synthetic images are able to solve the problem of training set dimension and variety typical of machine learning approaches, and how our system is robust to massive blurring of test images.